目标
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是 按字符 ASCII 顺序排列 的邮箱地址。账户本身可以以 任意顺序 返回。
示例 1:
输入:accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
输出:[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
示例 2:
输入:accounts = [["Gabe","Gabe0@m.co","Gabe3@m.co","Gabe1@m.co"],["Kevin","Kevin3@m.co","Kevin5@m.co","Kevin0@m.co"],["Ethan","Ethan5@m.co","Ethan4@m.co","Ethan0@m.co"],["Hanzo","Hanzo3@m.co","Hanzo1@m.co","Hanzo0@m.co"],["Fern","Fern5@m.co","Fern1@m.co","Fern0@m.co"]]
输出:[["Ethan","Ethan0@m.co","Ethan4@m.co","Ethan5@m.co"],["Gabe","Gabe0@m.co","Gabe1@m.co","Gabe3@m.co"],["Hanzo","Hanzo0@m.co","Hanzo1@m.co","Hanzo3@m.co"],["Kevin","Kevin0@m.co","Kevin3@m.co","Kevin5@m.co"],["Fern","Fern0@m.co","Fern1@m.co","Fern5@m.co"]]
说明:
- 1 <= accounts.length <= 1000
- 2 <= accounts[i].length <= 10
- 1 <=
accounts[i][j].length <= 30
accounts[i][0] 由英文字母组成accounts[i][j] (for j > 0) 是有效的邮箱地址
思路
现有一个账号名称与邮箱列表组成的二维数组,如果两个账号对应的邮箱有重合,那么认为这两个账号属于同一个人,名称一定相同。但是名称相同不代表账户相同。现在需要将同一个人的账号合并,返回格式为,[名称,邮箱1,邮箱2,...],其中邮箱按 ASCII 排序。注意,同一个记录的邮箱列表中也可能存在相同邮箱,比如 ["Kevin","Kevin4@m.co","Kevin2@m.co","Kevin2@m.co"]。
直接的想法是比较名称相同的账户邮箱是否有重合,如果有则合并。先将数据整理一下,换为 Map<name, List<List<Integer>>>,然后判断集合是否有共同元素,有则合并,没有则保留。那么使用什么方式处理集合呢?如果两两比较,时间复杂度为 O(n^2),好在一个账户邮箱最多 9 个,账户数量最多1000个,数据量不大。
