目标
给你一个下标从 0 开始、大小为 m x n 的二维矩阵 grid ,请你求解大小同样为 m x n 的答案矩阵 answer 。
矩阵 answer 中每个单元格 (r, c) 的值可以按下述方式进行计算:
- 令
topLeft[r][c]为矩阵 grid 中单元格 (r, c) 左上角对角线上 不同值 的数量。 - 令
bottomRight[r][c]为矩阵 grid 中单元格 (r, c) 右下角对角线上 不同值 的数量。
然后 answer[r][c] = |topLeft[r][c] - bottomRight[r][c]| 。
返回矩阵 answer 。
矩阵对角线 是从最顶行或最左列的某个单元格开始,向右下方向走到矩阵末尾的对角线。
如果单元格 (r1, c1) 和单元格 (r, c) 属于同一条对角线且 r1 < r ,则单元格 (r1, c1) 属于单元格 (r, c) 的左上对角线。类似地,可以定义右下对角线。
示例 1:

输入:grid = [[1,2,3],[3,1,5],[3,2,1]]
输出:[[1,1,0],[1,0,1],[0,1,1]]
解释:第 1 个图表示最初的矩阵 grid 。
第 2 个图表示对单元格 (0,0) 计算,其中蓝色单元格是位于右下对角线的单元格。
第 3 个图表示对单元格 (1,2) 计算,其中红色单元格是位于左上对角线的单元格。
第 4 个图表示对单元格 (1,1) 计算,其中蓝色单元格是位于右下对角线的单元格,红色单元格是位于左上对角线的单元格。
