目标
给你一个下标从 0 开始的整数数组 nums ,它包含 3 * n 个元素。
你可以从 nums 中删除 恰好 n 个元素,剩下的 2 * n 个元素将会被分成两个 相同大小 的部分。
- 前面 n 个元素属于第一部分,它们的和记为 sumfirst 。
- 后面 n 个元素属于第二部分,它们的和记为 sumsecond 。
两部分和的 差值 记为 sumfirst - sumsecond 。
- 比方说,sumfirst = 3 且 sumsecond = 2 ,它们的差值为 1 。
- 再比方,sumfirst = 2 且 sumsecond = 3 ,它们的差值为 -1 。
请你返回删除 n 个元素之后,剩下两部分和的 差值的最小值 是多少。
示例 1:
输入:nums = [3,1,2]
输出:-1
解释:nums 有 3 个元素,所以 n = 1 。
所以我们需要从 nums 中删除 1 个元素,并将剩下的元素分成两部分。
- 如果我们删除 nums[0] = 3 ,数组变为 [1,2] 。两部分和的差值为 1 - 2 = -1 。
- 如果我们删除 nums[1] = 1 ,数组变为 [3,2] 。两部分和的差值为 3 - 2 = 1 。
- 如果我们删除 nums[2] = 2 ,数组变为 [3,1] 。两部分和的差值为 3 - 1 = 2 。
两部分和的最小差值为 min(-1,1,2) = -1 。示例 2:
输入:nums = [7,9,5,8,1,3]
输出:1
解释:n = 2 。所以我们需要删除 2 个元素,并将剩下元素分为 2 部分。
如果我们删除元素 nums[2] = 5 和 nums[3] = 8 ,剩下元素为 [7,9,1,3] 。和的差值为 (7+9) - (1+3) = 12 。
为了得到最小差值,我们应该删除 nums[1] = 9 和 nums[4] = 1 ,剩下的元素为 [7,5,8,3] 。和的差值为 (7+5) - (8+3) = 1 。
观察可知,最优答案为 1 。说明:
- nums.length == 3 * n
- 1 <= n <= 10^5
- 1 <= nums[i] <= 10^5
思路
有一个长度为 3n 的数组,删除其中的 n 个元素,使得剩余的 2n 个元素中,前 n 个元素的和 减去 后 n 个元素和 最小。
将数组划分为长度不小于 k 的两部分,枚举分界线,进行前后缀分解,计算左侧前 k 小元素的和,以及右侧前 k 大元素的和。
