目标
有 3n 堆数目不一的硬币,你和你的朋友们打算按以下方式分硬币:
- 每一轮中,你将会选出 任意 3 堆硬币(不一定连续)。
- Alice 将会取走硬币数量最多的那一堆。
- 你将会取走硬币数量第二多的那一堆。
- Bob 将会取走最后一堆。
- 重复这个过程,直到没有更多硬币。
给你一个整数数组 piles ,其中 piles[i] 是第 i 堆中硬币的数目。
返回你可以获得的最大硬币数目。
示例 1:
输入:piles = [2,4,1,2,7,8]
输出:9
解释:选出 (2, 7, 8) ,Alice 取走 8 枚硬币的那堆,你取走 7 枚硬币的那堆,Bob 取走最后一堆。
选出 (1, 2, 4) , Alice 取走 4 枚硬币的那堆,你取走 2 枚硬币的那堆,Bob 取走最后一堆。
你可以获得的最大硬币数目:7 + 2 = 9.
考虑另外一种情况,如果选出的是 (1, 2, 8) 和 (2, 4, 7) ,你就只能得到 2 + 4 = 6 枚硬币,这不是最优解。示例 2:
输入:piles = [2,4,5]
输出:4示例 3:
输入:piles = [9,8,7,6,5,1,2,3,4]
输出:18说明:
- 3 <= piles.length <= 10^5
- piles.length % 3 == 0
- 1 <= piles[i] <= 10^4
思路
