目标
给你一个字符串 s ,它由某个字符串 t 和若干 t 的 同位字符串 连接而成。
请你返回字符串 t 的 最小 可能长度。
同位字符串 指的是重新排列一个单词得到的另外一个字符串,原来字符串中的每个字符在新字符串中都恰好只使用一次。
示例 1:
输入:s = "abba"
输出:2
解释:
一个可能的字符串 t 为 "ba" 。示例 2:
输入:s = "cdef"
输出:4
解释:
一个可能的字符串 t 为 "cdef" ,注意 t 可能等于 s 。说明:
- 1 <= s.length <= 10^5
- s 只包含小写英文字母。
思路
字符串 s 由某个字符串 t 以及若干(可以为0) t 的同位字符串 连接 而成,返回字符串 t 最小的可能长度。同位字符串指构成字符串的字符分布完全相同,换句话说就是不同字符的种类与数量完全相同。
特别注意该题与字串的顺序有关,比如 aabb 并不能由 ab 拼接而来,它的同位字符串是 ab 和 ba,只能构成 abba abab baab baba。
注意到子串的长度 length 一定能够被 s.length 整除。将字符串截成 k 个长度为 length 的子字符串,通过计算这些子字符串的字母个数,判断是否是同位字符串,从小到大遍历因数 length,取最小的即可。
代码
/**
* @date 2024-12-20 9:08
*/
public class MinAnagramLength3138 {
public int minAnagramLength_v1(String s) {
int n = s.length();
int[] cnt = new int[26];
Map<Integer, int[]> possibleLength = new LinkedHashMap<>();
for (int i = 0; i < n; i++) {
int c = s.charAt(i) - 'a';
cnt[c]++;
int length = i + 1;
if (n % length == 0) {
int[] composition = new int[26];
System.arraycopy(cnt, 0, composition, 0, 26);
possibleLength.put(length, composition);
}
}
char[] chars = s.toCharArray();
for (Map.Entry<Integer, int[]> entry : possibleLength.entrySet()) {
int length = entry.getKey();
if (length == n) {
return n;
}
int[] composition = entry.getValue();
int loop = n / length;
boolean find = true;
here:
for (int i = 0; i < loop; i++) {
int[] tmp = new int[26];
System.arraycopy(composition, 0, tmp, 0, 26);
for (int j = 0; j < length; j++) {
int c = chars[i * length + j] - 'a';
tmp[c]--;
if (tmp[c] < 0) {
find = false;
break here;
}
}
}
if (find) {
return length;
}
}
return n;
}
}
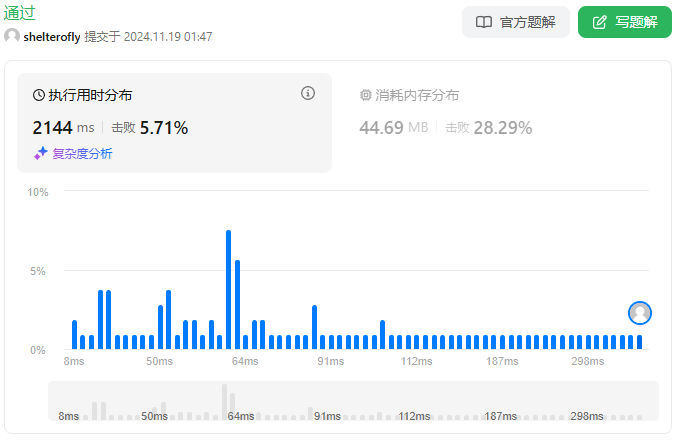
性能