如果两个集合有公共邮箱,那么可以使用 a.removeAll(b) 这个函数,它的返回值是布尔类型,如果a集合调用函数之后发生变化,即移除了a与b的公共元素,则返回 true,否则 false。因此当返回 true 时,直接与b合并,否则放回队列。需要注意的问题是,集合列表 {a,b} {c,d} {d,e} {e,f} {f,b} 将 第一个集合 {a,b} 与后面的集合依次两两比较时,直到最后一个才合并为{a,b,f},错过了与前面集合的合并,因此我们需要重新与前面的集合比较。
由于需要反复地比较这些集合,又要将属于同一账户的邮箱集合从集合列表中删除,涉及到集合的动态添加与删除。如果使用 ArrayList,尽管可以使用迭代器来动态添加与删除元素,但是从中间删除效率不高,需要移动数组元素。因此我们选择队列来保存这些集合,由于我们的操作主要在首尾两端,可以使用 ArrayDeque。 ArrayDeque 双端操作效率比 LinkedList 更高,尽管它们都能在 O(1) 时间内完成操作,但是 LinkedList 需要额外的指针操作以及潜在的缓存不命中(不是连续分配的)问题,而 ArrayDeque 基于循环数组实现,只需调整头尾指针即可。
官网题解使用的是并查集,其实刚开始我也想到了使用并查集,但之前都是在图问题中用的,如果两个节点有边连接直接合并,但本题如何判断能否合并或者说是否连通呢?通常我们使用数组列表建图,但这里节点数据的类型不同,考虑使用map,key为邮箱,value为账户下标列表。遍历原二维数组,记录已合并的下标,如果邮箱对应有其它账户下标则进入dfs。
// todo 并查集
代码
/**
* @date 2024-07-15 8:40
*/
public class AccountsMerge721 {
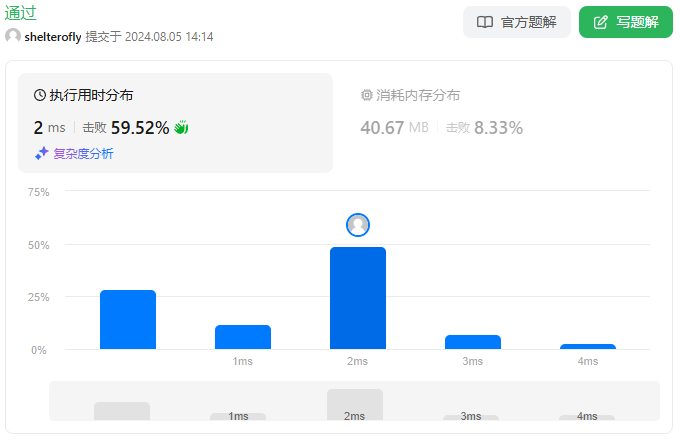
public List<List<String>> accountsMerge_v1(List<List<String>> accounts) {
int n = accounts.size();
Map<String, List<Integer>> map = new HashMap<>();
for (int i = 0; i < n; i++) {
for (int j = 1; j < accounts.get(i).size(); j++) {
map.computeIfAbsent(accounts.get(i).get(j), x -> new ArrayList<>()).add(i);
}
}
boolean[] visited = new boolean[n];