可以使用长度为 k 的优先队列来维护第 k 大/小元素,根据加入与移出的元素,可以知道队列所有元素的和的变化。
代码
/**
* @date 2025-07-18 8:43
*/
public class MinimumDifference2163 {
public long minimumDifference(int[] nums) {
int l = nums.length;
int n = l / 3;
long[] suffix = new long[l + 1];
long[] prefix = new long[l + 1];
for (int i = 1; i <= n; i++) {
prefix[i] = prefix[i - 1] + nums[i - 1];
suffix[l - i] = suffix[l - i + 1] + nums[l - i];
}
PriorityQueue<Integer> left = new PriorityQueue<>((a, b) -> b - a);
PriorityQueue<Integer> right = new PriorityQueue<>();
for (int i = 0; i < 2 * n; i++) {
left.add(nums[i]);
if (left.size() > n) {
Integer num = left.poll();
prefix[i + 1] = prefix[i] + nums[i] - num;
}
}
for (int i = l - 1; i >= n; i--) {
right.add(nums[i]);
if (right.size() > n) {
Integer num = right.poll();
suffix[i] = suffix[i + 1] + nums[i] - num;
}
}
long res = Long.MAX_VALUE;
for (int i = n; i <= 2 * n; i++) {
res = Math.min(res, prefix[i] - suffix[i]);
}
return res;
}
}
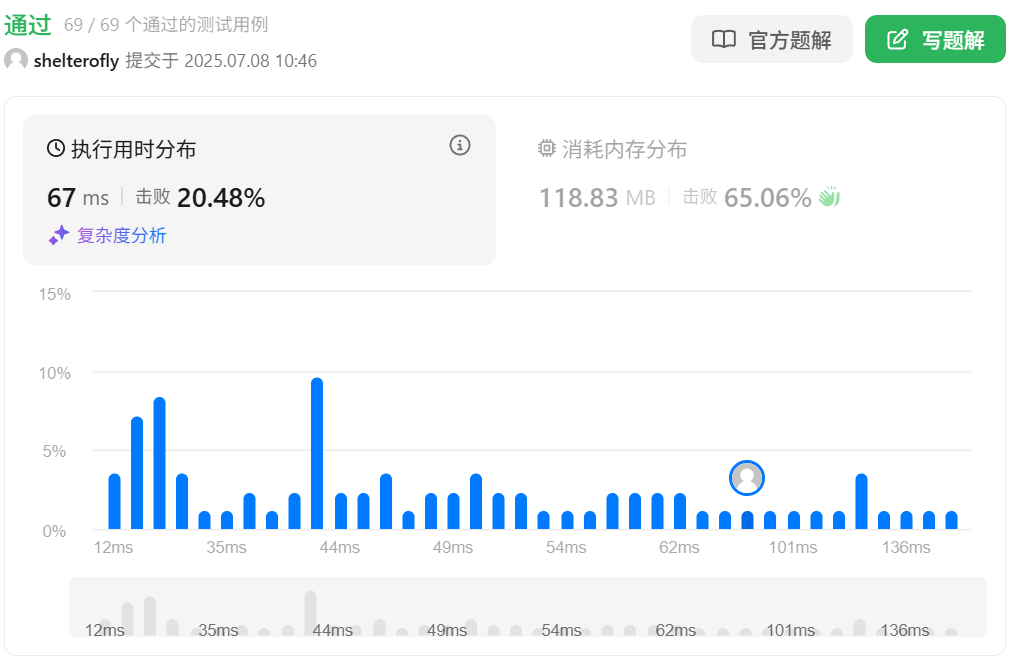
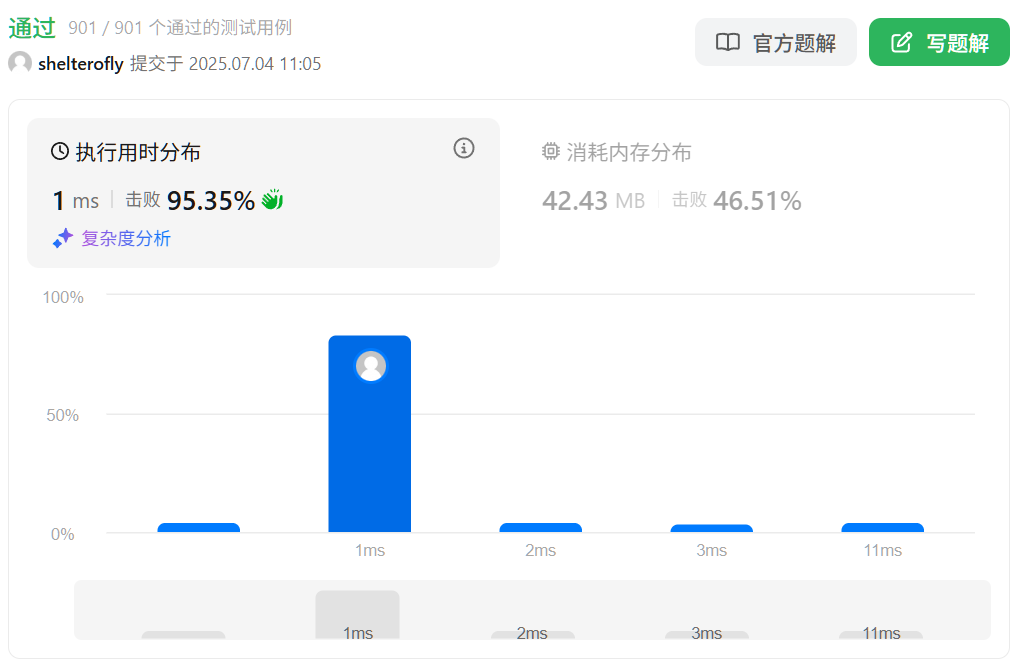
性能