目标
给你一个整数数组 nums 和一个整数 k。
你可以对数组中的每个元素 最多 执行 一次 以下操作:
- 将一个在范围 [-k, k] 内的整数加到该元素上。
返回执行这些操作后,nums 中可能拥有的不同元素的 最大 数量。
示例 1:
输入: nums = [1,2,2,3,3,4], k = 2
输出: 6
解释:
对前四个元素执行操作,nums 变为 [-1, 0, 1, 2, 3, 4],可以获得 6 个不同的元素。示例 2:
输入: nums = [4,4,4,4], k = 1
输出: 3
解释:
对 nums[0] 加 -1,以及对 nums[1] 加 1,nums 变为 [3, 5, 4, 4],可以获得 3 个不同的元素。说明:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^9
- 0 <= k <= 10^9
思路
有一个整数数组 nums,允许对数组中的每个元素加上 [-k, k] 的整数,求操作后数组中不同元素的最大个数。
先对数组进行排序,计算相同元素个数,同时记录前一个元素操作后的最大值 + 1,当前相同元素的个数可以操作变成不同元素的范围是 [Math.max(nums[start] - k, prev), Math.min(nums[start] + k, l + cnt - 1)]。
代码
/**
* @date 2025-10-20 10:09
*/
public class MaxDistinctElements3397 {
public int maxDistinctElements(int[] nums, int k) {
int n = nums.length;
int i = 0;
int prev = Integer.MIN_VALUE;
int res = 0;
Arrays.sort(nums);
while (i < n) {
int start = i;
while (i < n && nums[i] == nums[start]) {
i++;
}
int cnt = i - start;
int l = Math.max(nums[start] - k, prev);
int r = Math.min(nums[start] + k, l + cnt - 1);
res += r - l + 1;
prev = r + 1;
}
return res;
}
}
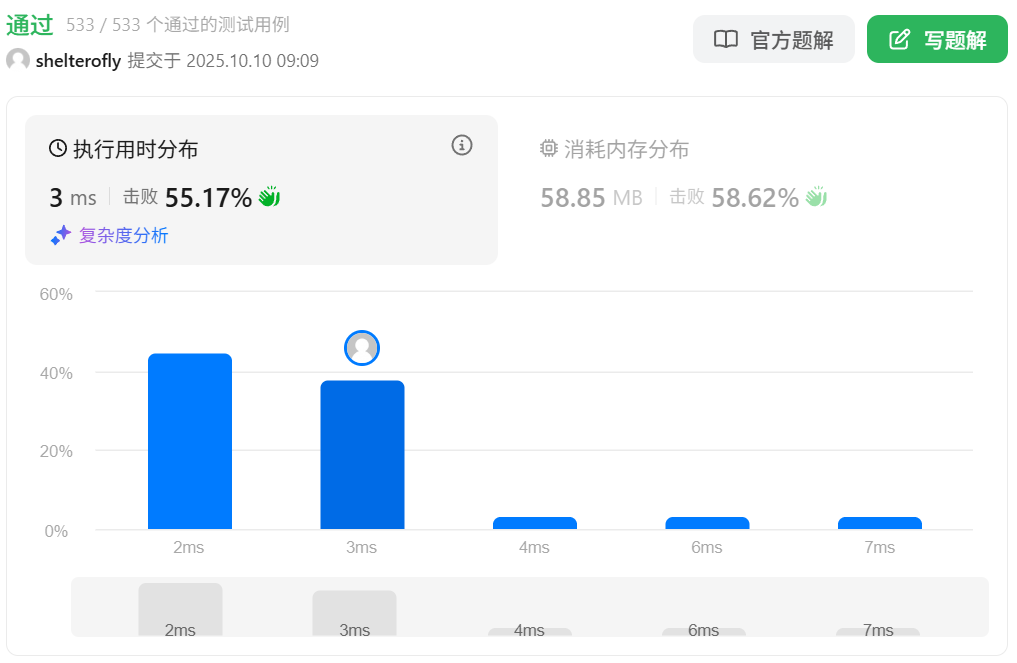
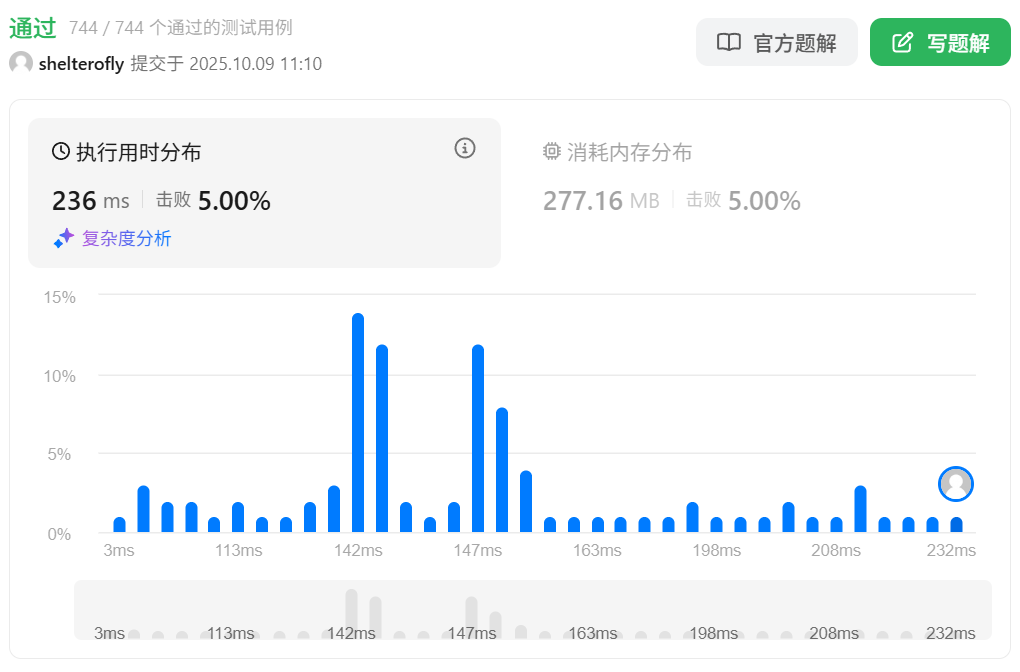
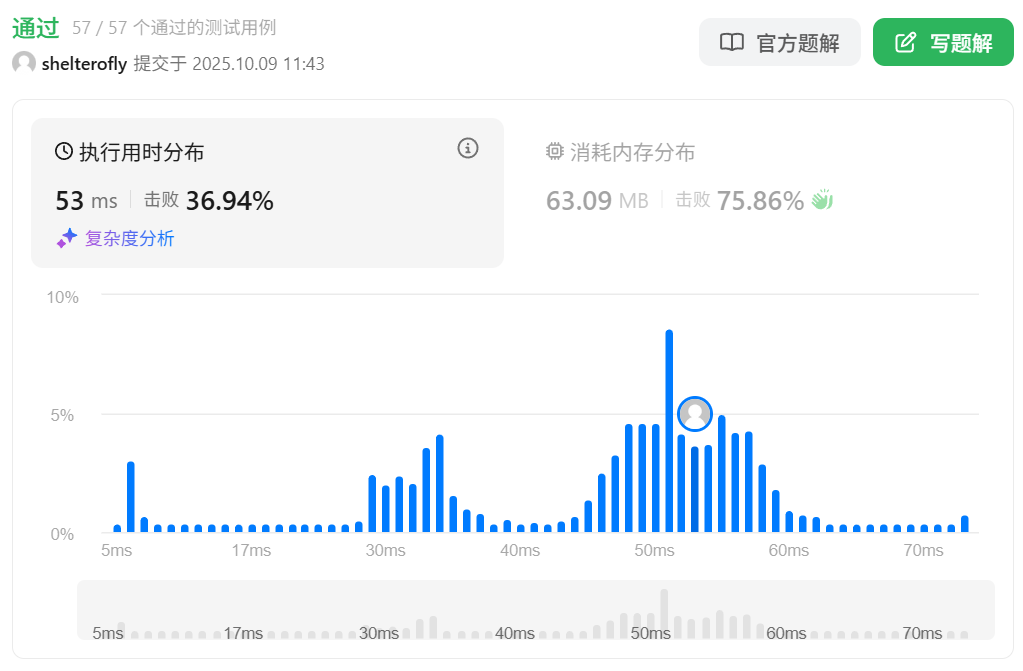
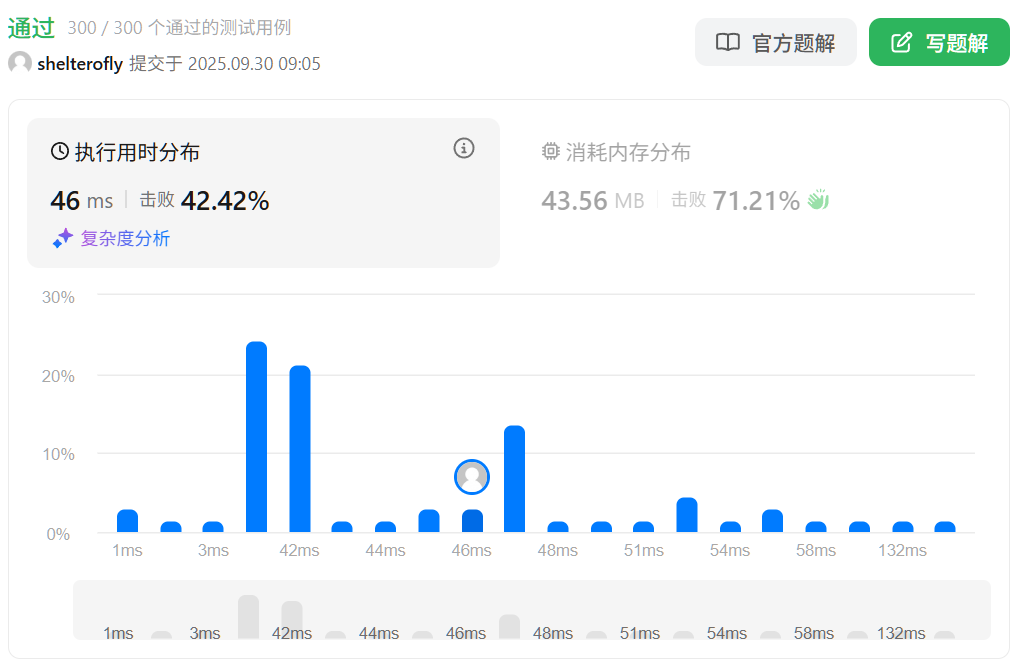
性能