List<List<String>> res = new ArrayList<>();
for (int i = 0; i < n; i++) {
if (visited[i]) {
continue;
}
visited[i] = true;
List<String> account = accounts.get(i);
int size = account.size();
Set<String> mailList = new HashSet<>(account.subList(1, size));
for (int j = 1; j < size; j++) {
String mail = accounts.get(i).get(j);
for (Integer index : map.get(mail)) {
if (visited[index]) {
continue;
}
dfs(index, accounts, map, mailList, visited);
}
}
ArrayList<String> item = new ArrayList<>(mailList);
Collections.sort(item);
item.add(0, accounts.get(i).get(0));
res.add(item);
}
return res;
}
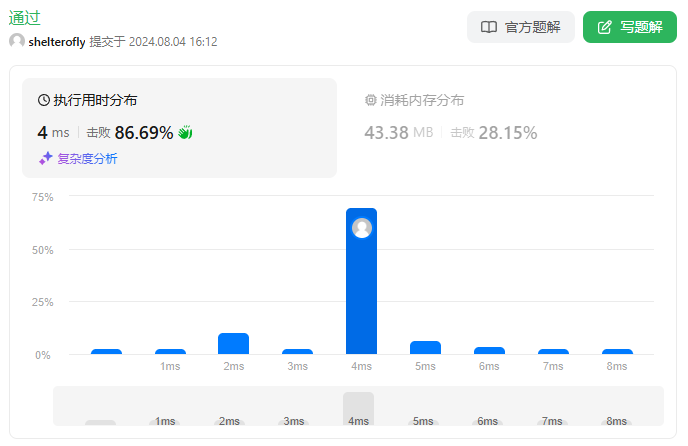
public void dfs(int index, List<List<String>> accounts, Map<String, List<Integer>> map, Set<String> mailList, boolean[] visited) {
visited[index] = true;
List<String> account = accounts.get(index);
int size = account.size();
mailList.addAll(account.subList(1, size));
for (int j = 1; j < size; j++) {
String mail = accounts.get(index).get(j);
for (Integer next : map.get(mail)) {
if (visited[next]) {
continue;
}
dfs(next, accounts, map, mailList, visited);
}
}
}
public List<List<String>> accountsMerge(List<List<String>> accounts) {
Map<String, Queue<Set<String>>> map = new HashMap<>();
for (List<String> account : accounts) {
