目标
给你一个下标从 0 开始的整数数组 nums 。如果 i < j 且 j - i != nums[j] - nums[i] ,那么我们称 (i, j) 是一个 坏数对 。
请你返回 nums 中 坏数对 的总数目。
示例 1:
输入:nums = [4,1,3,3]
输出:5
解释:数对 (0, 1) 是坏数对,因为 1 - 0 != 1 - 4 。
数对 (0, 2) 是坏数对,因为 2 - 0 != 3 - 4, 2 != -1 。
数对 (0, 3) 是坏数对,因为 3 - 0 != 3 - 4, 3 != -1 。
数对 (1, 2) 是坏数对,因为 2 - 1 != 3 - 1, 1 != 2 。
数对 (2, 3) 是坏数对,因为 3 - 2 != 3 - 3, 1 != 0 。
总共有 5 个坏数对,所以我们返回 5 。示例 2:
输入:nums = [1,2,3,4,5]
输出:0
解释:没有坏数对。说明:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^9
思路
求数组中有多少坏数对,定义坏数对 (i, j) 满足 i < j && j - i != nums[j] - nums[i]。
将题目中的条件转化一下,j - nums[j] != i - nums[i],可以维护一个 下标 - 元素值 数组。问题变为求当前下标前有多少个元素与当前元素 不同。对元素值计数,使用当前元素下标(表示 i 前的元素个数)减去当前元素值在前面的出现次数即可。
