目标
给你三个 正 整数 num1 ,num2 和 num3 。
数字 num1 ,num2 和 num3 的数字答案 key 是一个四位数,定义如下:
- 一开始,如果有数字 少于 四位数,给它补 前导 0 。
- 答案 key 的第 i 个数位(1 <= i <= 4)为 num1 ,num2 和 num3 第 i 个数位中的 最小 值。
请你返回三个数字 没有 前导 0 的数字答案。
示例 1:
输入:num1 = 1, num2 = 10, num3 = 1000
输出:0
解释:
补前导 0 后,num1 变为 "0001" ,num2 变为 "0010" ,num3 保持不变,为 "1000" 。
数字答案 key 的第 1 个数位为 min(0, 0, 1) 。
数字答案 key 的第 2 个数位为 min(0, 0, 0) 。
数字答案 key 的第 3 个数位为 min(0, 1, 0) 。
数字答案 key 的第 4 个数位为 min(1, 0, 0) 。
所以数字答案为 "0000" ,也就是 0 。示例 2:
输入: num1 = 987, num2 = 879, num3 = 798
输出:777示例 3:
输入:num1 = 1, num2 = 2, num3 = 3
输出:1
说明:
- 1 <= num1, num2, num3 <= 9999
思路
有三个小于等于 9999 的正整数,求四位数字 key,从左向右第 i 位是这三个数字对应数位(十进制)上数字的最小值。
根据题意模拟即可。
代码
/**
* @date 2025-01-11 16:55
*/
public class GenerateKey3270 {
public int generateKey(int num1, int num2, int num3) {
int res = 0;
int base = 1000;
for (int i = 0; i < 4; i++) {
int a1 = num1 / base;
int a2 = num2 / base;
int a3 = num3 / base;
res += Math.min(a1, Math.min(a2, a3)) * base;
num1 %= base;
num2 %= base;
num3 %= base;
base /= 10;
}
return res;
}
}
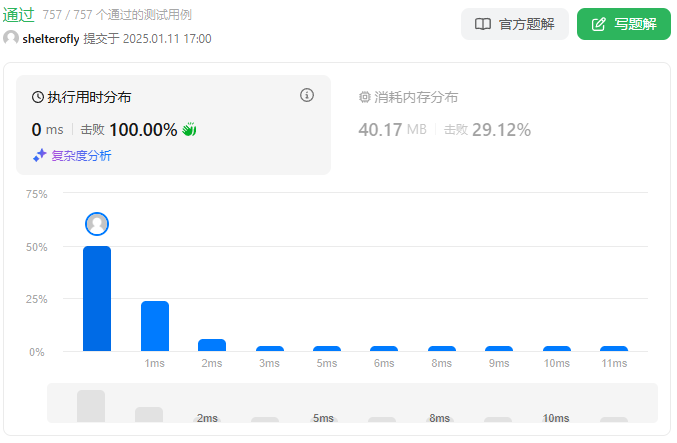
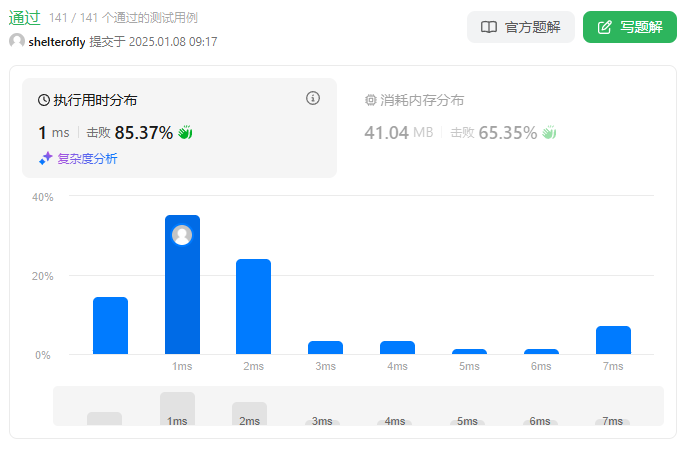
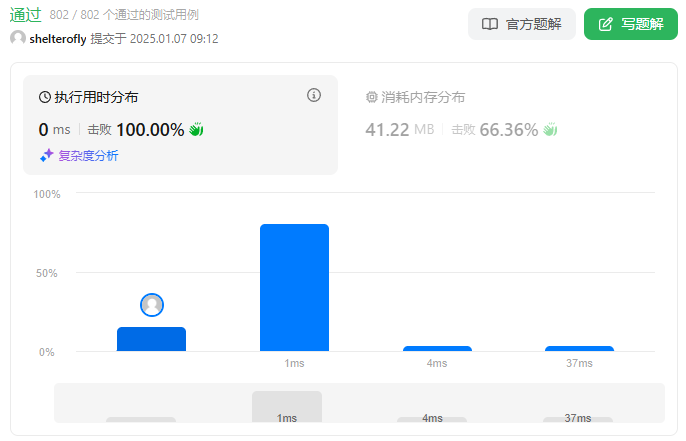
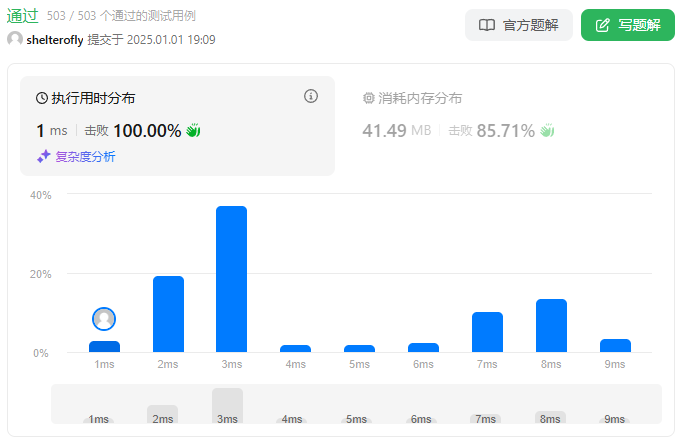
性能