String name = account.get(0);
map.putIfAbsent(name, new ArrayDeque<>());
Queue<Set<String>> queue = map.get(name);
Set<String> mails = new TreeSet<>();
for (int i = 1; i < account.size(); i++) {
mails.add(account.get(i));
}
queue.offer(mails);
}
List<List<String>> res = new ArrayList<>();
for (Map.Entry<String, Queue<Set<String>>> entry : map.entrySet()) {
Queue<Set<String>> queue = entry.getValue();
List<Set<String>> merged = new ArrayList<>();
while (!queue.isEmpty()) {
Set<String> mails = queue.poll();
int size = queue.size();
int cnt = 0;
for (int i = 0; i < size; i++) {
Set<String> m = queue.poll();
if (m.removeAll(mails)) {
// 存在问题,(a,b)(c,d)(d,e)(e,f)(f,b) 最后一个才合并(a,b,f),错过了与前面集合的合并
mails.addAll(m);
// 这里扩展了执行次数,与前面比较过的元素重新比较
size += cnt;
cnt = 0;
} else {
queue.add(m);
cnt++;
}
}
merged.add(mails);
}
for (Set<String> set : merged) {
List<String> l = new ArrayList<>();
l.add(entry.getKey());
l.addAll(set);
res.add(l);
}
}
return res;
}
}
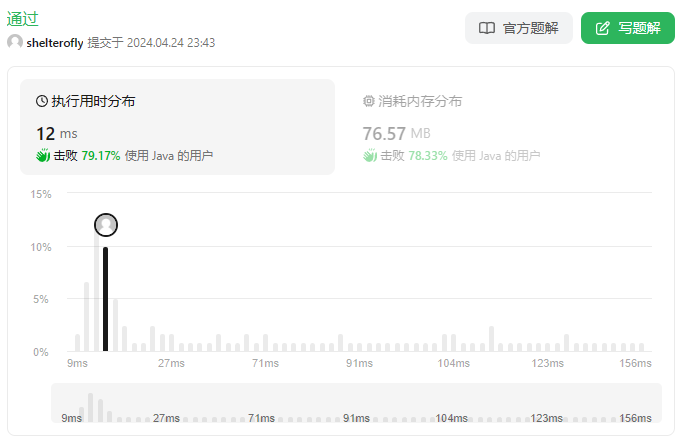
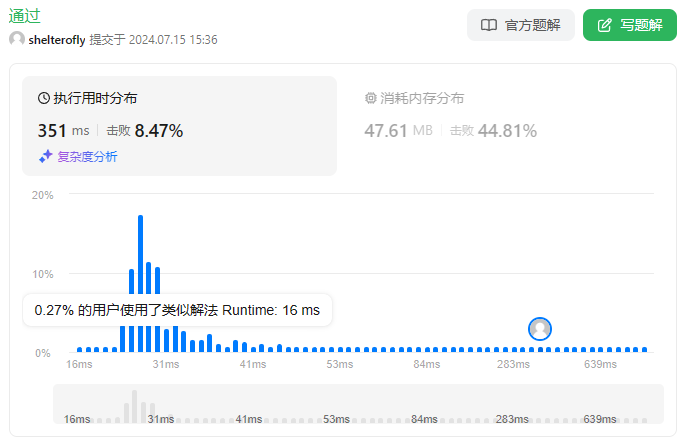
性能
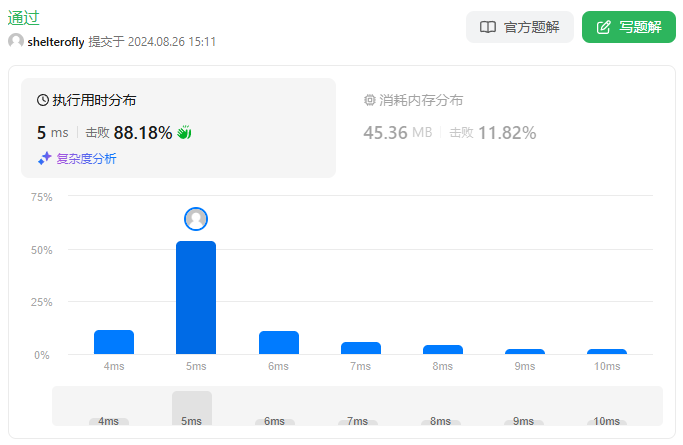
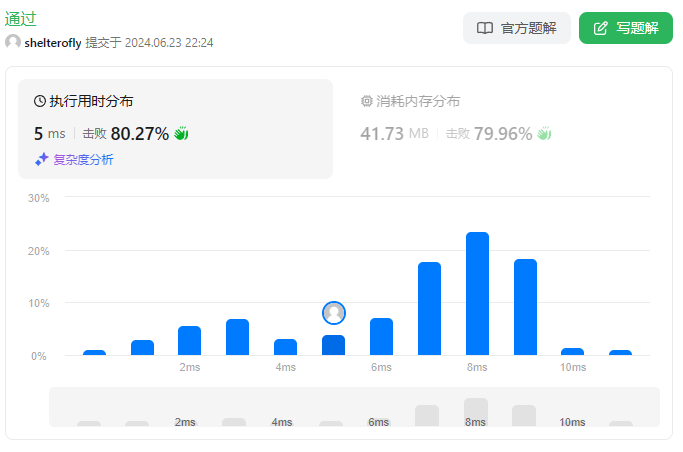
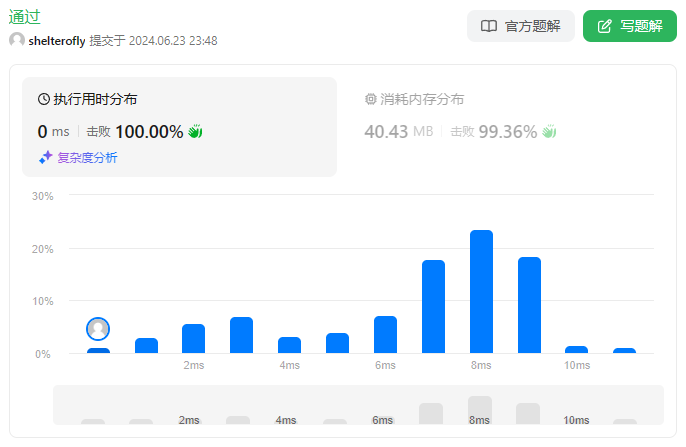
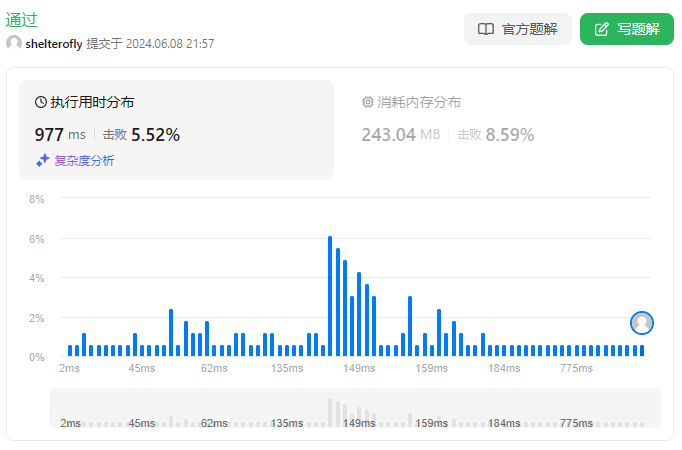
使用队列
使用dfs