目标
在第 1 天,有一个人发现了一个秘密。
给你一个整数 delay ,表示每个人会在发现秘密后的 delay 天之后,每天 给一个新的人 分享 秘密。同时给你一个整数 forget ,表示每个人在发现秘密 forget 天之后会 忘记 这个秘密。一个人 不能 在忘记秘密那一天及之后的日子里分享秘密。
给你一个整数 n ,请你返回在第 n 天结束时,知道秘密的人数。由于答案可能会很大,请你将结果对 10^9 + 7 取余 后返回。
示例 1:
输入:n = 6, delay = 2, forget = 4
输出:5
解释:
第 1 天:假设第一个人叫 A 。(一个人知道秘密)
第 2 天:A 是唯一一个知道秘密的人。(一个人知道秘密)
第 3 天:A 把秘密分享给 B 。(两个人知道秘密)
第 4 天:A 把秘密分享给一个新的人 C 。(三个人知道秘密)
第 5 天:A 忘记了秘密,B 把秘密分享给一个新的人 D 。(三个人知道秘密)
第 6 天:B 把秘密分享给 E,C 把秘密分享给 F 。(五个人知道秘密)示例 2:
输入:n = 4, delay = 1, forget = 3
输出:6
解释:
第 1 天:第一个知道秘密的人为 A 。(一个人知道秘密)
第 2 天:A 把秘密分享给 B 。(两个人知道秘密)
第 3 天:A 和 B 把秘密分享给 2 个新的人 C 和 D 。(四个人知道秘密)
第 4 天:A 忘记了秘密,B、C、D 分别分享给 3 个新的人。(六个人知道秘密)说明:
- 2 <= n <= 1000
- 1 <= delay < forget <= n
思路
在第 1 天有一个人发现了一个秘密,每一个新知道秘密的人在 delay 天之后的 每一天 会向一个 新人 分享这个秘密,每一个人在知道秘密之后的 forget 天会忘记秘密,求第 n 天结束时知道秘密的人数。
定义 dp[i] 表示在第 i 天 新增 知道秘密的人数,它等于超过了延迟 delay 并且还没有忘记的人数总和,也即 [i - forget + 1, i - delay] 之间的新增人数总和,求和可以使用前缀和优化。
代码
/**
* @date 2025-09-09 8:57
*/
public class PeopleAwareOfSecret2327 {
public int peopleAwareOfSecret(int n, int delay, int forget) {
int[] dp = new int[n + 1];
int mod = 1000000007;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
for (int j = Math.max(0, i - forget + 1); j <= Math.max(0, i - delay); j++) {
dp[i] = (dp[i] + dp[j]) % mod;
}
}
int res = 0;
for (int i = Math.max(0, n - forget + 1); i <= n; i++) {
res = (res + dp[i]) % mod;
}
return res;
}
}
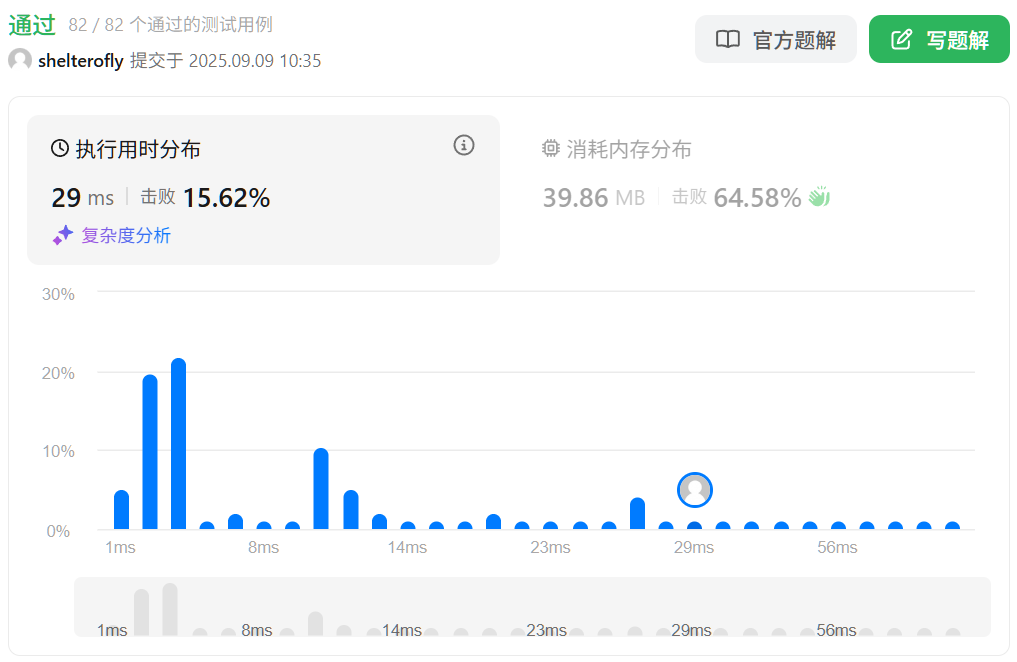
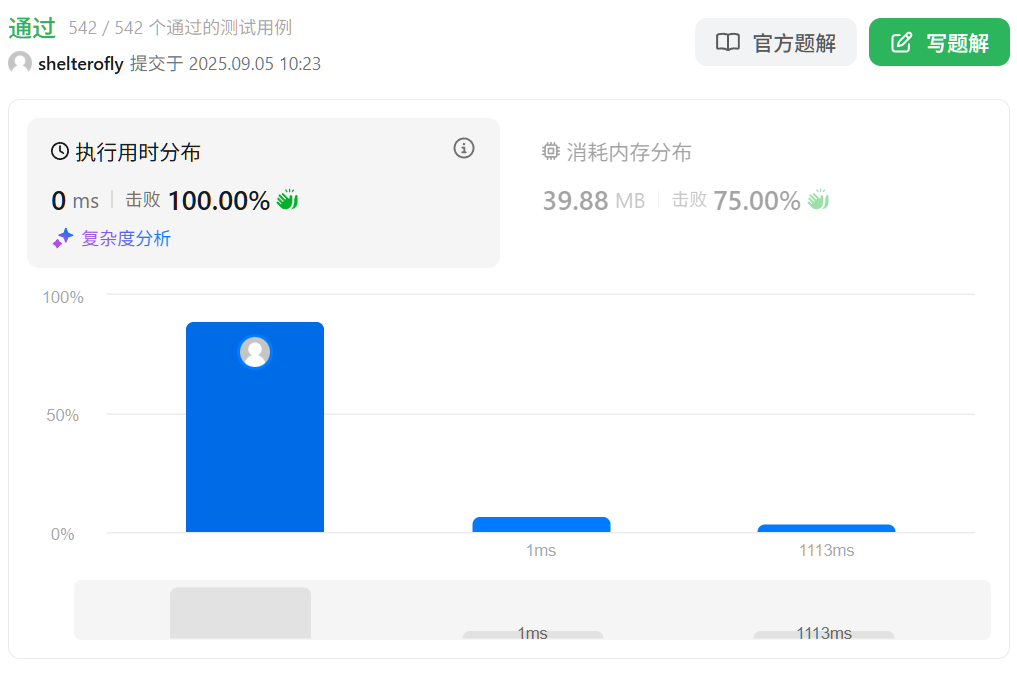
性能