目标
给你一个正整数数组 values,其中 values[i] 表示第 i 个观光景点的评分,并且两个景点 i 和 j 之间的 距离 为 j - i。
一对景点(i < j)组成的观光组合的得分为 values[i] + values[j] + i - j ,也就是景点的评分之和 减去 它们两者之间的距离。
返回一对观光景点能取得的最高分。
示例 1:
输入:values = [8,1,5,2,6]
输出:11
解释:i = 0, j = 2, values[i] + values[j] + i - j = 8 + 5 + 0 - 2 = 11示例 2:
输入:values = [1,2]
输出:2说明:
- 2 <= values.length <= 5 * 10^4
- 1 <= values[i] <= 1000
思路
从数组 values 中选两个下标,计算 values[i] + values[j] + i - j 的最大值。
遍历可能组合的复杂度为 O(n^2),暴力求解不可行。很自然地想动态规划,考虑重复子问题是什么?如果是累加 i ~ j 范围内的 value,然后再加上 i - j,由于 value[i] >= 1,当 j 固定的时候,i 应该尽可能的小,因为累加 value[i] 抵消了 i 的减少。但这里并不是累加所有景点的评分,而是选两个景点,然后再考虑它们之间的距离。
注意到,当 j 固定时,评分的最大值即为 value[i] + i 的最大值。当 i 固定时,评分最大值为 values[j] - j 的最大值。但是我们不能直接取这两个最大值相加,需要保证 i 取得最大值时,i < j。枚举右边界,计算之前的最大值。
定义 dp[i] 表示 [0, i] 范围内, value[i] + i 的最大值。那么评分的最大值即为 value[j] - j + dp[j - 1] 的最大值。由于只与 dp[j - 1] 有关,可以进行空间优化,用一个变量保存截止到前一个元素的最大值。
这里面有一个小技巧是将 maxi 放到后面更新,这样就不用维护 i = j - 1 这个指针了。
代码
/**
* @date 2024-09-23 9:26
*/
public class MaxScoreSightseeingPair1014 {
public int maxScoreSightseeingPair(int[] values) {
int n = values.length;
int maxi = values[0];
int res = 0;
for (int j = 1; j < n; j++) {
res = Math.max(res, values[j] - j + maxi);
maxi = Math.max(maxi, values[j] + j);
}
return res;
}
}
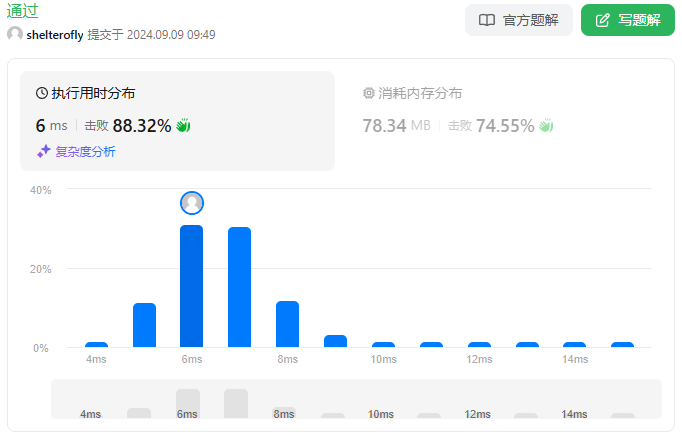
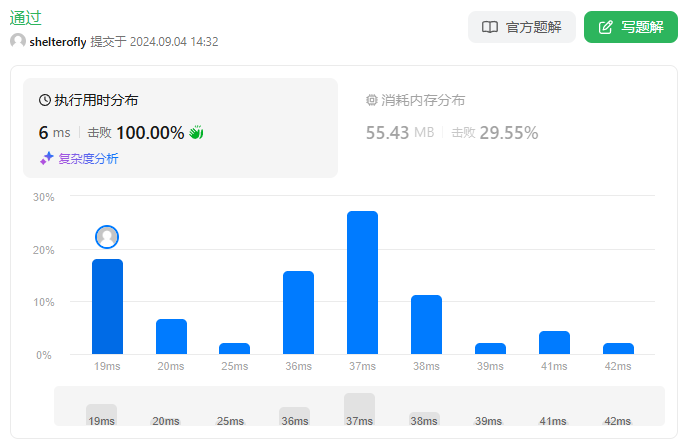
性能