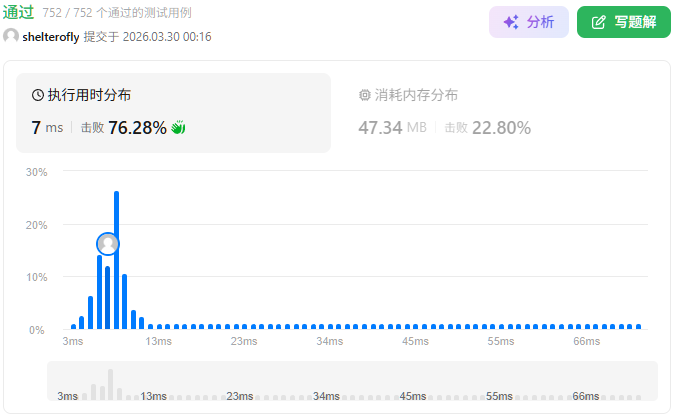
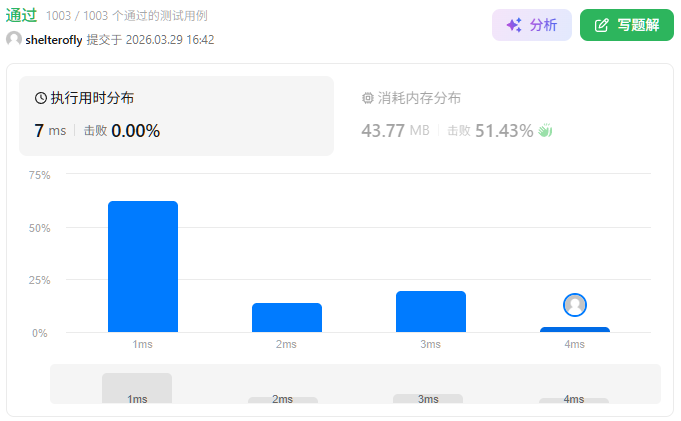
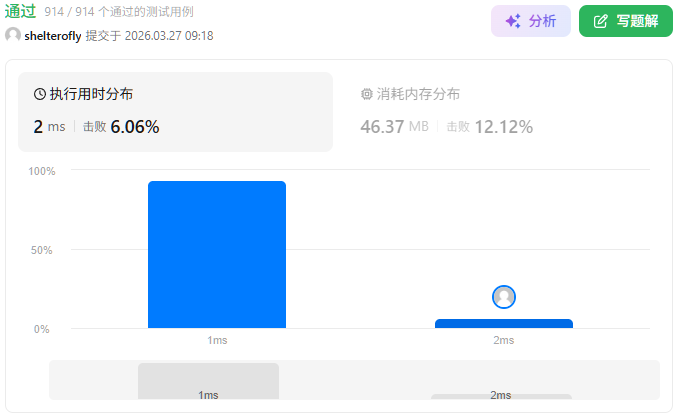
目标
给你两个字符串,str1 和 str2,其长度分别为 n 和 m 。
如果一个长度为 n + m - 1 的字符串 word 的每个下标 0 <= i <= n - 1 都满足以下条件,则称其由 str1 和 str2 生成:
- 如果 str1[i] == 'T',则长度为 m 的 子字符串(从下标 i 开始)与 str2 相等,即 word[i..(i + m - 1)] == str2。
- 如果 str1[i] == 'F',则长度为 m 的 子字符串(从下标 i 开始)与 str2 不相等,即 word[i..(i + m - 1)] != str2。
返回可以由 str1 和 str2 生成 的 字典序最小 的字符串。如果不存在满足条件的字符串,返回空字符串 ""。
如果字符串 a 在第一个不同字符的位置上比字符串 b 的对应字符在字母表中更靠前,则称字符串 a 的 字典序 小于 字符串 b。
如果前 min(a.length, b.length) 个字符都相同,则较短的字符串字典序更小。
子字符串 是字符串中的一个连续、非空 的字符序列。
示例 1:
输入: str1 = "TFTF", str2 = "ab"
输出: "ababa"
解释:
下表展示了字符串 "ababa" 的生成过程:
下标 T/F 长度为 m 的子字符串
0 'T' "ab"
1 'F' "ba"
2 'T' "ab"
3 'F' "ba"
字符串 "ababa" 和 "ababb" 都可以由 str1 和 str2 生成。
返回 "ababa",因为它的字典序更小。示例 2:
输入: str1 = "TFTF", str2 = "abc"
输出: ""
解释:
无法生成满足条件的字符串。示例 3:
输入: str1 = "F", str2 = "d"
输出: "a"说明:
- 1 <= n == str1.length <= 10^4
- 1 <= m == str2.length <= 500
- str1 仅由 'T' 或 'F' 组成。
- str2 仅由小写英文字母组成。
思路
有两个字符串 str1 和 str2,长度分别为 n 和 m。对于长度为 n + m - 1 的字符串 word,如果对于每一个位置 i 都满足以下条件,则称其由 str1 和 str2 生成:
- 如果
str1[i] == T,那么从i开始长度为m的子串word[i ~ i + m - 1]与str2相同。 - 如果
str1[i] == F,那么从i开始长度为m的子串word[i ~ i + m - 1]与str2不同。
返回由 str1 和 str2 生成的字典序最小的字符串,如果无法生成返回空字符。
// todo
代码