- 单元格 (0,0) 的右下对角线包含 [1,1] ,而左上对角线包含 [] 。对应答案是 |1 - 0| = 1 。
- 单元格 (1,2) 的右下对角线包含 [] ,而左上对角线包含 [2] 。对应答案是 |0 - 1| = 1 。
- 单元格 (1,1) 的右下对角线包含 [1] ,而左上对角线包含 [1] 。对应答案是 |1 - 1| = 0 。
其他单元格的对应答案也可以按照这样的流程进行计算。示例 2:
输入:grid = [[1]]
输出:[[0]]
解释:- 单元格 (0,0) 的右下对角线包含 [] ,左上对角线包含 [] 。对应答案是 |0 - 0| = 0 。说明:
- m == grid.length
- n == grid[i].length
- 1 <= m, n,
grid[i][j]<= 50
思路
计算矩阵元素左上对角线的不同元素个数与右下对角线的不同元素个数的差的绝对值。即将元素所在的左上右下对角线,以当前元素为分界点(不包括当前元素),分成左上与右下两部分,计算每部分不同元素的个数,取差的绝对值。
暴力解法是枚举每个格子的左上右下元素,每一对角线都要遍历它所包含的元素个数次。
可以直接按对角线遍历,先记录前缀中的不同元素个数,然后再倒着遍历,计算差值的绝对值。
网友提到由于元素值不大,可以将其保存到 long 型数字中。
代码
/**
* @date 2025-03-25 0:12
*/
public class DifferenceOfDistinctValues2711 {
