目标
给你两个下标从 0 开始的字符串 source 和 target ,它们的长度均为 n 并且由 小写 英文字母组成。
另给你两个下标从 0 开始的字符数组 original 和 changed ,以及一个整数数组 cost ,其中 cost[i] 代表将字符 original[i] 更改为字符 changed[i] 的成本。
你从字符串 source 开始。在一次操作中,如果 存在 任意 下标 j 满足 cost[j] == z 、original[j] == x 以及 changed[j] == y 。你就可以选择字符串中的一个字符 x 并以 z 的成本将其更改为字符 y 。
返回将字符串 source 转换为字符串 target 所需的 最小 成本。如果不可能完成转换,则返回 -1 。
注意,可能存在下标 i 、j 使得 original[j] == original[i] 且 changed[j] == changed[i] 。
示例 1:
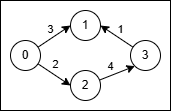
输入:source = "abcd", target = "acbe", original = ["a","b","c","c","e","d"], changed = ["b","c","b","e","b","e"], cost = [2,5,5,1,2,20]
输出:28
解释:将字符串 "abcd" 转换为字符串 "acbe" :
- 更改下标 1 处的值 'b' 为 'c' ,成本为 5 。
- 更改下标 2 处的值 'c' 为 'e' ,成本为 1 。
- 更改下标 2 处的值 'e' 为 'b' ,成本为 2 。
