目标
一个 「开心字符串」定义为:
- 仅包含小写字母 ['a', 'b', 'c'].
- 对所有在 1 到 s.length - 1 之间的 i ,满足 s[i] != s[i + 1] (字符串的下标从 1 开始)。
比方说,字符串 "abc","ac","b" 和 "abcbabcbcb" 都是开心字符串,但是 "aa","baa" 和 "ababbc" 都不是开心字符串。
给你两个整数 n 和 k ,你需要将长度为 n 的所有开心字符串按字典序排序。
请你返回排序后的第 k 个开心字符串,如果长度为 n 的开心字符串少于 k 个,那么请你返回 空字符串 。
示例 1:
输入:n = 1, k = 3
输出:"c"
解释:列表 ["a", "b", "c"] 包含了所有长度为 1 的开心字符串。按照字典序排序后第三个字符串为 "c" 。示例 2:
输入:n = 1, k = 4
输出:""
解释:长度为 1 的开心字符串只有 3 个。示例 3:
输入:n = 3, k = 9
输出:"cab"
解释:长度为 3 的开心字符串总共有 12 个 ["aba", "abc", "aca", "acb", "bab", "bac", "bca", "bcb", "cab", "cac", "cba", "cbc"] 。第 9 个字符串为 "cab"示例 4:
输入:n = 2, k = 7
输出:""示例 5:
输入:n = 10, k = 100
输出:"abacbabacb"说明:
- 1 <= n <= 10
- 1 <= k <= 100
思路
使用小写字母 a b c 构造相邻不重复的长度为 n 的字符串,求字典序第 k 小的字符串。
按顺序回溯构造长度为 n 的字符串,直到第 k 个结束返回。
