目标
给定一个表示 大整数 的整数数组 digits,其中 digits[i] 是整数的第 i 位数字。这些数字按从左到右,从最高位到最低位排列。这个大整数不包含任何前导 0。
将大整数加 1,并返回结果的数字数组。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
加 1 后得到 123 + 1 = 124。
因此,结果应该是 [1,2,4]。示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
加 1 后得到 4321 + 1 = 4322。
因此,结果应该是 [4,3,2,2]。示例 3:
输入:digits = [9]
输出:[1,0]
解释:输入数组表示数字 9。
加 1 得到了 9 + 1 = 10。
因此,结果应该是 [1,0]。说明:
- 1 <= digits.length <= 100
- 0 <= digits[i] <= 9
- digits 不包含任何前导 0。
思路
数组 digits 表示一个数字,高位在前低位在后,不含前导零,将该数字加一后返回。
由于存在进位,数组长度可能增加 1 位。仔细想想,第一位是 1 后面全是 0。
从后向前遍历,如数字不是 9,将数字加一直接返回,否则,将当前位置零,继续向前进位。如果遍历结束还没有返回,说明数组长度不够,新建数组,将第一位置 1 即可。
代码
/**
* @date 2024-06-27 0:40
*/
public class PlusOne66 {
public int[] plusOne(int[] digits) {
int n = digits.length;
for (int i = n - 1; i >= 0; i--) {
int sum = digits[i] + 1;
if (sum == 10) {
digits[i] = 0;
} else {
digits[i] = sum;
return digits;
}
}
int[] res = new int[n + 1];
res[0] = 1;
return res;
}
}
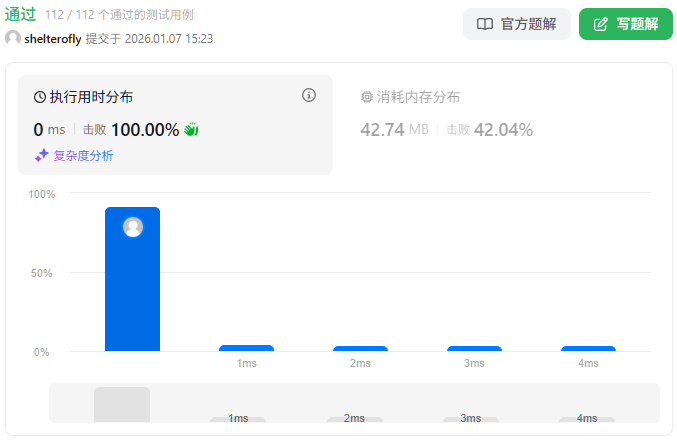
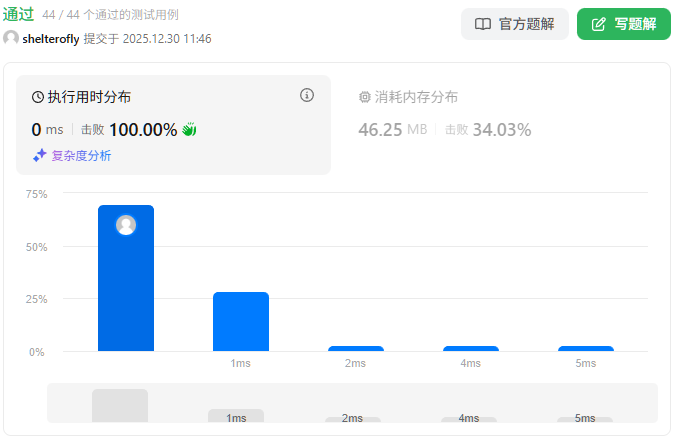
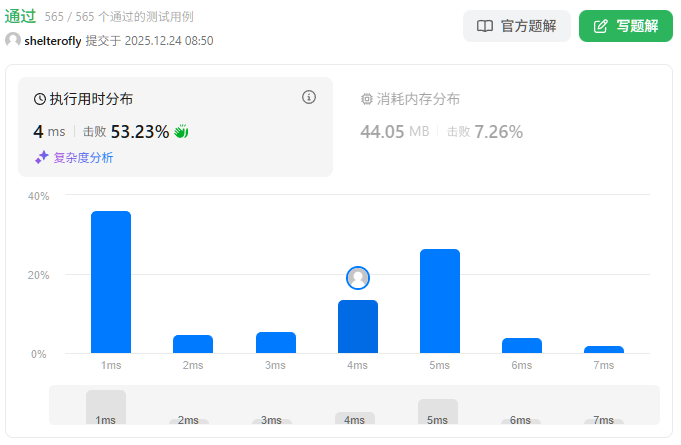
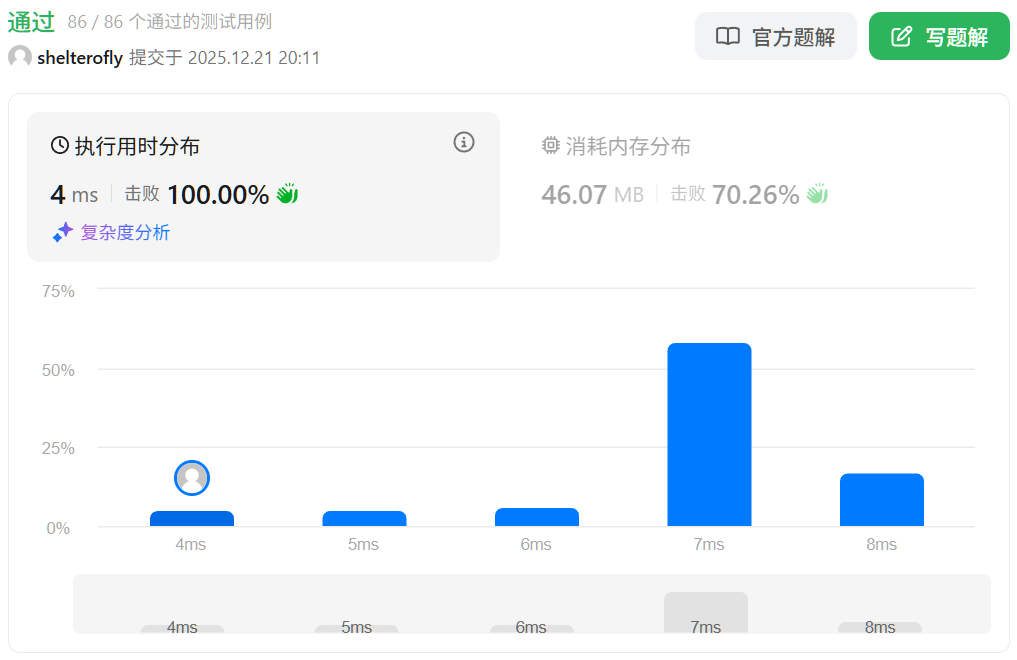
性能