- 更改下标 3 处的值 'd' 为 'e' ,成本为 20 。
产生的总成本是 5 + 1 + 2 + 20 = 28 。
可以证明这是可能的最小成本。示例 2:
输入:source = "aaaa", target = "bbbb", original = ["a","c"], changed = ["c","b"], cost = [1,2]
输出:12
解释:要将字符 'a' 更改为 'b':
- 将字符 'a' 更改为 'c',成本为 1
- 将字符 'c' 更改为 'b',成本为 2
产生的总成本是 1 + 2 = 3。
将所有 'a' 更改为 'b',产生的总成本是 3 * 4 = 12 。示例 3:
输入:source = "abcd", target = "abce", original = ["a"], changed = ["e"], cost = [10000]
输出:-1
解释:无法将 source 字符串转换为 target 字符串,因为下标 3 处的值无法从 'd' 更改为 'e' 。说明:
- 1 <= source.length == target.length <= 10^5
- source、target 均由小写英文字母组成
- 1 <= cost.length== original.length == changed.length <= 2000
- original[i]、changed[i] 是小写英文字母
- 1 <= cost[i] <= 10^6
- original[i] != changed[i]
思路
求将字符串 source 转换为 target 的最小成本,转换成本由三个数组给出,将 original[i] 转换为 changed[i] 的成本为 cost[i]。
问题的关键在于有可能经过传递转换的成本更低,可以视为一个有向图中各个点之间的最短路径问题。
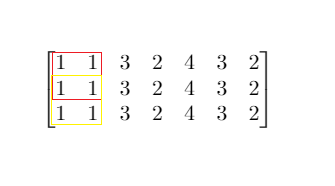
将三个描述成本的数组转换为邻接矩阵的形式,使用 floyd 算法可以解决。
代码
/**
* @date 2026-01-29 9:07
*/
public class MinimumCost2976 {
public long minimumCost(String source, String target, char[] original, char[] changed, int[] cost) {
int[][] minCost = new int[26][26];
for (int[] row : minCost) {
Arrays.fill(row, Integer.MAX_VALUE);
}
int l = original.length;
for (int i = 0; i < l; i++) {
int o = original[i] - 'a';
int c = changed[i] - 'a';
minCost[o][c] = Math.min(minCost[o][c], cost[i]);
}
floyd(minCost);
int n = source.length();
long res = 0L;
for (int i = 0; i < n; i++) {
int s = source.charAt(i) - 'a';