有 3n 堆硬币,每次操作可以任选其中3堆,Alice 取走数量最多的那堆硬币,我们取走硬币数量第二多的,Bob 取走剩下的。求我们能获得的最大硬币数目。
为了使我们获取的硬币数量最多,Bob 每次只能取数量最少的那堆,将数量多的留下。根据这种贪心策略,我们可以将每堆硬币按个数从小到大排序,从倒数第二个开始每隔两个向前取,同时 Bob 从第一个往后挨个取,直到这两个指针相遇。
代码
/**
* @date 2025-01-22 8:50
*/
public class MaxCoins1561 {
public int maxCoins(int[] piles) {
Arrays.sort(piles);
int res = 0;
int n = piles.length;
int k = 0;
for (int i = n - 2; i > k; i -= 2, k++) {
res += piles[i];
}
return res;
}
}
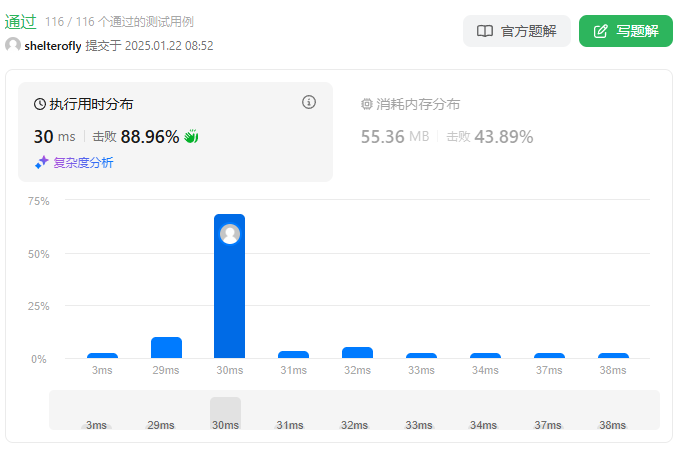
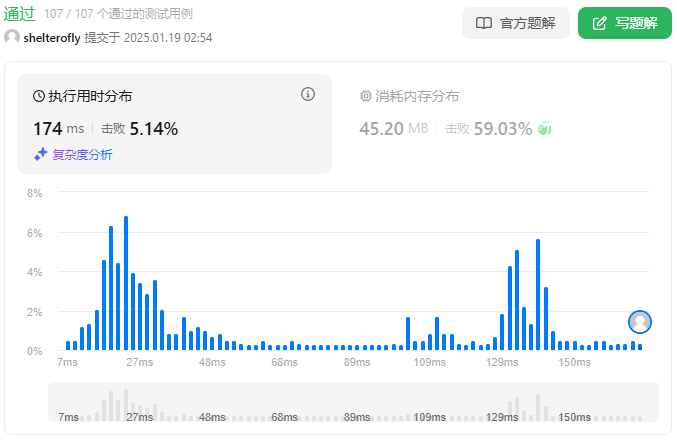
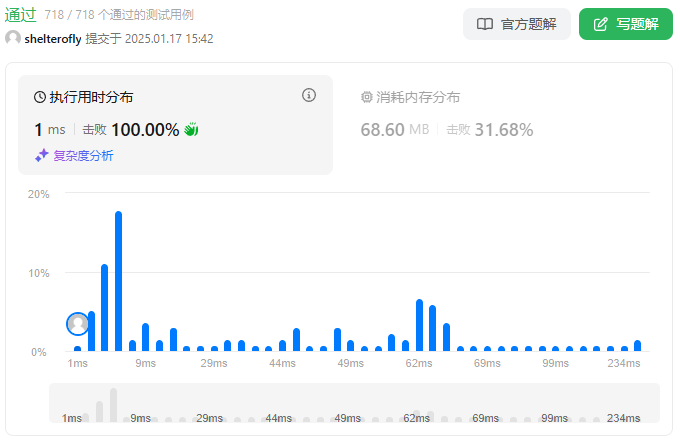
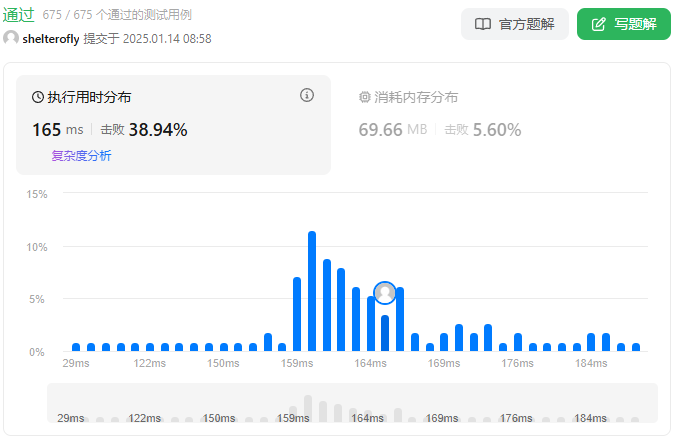
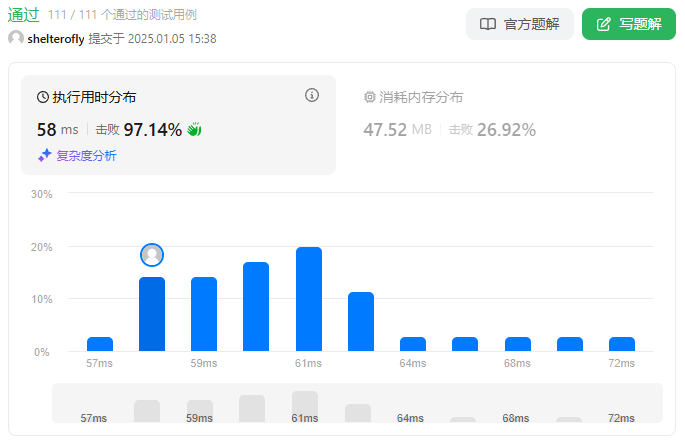
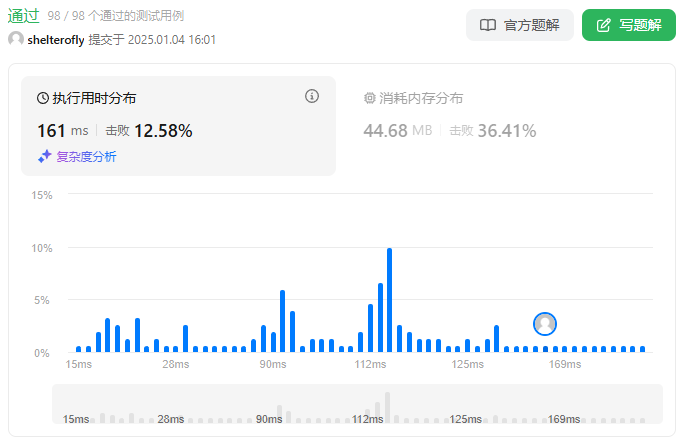
性能