代码
/**
* @date 2026-03-16 13:55
*/
public class GetHappyString1415 {
private char[] curChar = new char[]{'a', 'b', 'c'};
public String getHappyString(int n, int k) {
List<String> list = new ArrayList<>(k);
char[] chars = new char[n];
dfs(n, k, '-', 0, chars, list);
return list.size() < k ? "" : list.get(k - 1);
}
public void dfs(int n, int k, char prev, int l, char[] chars, List<String> list) {
if (list.size() == k) {
return;
}
if (l == n) {
list.add(new String(chars));
return;
}
for (char c : curChar) {
if (c == prev) {
continue;
}
chars[l] = c;
dfs(n, k, c, l + 1, chars, list);
}
}
}
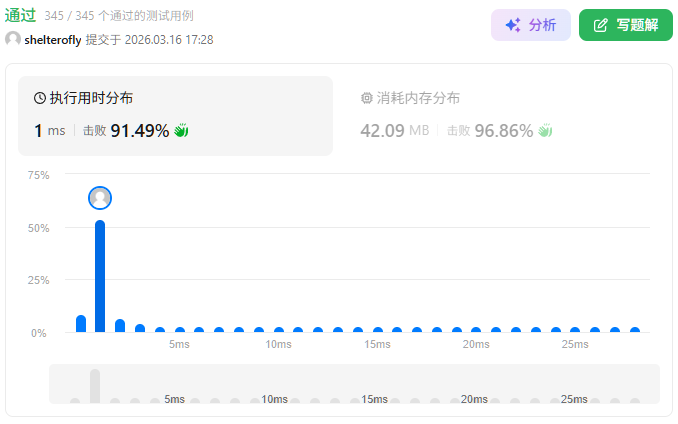
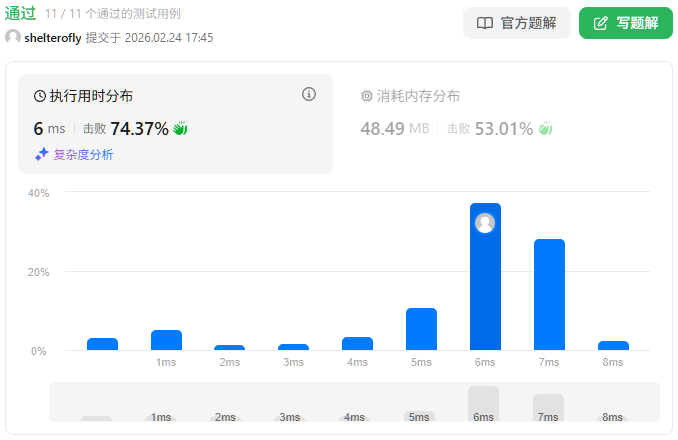
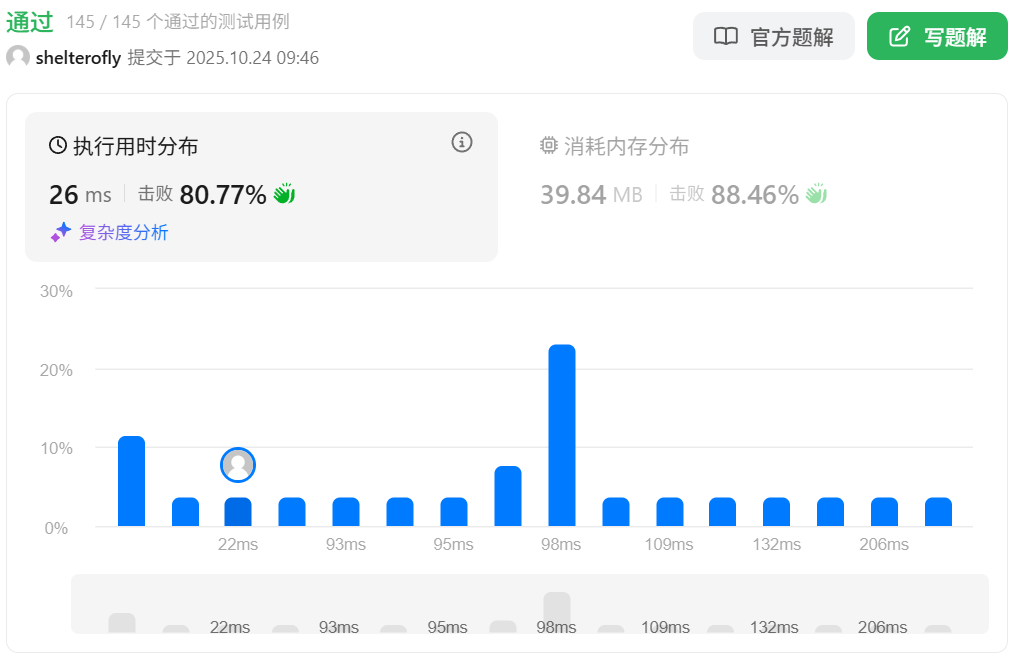
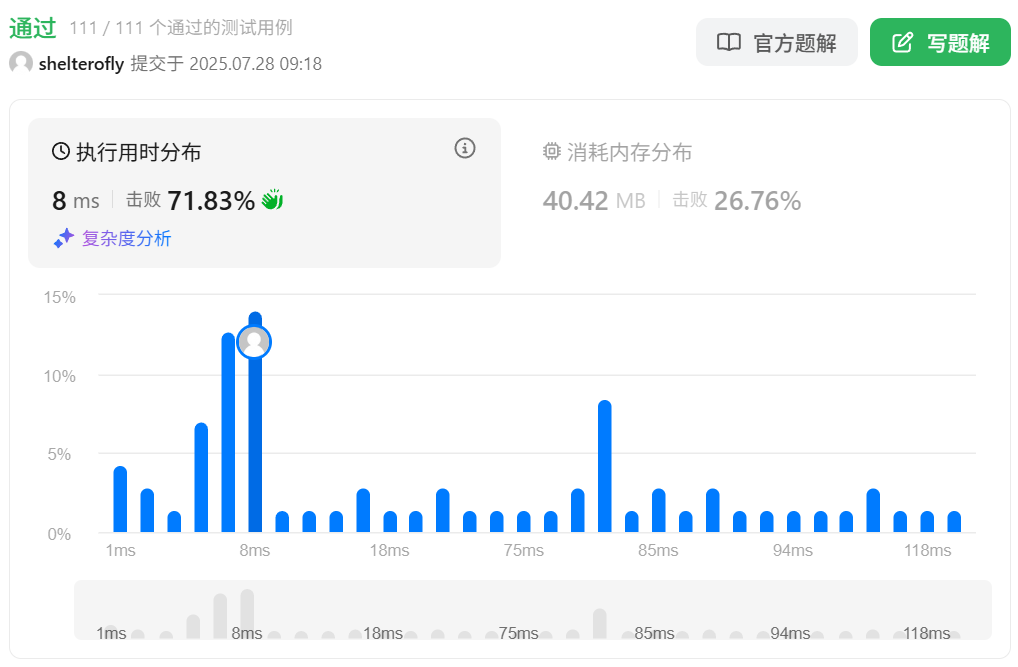
性能