目标
给你一个下标从 0 开始的整数数组nums 。每次操作中,你可以:
- 选择两个满足 0 <= i, j < nums.length 的不同下标 i 和 j 。
- 选择一个非负整数 k ,满足 nums[i] 和 nums[j] 在二进制下的第 k 位(下标编号从 0 开始)是 1 。
- 将 nums[i] 和 nums[j] 都减去 2^k 。
如果一个子数组内执行上述操作若干次后,该子数组可以变成一个全为 0 的数组,那么我们称它是一个 美丽 的子数组。
请你返回数组 nums 中 美丽子数组 的数目。
子数组是一个数组中一段连续 非空 的元素序列。
示例 1:
输入:nums = [4,3,1,2,4]
输出:2
解释:nums 中有 2 个美丽子数组:[3,1,2] 和 [4,3,1,2,4] 。
- 按照下述步骤,我们可以将子数组 [3,1,2] 中所有元素变成 0 :
- 选择 [3, 1, 2] 和 k = 1 。将 2 个数字都减去 21 ,子数组变成 [1, 1, 0] 。
- 选择 [1, 1, 0] 和 k = 0 。将 2 个数字都减去 20 ,子数组变成 [0, 0, 0] 。
- 按照下述步骤,我们可以将子数组 [4,3,1,2,4] 中所有元素变成 0 :
- 选择 [4, 3, 1, 2, 4] 和 k = 2 。将 2 个数字都减去 22 ,子数组变成 [0, 3, 1, 2, 0] 。
- 选择 [0, 3, 1, 2, 0] 和 k = 0 。将 2 个数字都减去 20 ,子数组变成 [0, 2, 0, 2, 0] 。
- 选择 [0, 2, 0, 2, 0] 和 k = 1 。将 2 个数字都减去 21 ,子数组变成 [0, 0, 0, 0, 0] 。示例 2:
输入:nums = [1,10,4]
输出:0
解释:nums 中没有任何美丽子数组。说明:
- 1 <= nums.length <= 10^5
- 0 <= nums[i] <= 10^6
思路
有一个下标从 0 开始的数组 nums,每次操作可以任选两个不同下标的元素,如果它们在二进制下的第 k 位是 1,那么将这两个元素减去 2^k,即把这两个元素的第 k 位置 0。如果对 nums 的子数组执行任意次操作后可以将子数组所有元素变为 0,称该子数组为 美丽子数组。返回数组 nums 的美丽子数组数目。
通过分析可以知道,累加美丽子数组中所有元素在二进制下每个bit位上 1 的个数,可以发现每个位置上 1 的个数都是偶数。可以通过异或运算来判断是否是美丽子数组。
代码
/**
* @date 2025-03-06 8:37
*/
public class BeautifulSubarrays2588 {
public long beautifulSubarrays(int[] nums) {
int n = nums.length;
int[] prefix = new int[n + 1];
Map<Integer, List<Integer>> map = new HashMap<>();
map.computeIfAbsent(prefix[0], x -> new ArrayList<>()).add(0);
for (int i = 1; i <= n; i++) {
prefix[i] = nums[i - 1] ^ prefix[i - 1];
map.computeIfAbsent(prefix[i], x -> new ArrayList<>()).add(i);
}
long res = 0;
for (List<Integer> value : map.values()) {
int size = value.size();
res += (size - 1L) * size / 2;
}
return res;
}
}
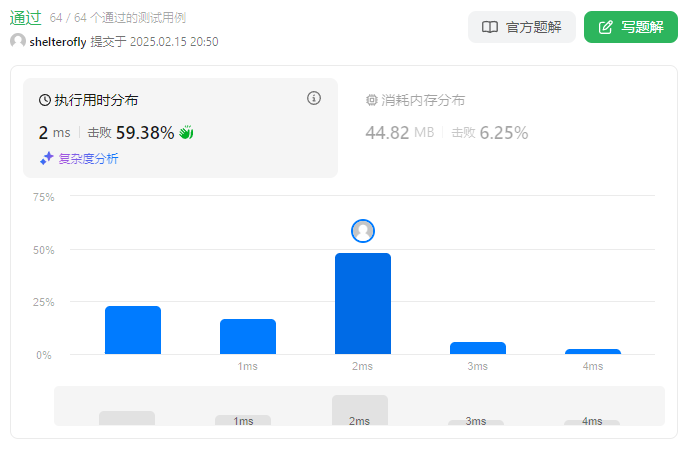
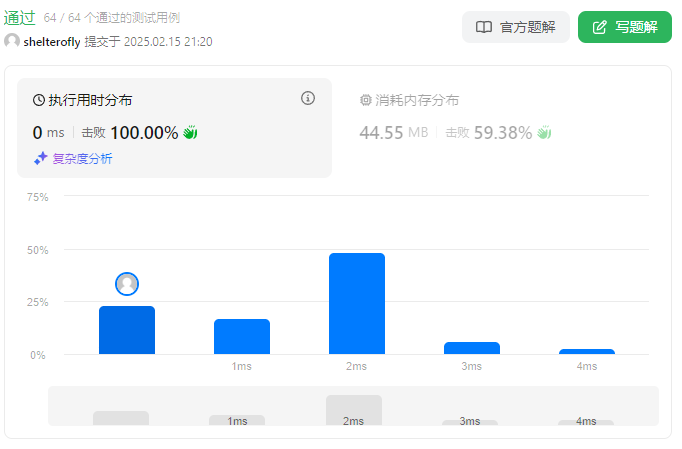
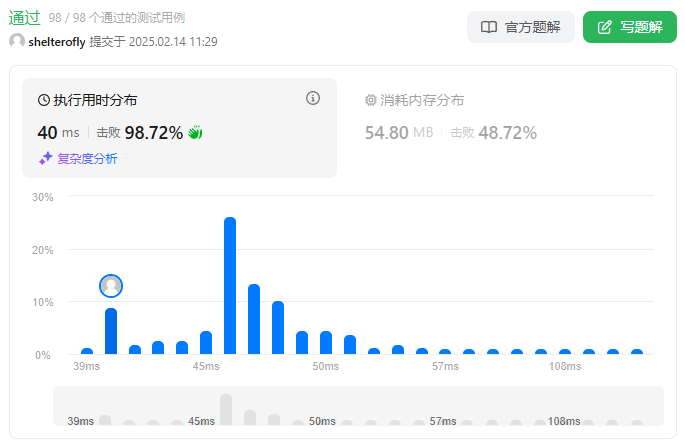
性能