目标
给你一个长度为 n 的 正 整数数组 nums 。
如果两个 非负 整数数组 (arr1, arr2) 满足以下条件,我们称它们是 单调 数组对:
- 两个数组的长度都是 n 。
- arr1 是单调 非递减 的,换句话说 arr1[0] <= arr1[1] <= ... <= arr1[n - 1] 。
- arr2 是单调 非递增 的,换句话说 arr2[0] >= arr2[1] >= ... >= arr2[n - 1] 。
- 对于所有的 0 <= i <= n - 1 都有 arr1[i] + arr2[i] == nums[i] 。
请你返回所有 单调 数组对的数目。
由于答案可能很大,请你将它对 10^9 + 7 取余 后返回。
示例 1:
输入:nums = [2,3,2]
输出:4
解释:
单调数组对包括:
([0, 1, 1], [2, 2, 1])
([0, 1, 2], [2, 2, 0])
([0, 2, 2], [2, 1, 0])
([1, 2, 2], [1, 1, 0])示例 2:
输入:nums = [5,5,5,5]
输出:126说明:
- 1 <= n == nums.length <= 2000
- 1 <= nums[i] <= 50
提示:
- Let
dp[i][s]is the number of monotonic pairs of length i with the arr1[i - 1] = s. - If arr1[i - 1] = s, arr2[i - 1] = nums[i - 1] - s.
- Check if the state in recurrence is valid.
思路
有一个长度为 n 的正整数数组 nums,可以将其拆成两个数组 arr1 arr2,使之满足 arr1[i] + arr2[i] == nums[i]。问 有多少种拆分方法使得 arr1 非递减 且 arr2 非递增。
显然 arr1 确定之后,arr2 也就确定了。考虑枚举 arr1,判断 arr1 是否非递减, 以及arr2 是否非递增。可以使用记忆化搜索,对于位置 i,arr1 与 arr2 需要满足下面的条件:
arr1[i] >= arr1[i - 1]arr2[i] = nums[i] - arr1[i] <= arr2[i - 1] = nums[i - 1] - arr1[i - 1],即arr1[i] >= nums[i] - nums[i - 1] + arr1[i - 1]
也就是 nums[i] >= arr1[i] >= Math.max(nums[i] - nums[i - 1] + arr1[i - 1], arr1[i - 1])。
代码
/**
* @date 2024-11-28 10:36
*/
public class CountOfPairs3250 {
public static int MOD = 1000000007;
public int countOfPairs(int[] nums) {
int res = 0;
int n = nums.length;
int[][] mem = new int[n + 1][51];
for (int[] arr : mem) {
Arrays.fill(arr, -1);
}
for (int i = 0; i <= nums[0]; i++) {
res = (res + dfs(nums, 1, i, mem)) % MOD;
}
return res;
}
public int dfs(int[] nums, int i, int prev, int[][] mem) {
int n = nums.length;
if (i == n) {
return 1;
}
int lowerBound = Math.max(prev, nums[i] - nums[i - 1] + prev);
int next = i + 1;
int res = 0;
for (int j = lowerBound; j <= nums[i]; j++) {
if (mem[next][j] == -1) {
mem[next][j] = dfs(nums, next, j, mem) % MOD;
}
res = (res + mem[next][j]) % MOD;
}
return res;
}
}
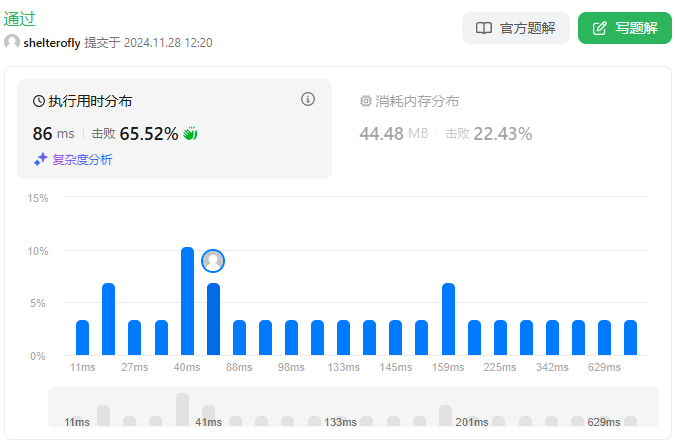
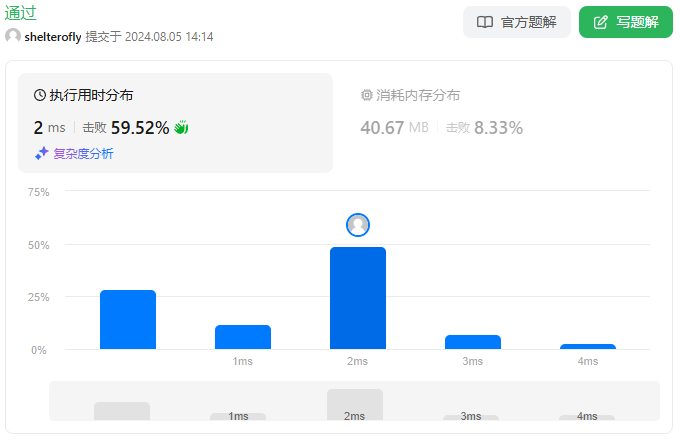
性能