目标
给你一个下标从 0 开始的整数数组 players ,其中 players[i] 表示第 i 名运动员的 能力 值,同时给你一个下标从 0 开始的整数数组 trainers ,其中 trainers[j] 表示第 j 名训练师的 训练能力值 。
如果第 i 名运动员的能力值 小于等于 第 j 名训练师的能力值,那么第 i 名运动员可以 匹配 第 j 名训练师。除此以外,每名运动员至多可以匹配一位训练师,每位训练师最多可以匹配一位运动员。
请你返回满足上述要求 players 和 trainers 的 最大 匹配数。
示例 1:
输入:players = [4,7,9], trainers = [8,2,5,8]
输出:2
解释:
得到两个匹配的一种方案是:
- players[0] 与 trainers[0] 匹配,因为 4 <= 8 。
- players[1] 与 trainers[3] 匹配,因为 7 <= 8 。
可以证明 2 是可以形成的最大匹配数。示例 2:
输入:players = [1,1,1], trainers = [10]
输出:1
解释:
训练师可以匹配所有 3 个运动员
每个运动员至多只能匹配一个训练师,所以最大答案是 1 。说明:
- 1 <= players.length, trainers.length <= 10^5
- 1 <= players[i], trainers[j] <= 10^9
思路
有两个数组 arr1 与 arr2,如果 arr1[i] <= arr2[j],则称 arr1[i] 与 arr2[j] 相匹配。arr1 中的元素最多只能匹配一个 arr2 中的元素,同时,arr2 中的元素最多只能匹配一个 arr1 中的元素,求最大匹配数。
贪心策略,arr1 中的最小元素优先匹配 arr2 中的最小元素。
代码
/**
* @date 2025-07-13 20:20
*/
public class MatchPlayersAndTrainers2410 {
public int matchPlayersAndTrainers(int[] players, int[] trainers) {
Arrays.sort(players);
Arrays.sort(trainers);
int m = players.length;
int n = trainers.length;
int res = 0;
int i = 0, j = 0;
while (i < m && j < n) {
if (players[i] <= trainers[j]) {
res++;
i++;
}
j++;
}
return res;
}
}
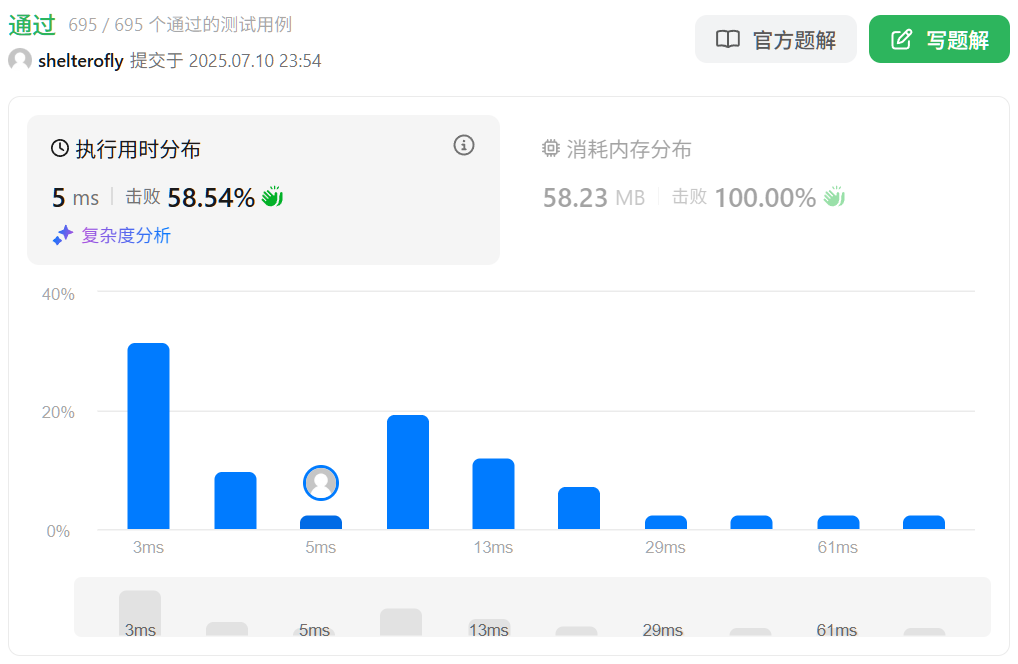
性能