目标
给定一个三角形 triangle ,找出自顶向下的最小路径和。
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
示例 1:
输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]]
输出:11
解释:如下面简图所示:
2
3 4
6 5 7
4 1 8 3
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。示例 2:
输入:triangle = [[-10]]
输出:-10说明:
- 1 <= triangle.length <= 200
- triangle[0].length == 1
- triangle[i].length == triangle[i - 1].length + 1
-10^4 <= triangle[i][j] <= 10^4
进阶:
你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题吗?
思路
有一个由多行数字排列组成的三角形,每一行比上一行多一个数字,当前数字可以到达下一行下标相同或者下标 +1 的两个数字,求从第一行到最后一行的路径中数字和的最小值。
定义 dp[i][j] 表示从第 i 行 j 列到达底部的最小路径和。dp[i][j] = Math.min(dp[i + 1][j], dp[i + 1][j + 1]) + row[i][j]。
代码
/**
* @date 2024-08-06 15:42
*/
public class MinimumTotal120 {
public int minimumTotal_new(List<List<Integer>> triangle) {
int n = triangle.size();
int m = triangle.get(n - 1).size();
int[] dp = new int[m];
for (int i = 0; i < m; i++) {
dp[i] = triangle.get(n - 1).get(i);
}
for (int i = n - 2; i >= 0; i--) {
List<Integer> row = triangle.get(i);
int l = row.size();
for (int j = 0; j < l; j++) {
dp[j] = Math.min(dp[j], dp[j + 1]) + row.get(j);