int t = target.charAt(i) - 'a';
if (s == t) {
continue;
}
if (minCost[s][t] == Integer.MAX_VALUE) {
return -1;
}
res += minCost[s][t];
}
return res;
}
public void floyd(int[][] dist) {
for (int k = 0; k < 26; k++) {
for (int i = 0; i < 26; i++) {
if (dist[i][k] == Integer.MAX_VALUE){
continue;
}
for (int j = 0; j < 26; j++) {
if (dist[k][j] != Integer.MAX_VALUE && dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
}
}
}
}
}
}
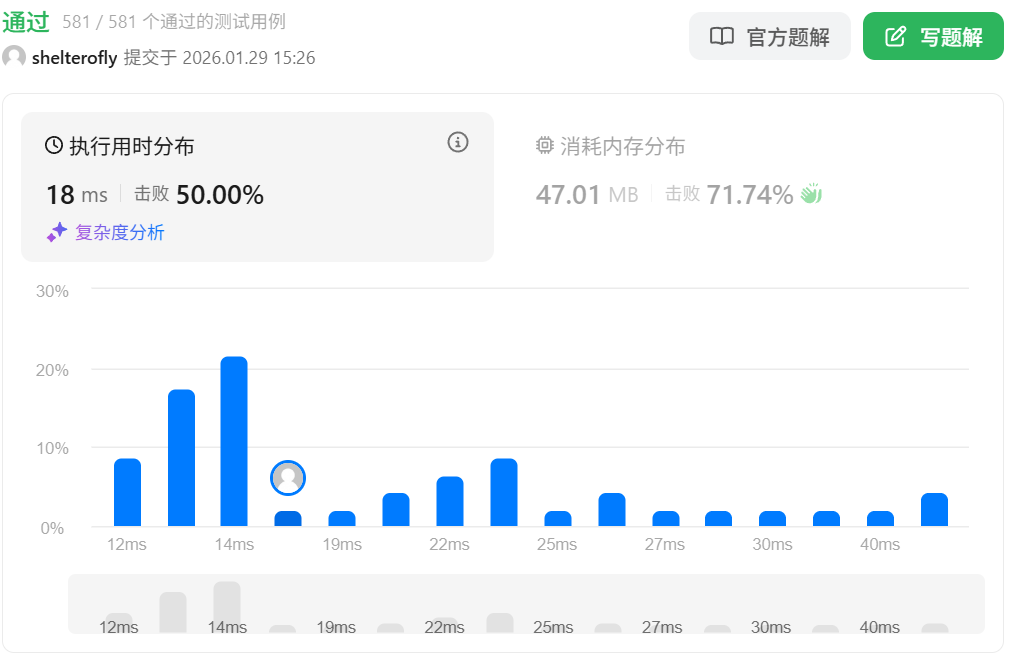
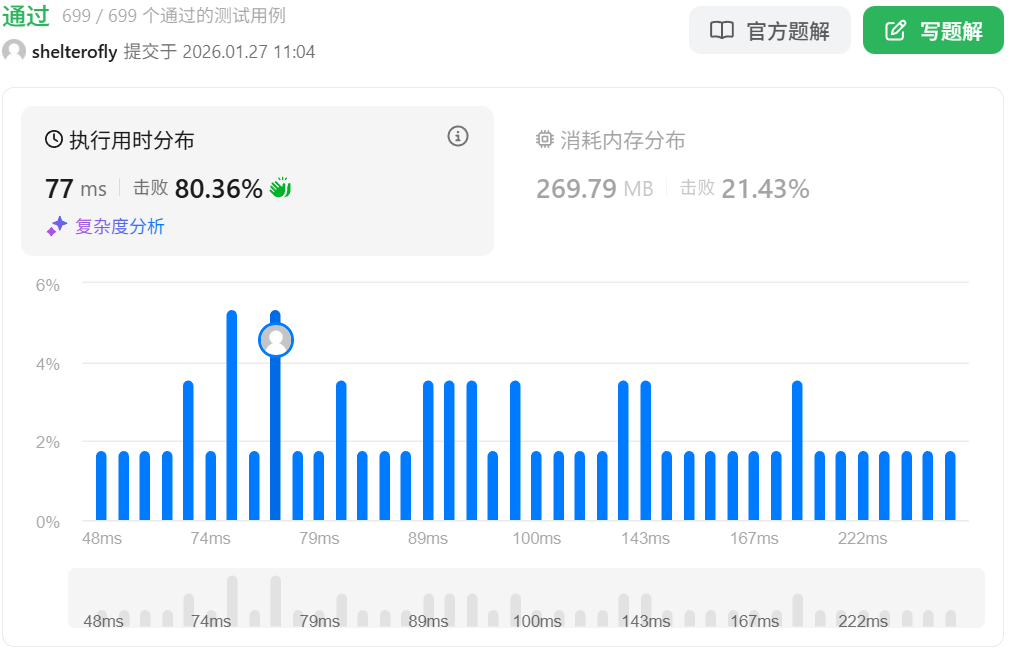
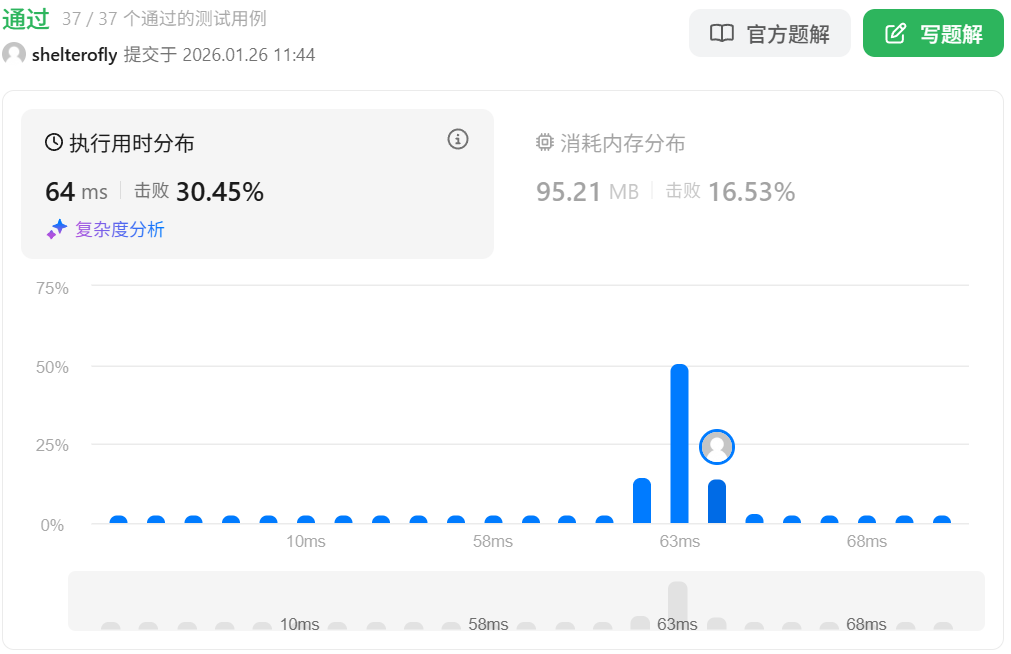
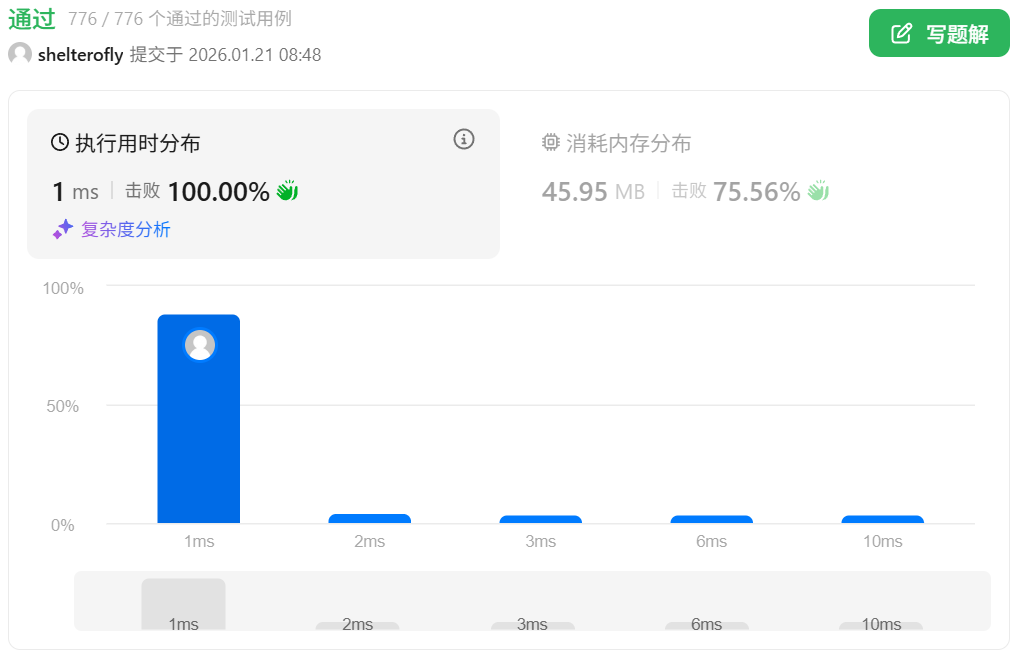
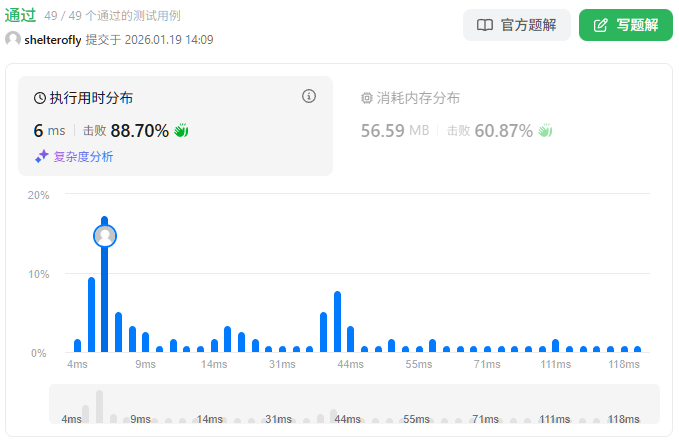
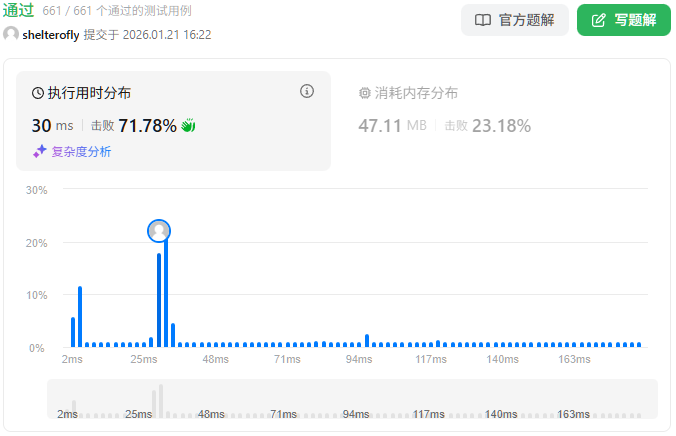
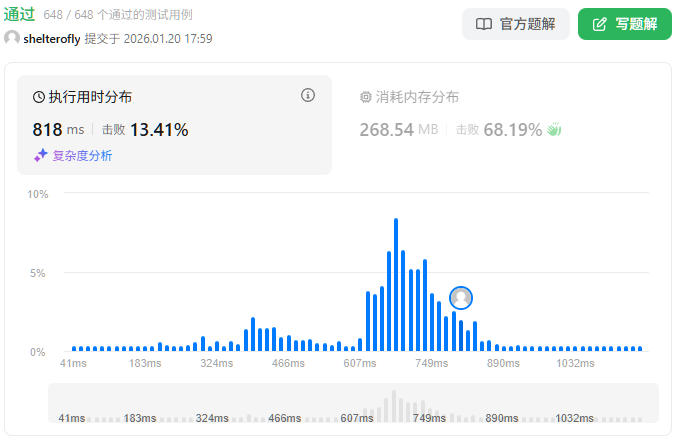
性能