public int[][] differenceOfDistinctValues(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
int[][] res = new int[m][n];
for (int i = 0; i < m + n - 1; i++) {
int row = i / n < 1 ? 0 : i - n + 1 % m;
int col = row > 0 ? 0 : n - 1 - i;
Set<Integer> set = new HashSet<>();
while (row < m && col < n){
res[row][col] = set.size();
set.add(grid[row][col]);
row++;
col++;
}
row--;
col--;
set.clear();
while (row >= 0 && col >= 0){
res[row][col] = Math.abs(res[row][col] - set.size());
set.add(grid[row][col]);
row--;
col--;
}
}
return res;
}
}
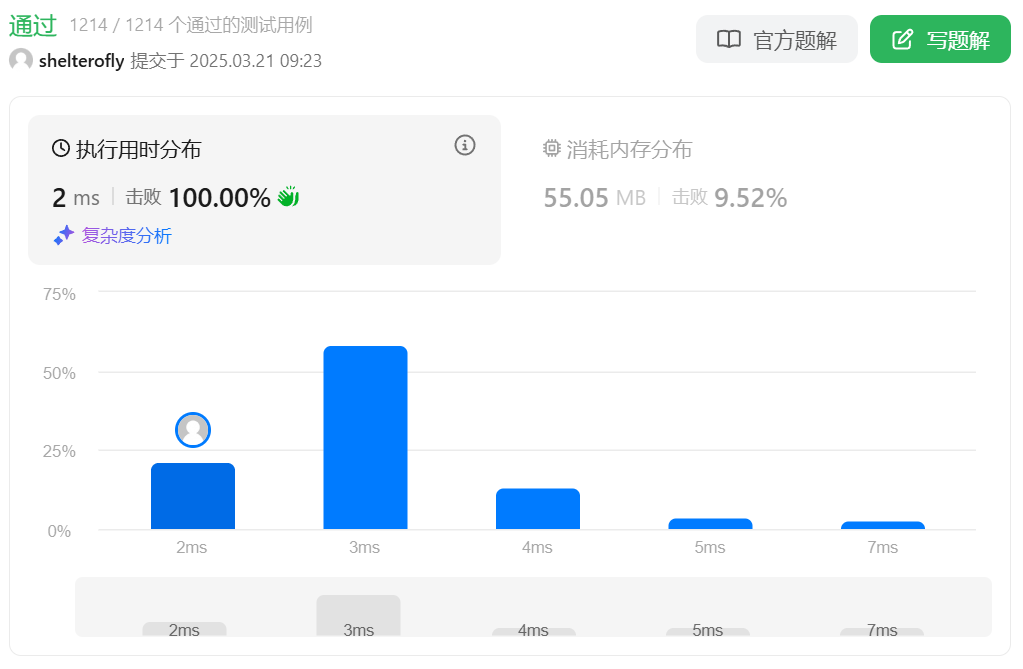
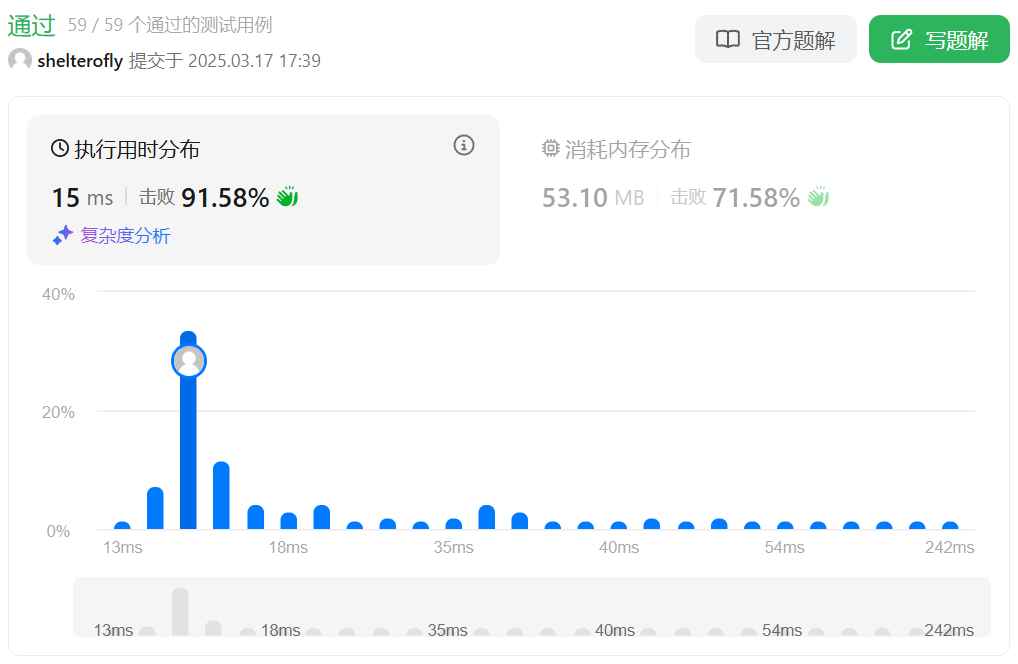
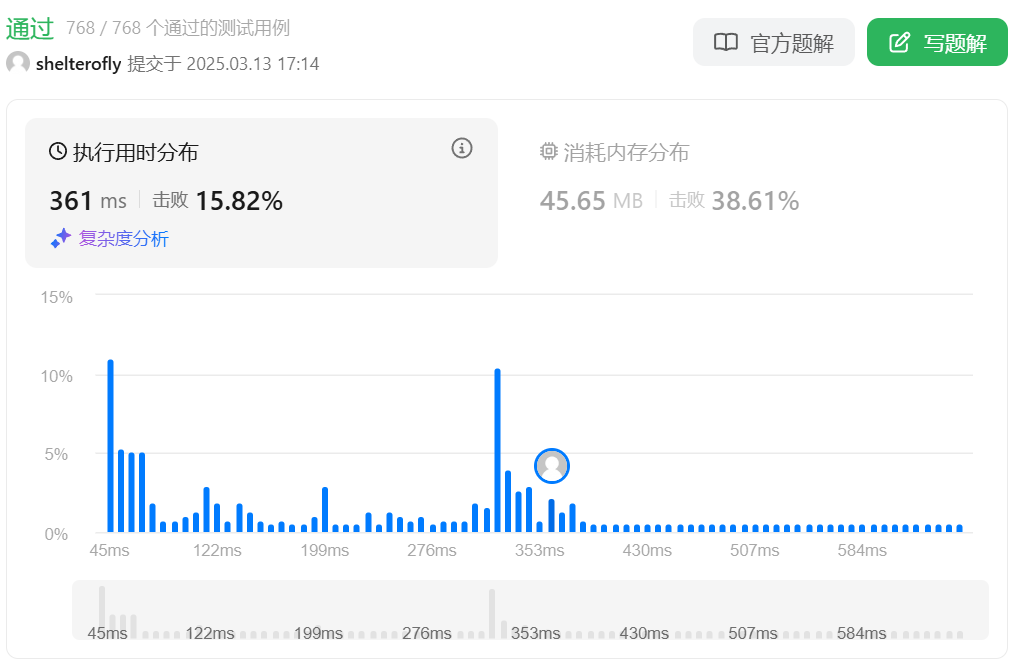
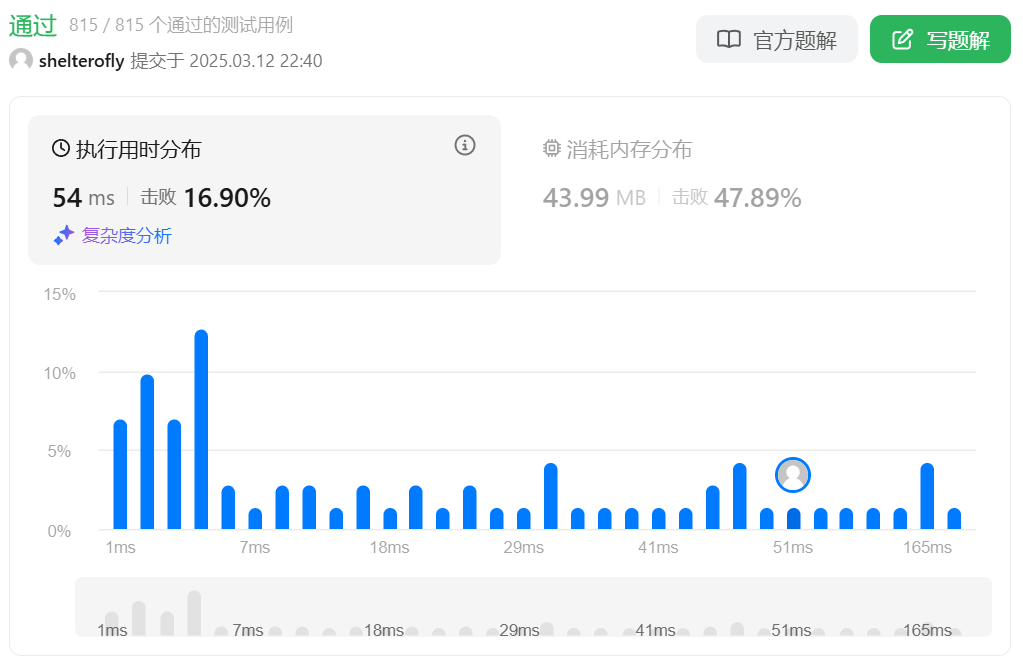
性能