代码
/**
* @date 2025-04-18 8:52
*/
public class CountBadPairs2364 {
public long countBadPairs(int[] nums) {
int n = nums.length;
long res = 0L;
Map<Integer, Long> cnt = new HashMap<>();
for (int i = 0; i < n; i++) {
res += i - cnt.merge(i - nums[i], 1L, Long::sum) + 1;
}
return res;
}
}
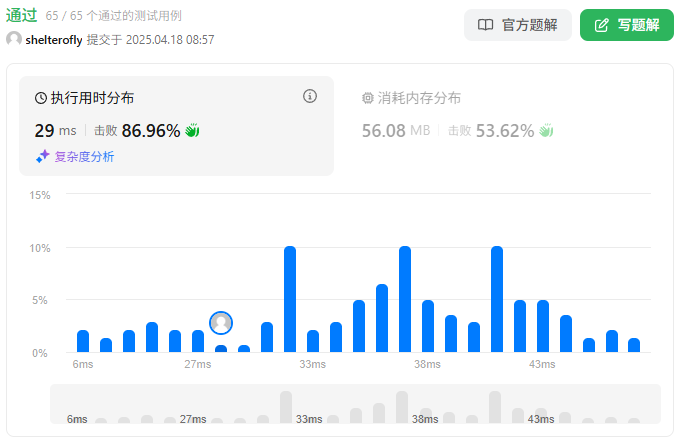
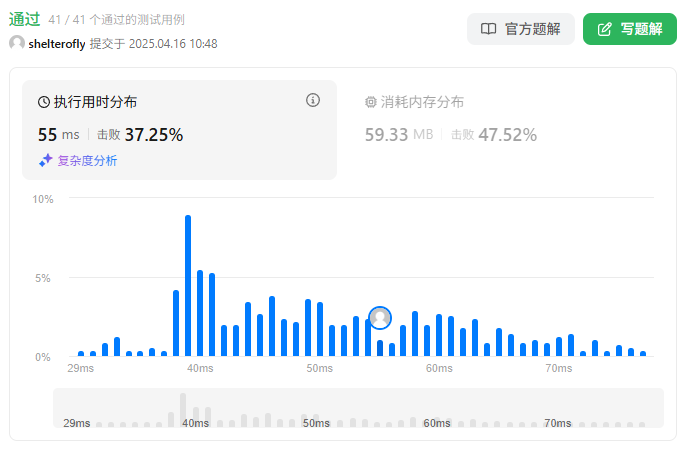
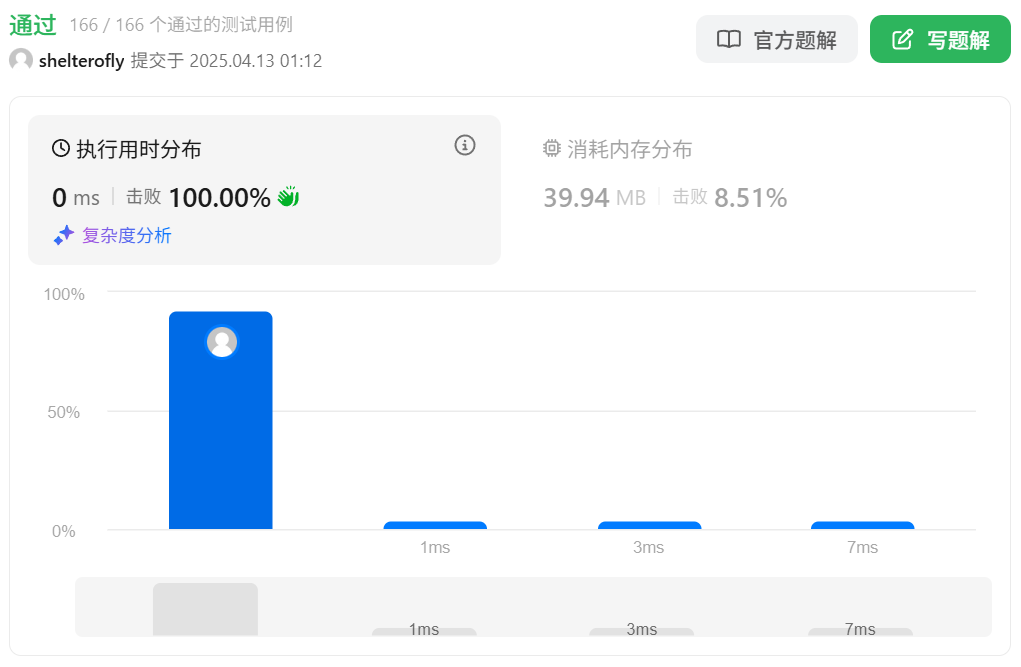
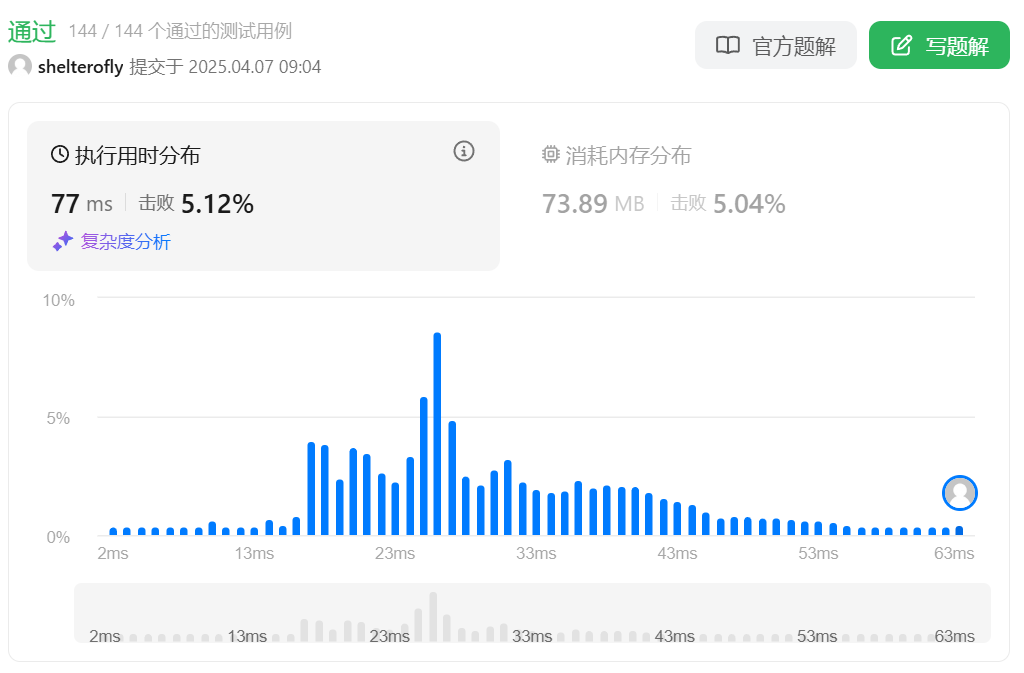
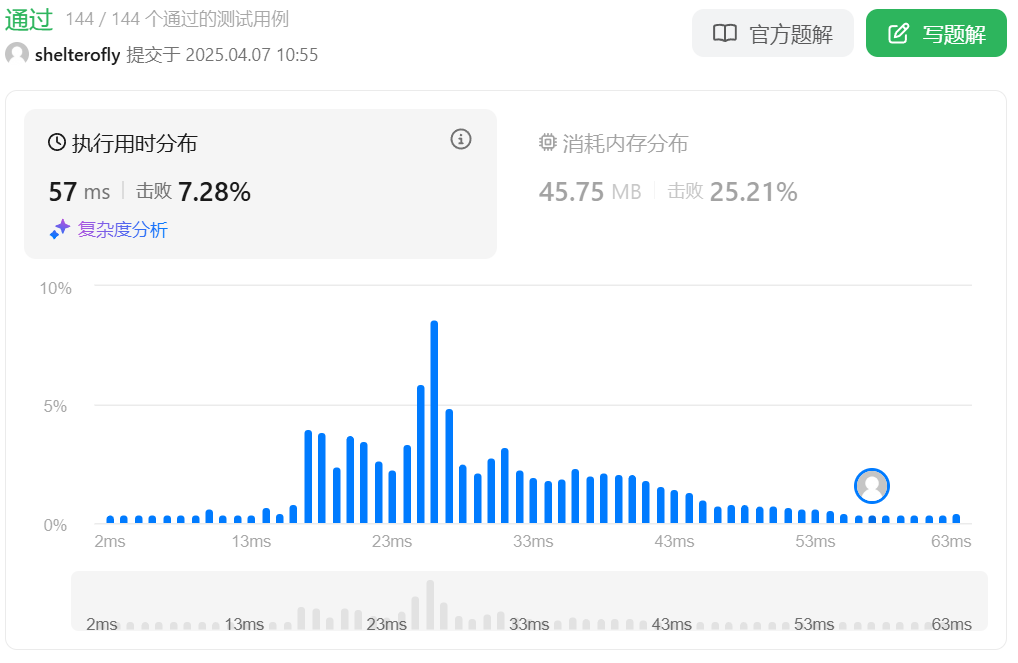
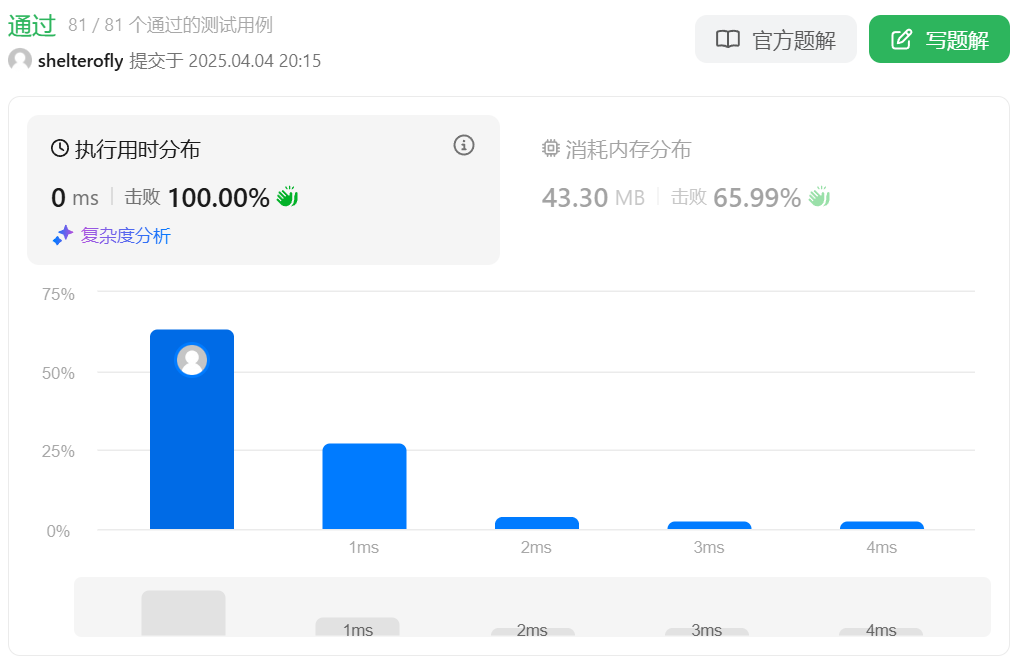
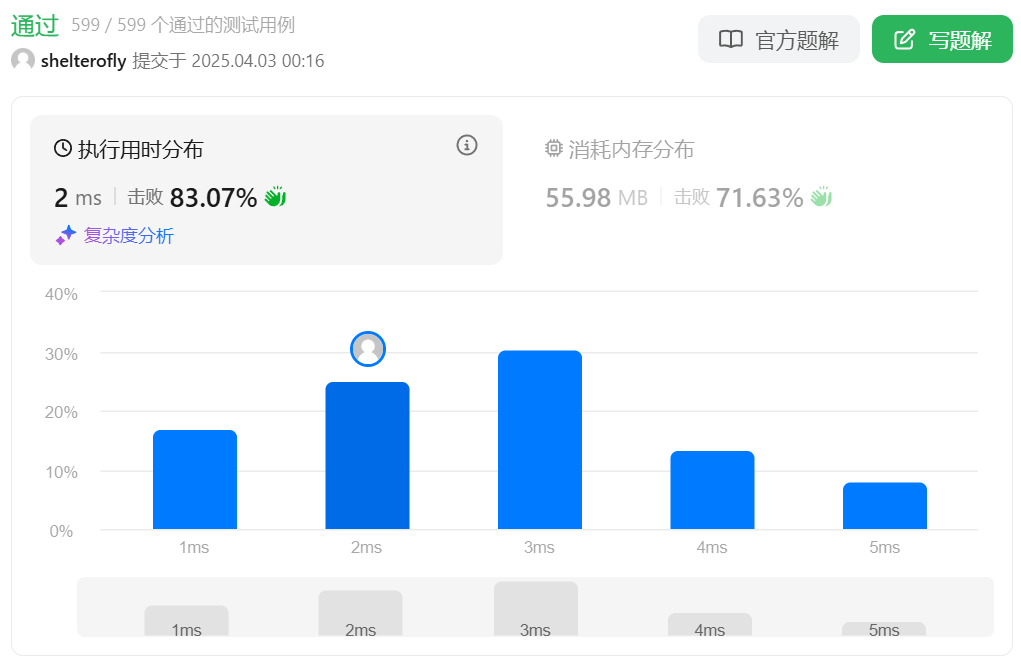
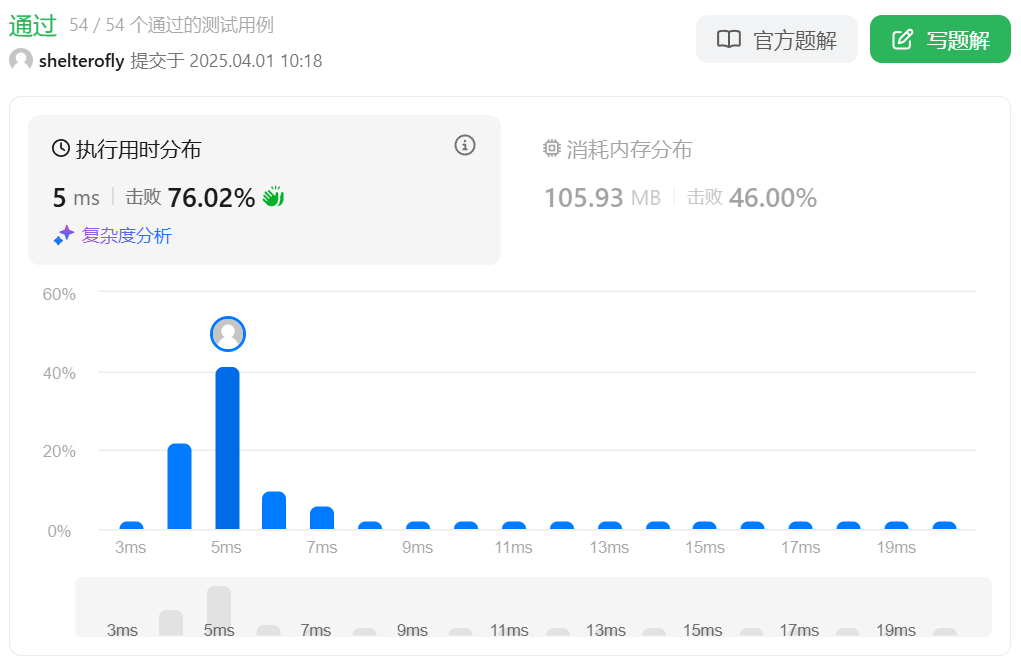
性能