}
}
return dp[0];
}
}
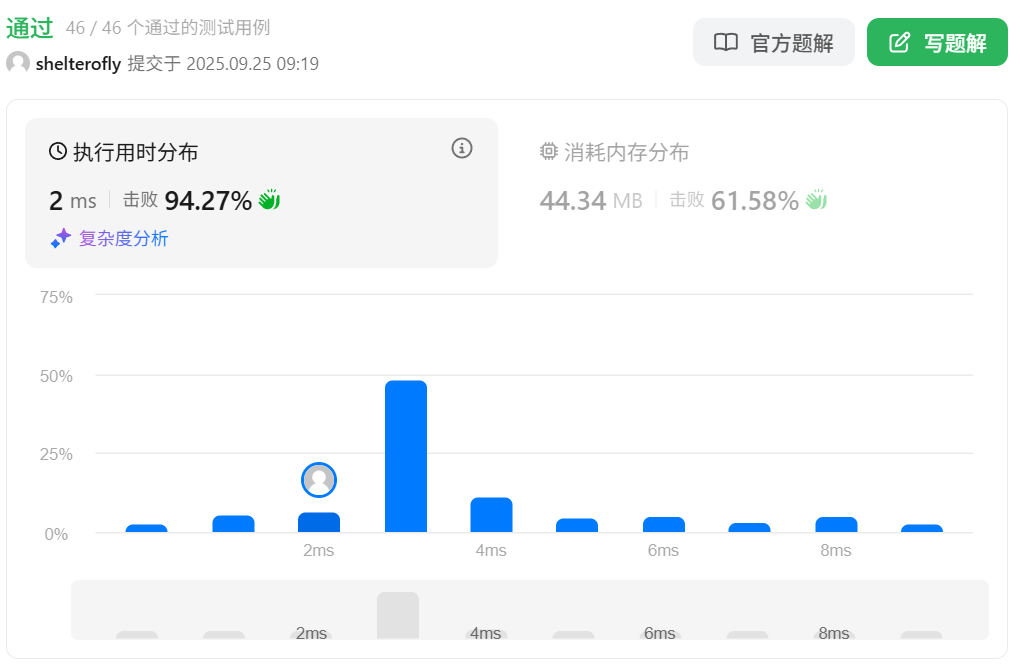
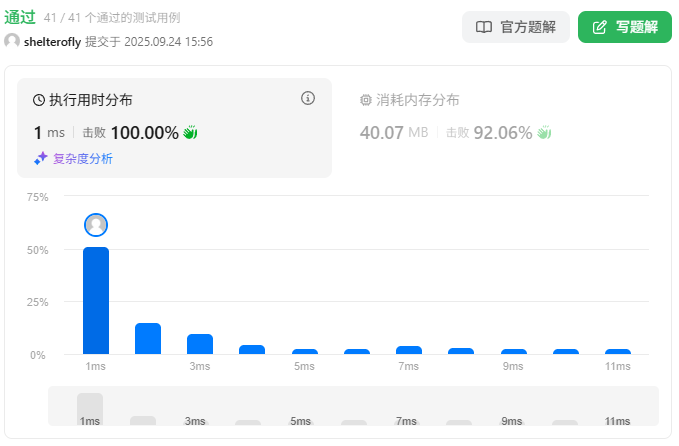
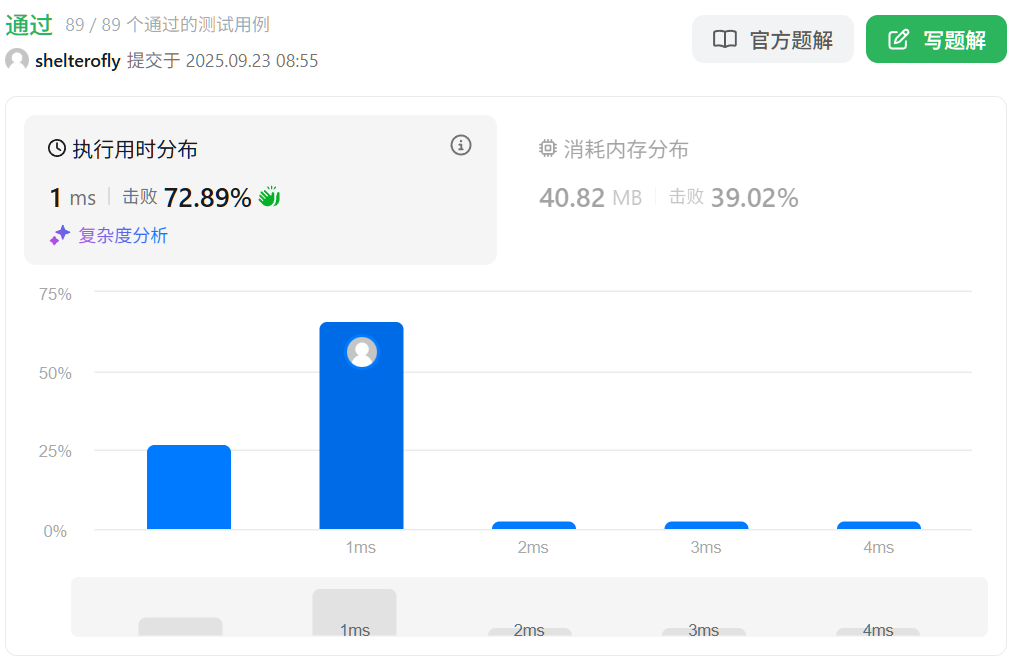
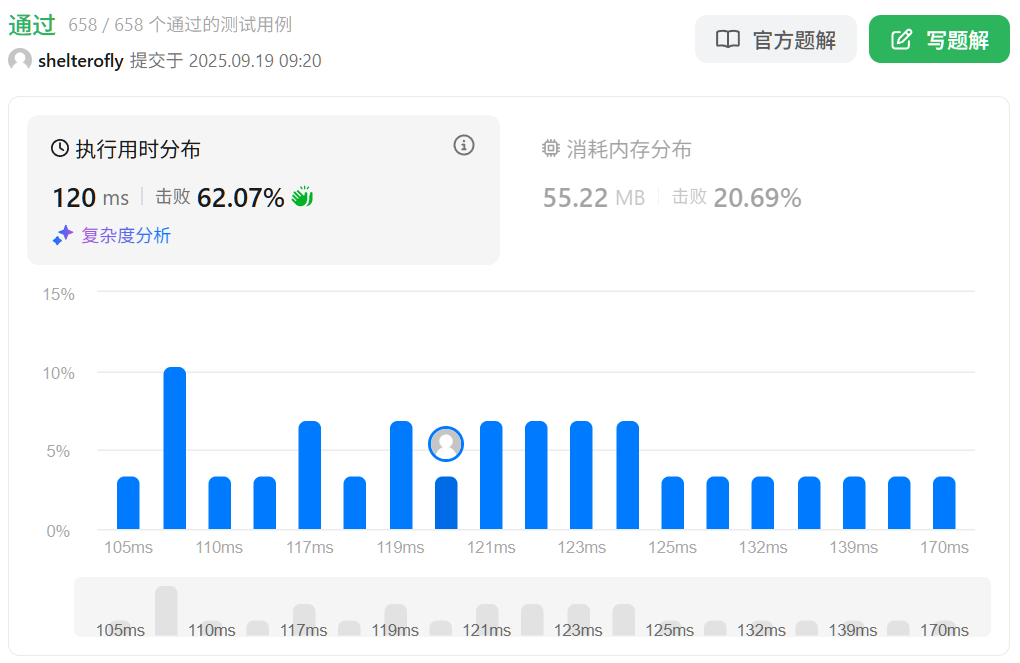
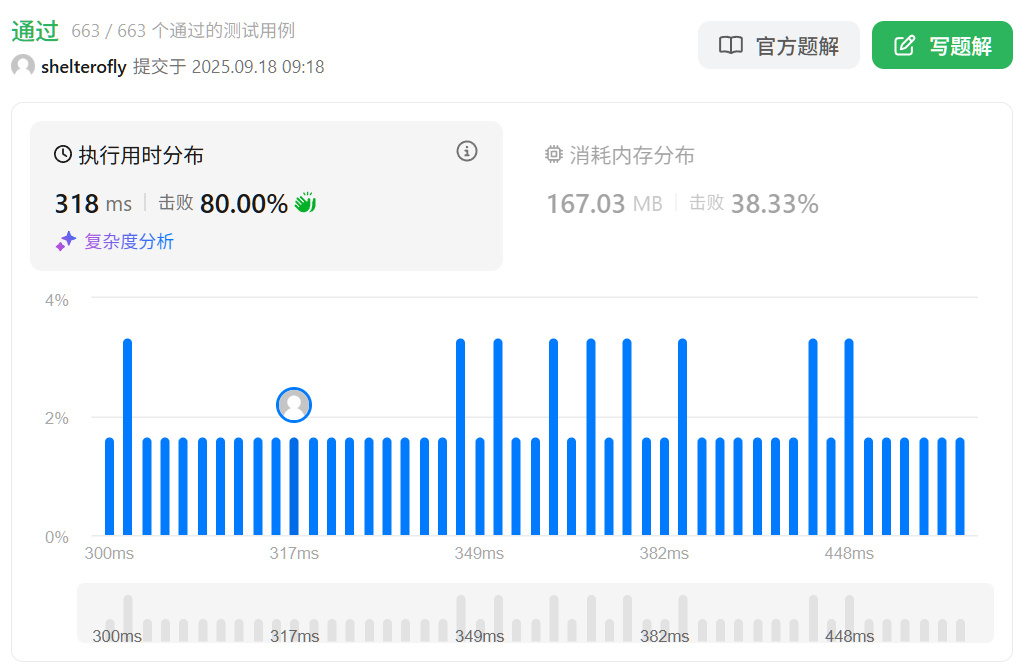
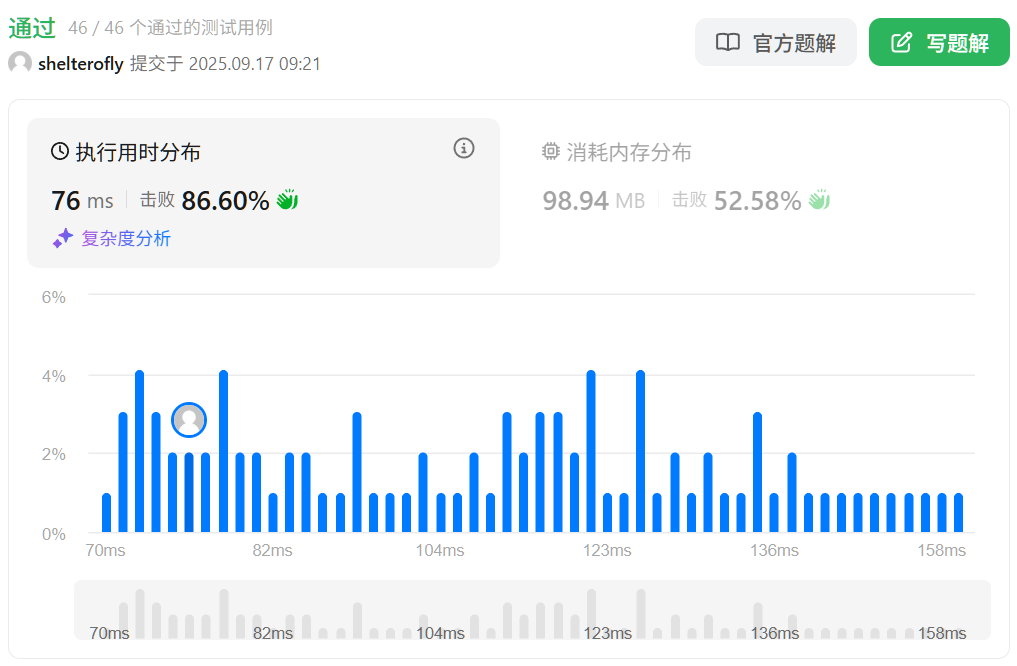
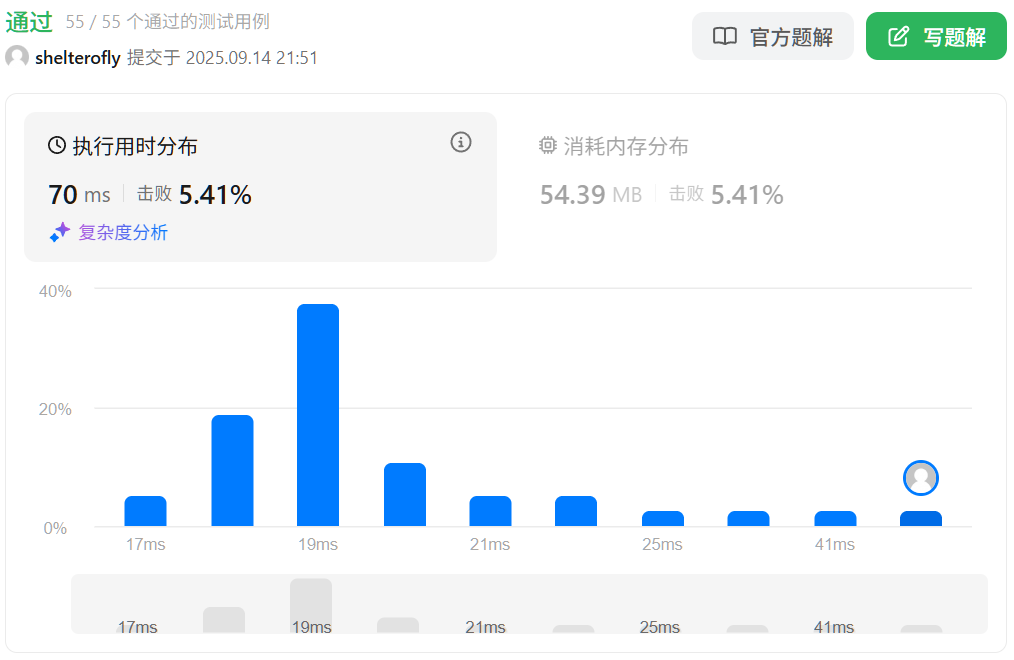
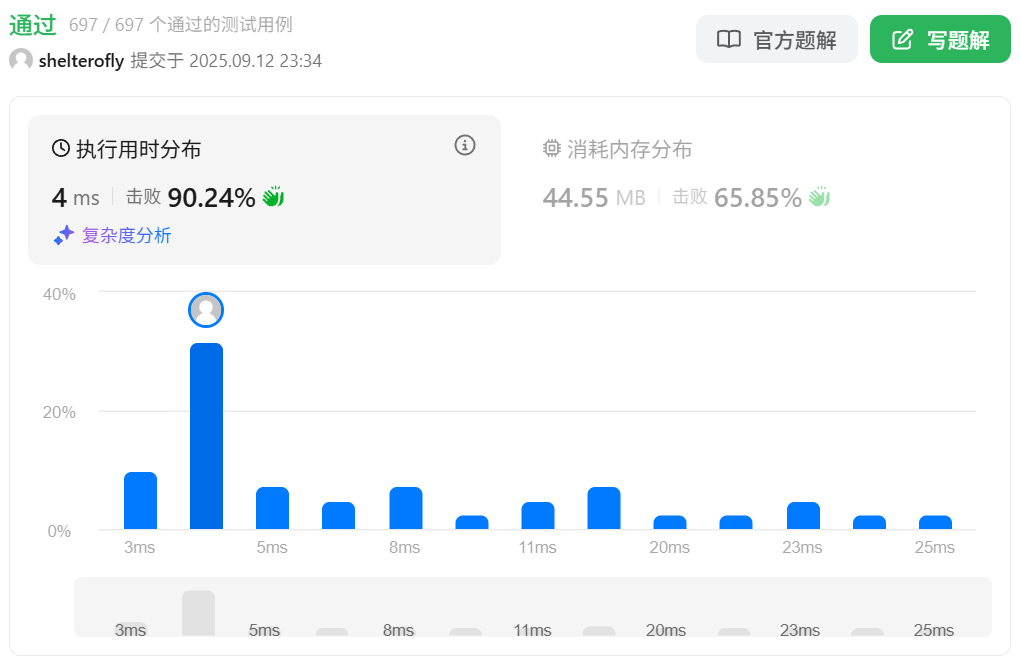
性能