目标
给定一个根为 root 的二叉树,每个节点的深度是 该节点到根的最短距离 。
返回包含原始树中所有 最深节点 的 最小子树 。
如果一个节点在 整个树 的任意节点之间具有最大的深度,则该节点是 最深的 。
一个节点的 子树 是该节点加上它的所有后代的集合。
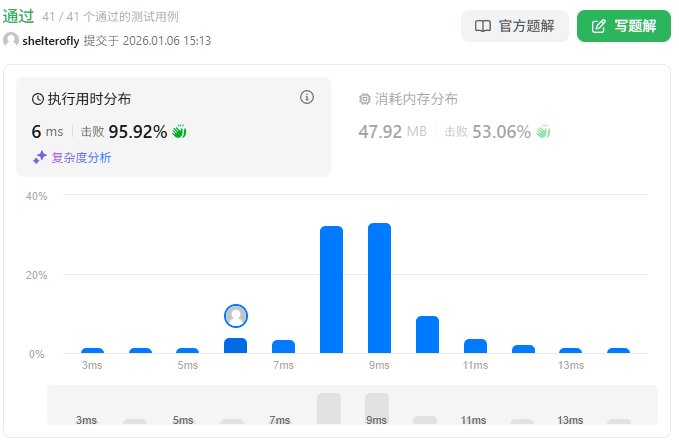
示例 1:
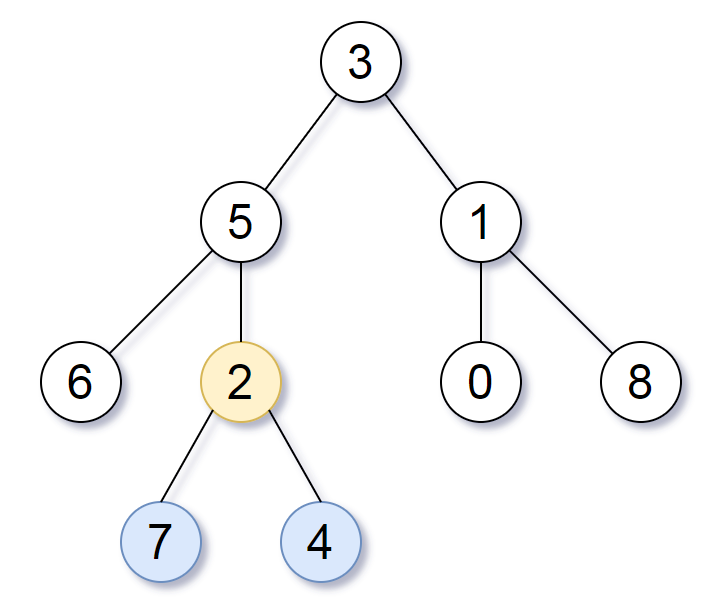
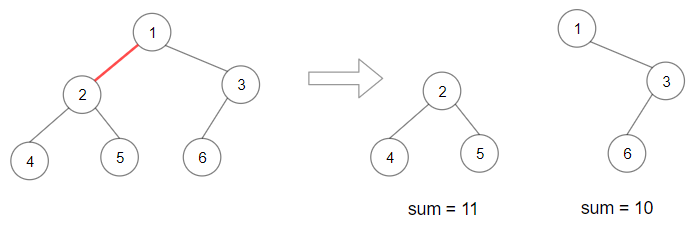
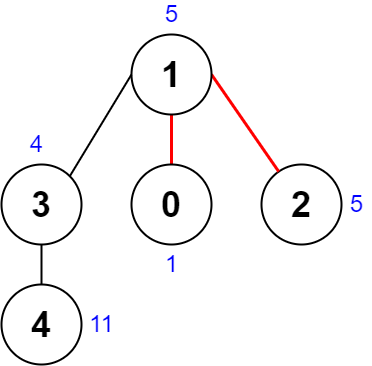
输入:root = [3,5,1,6,2,0,8,null,null,7,4]
输出:[2,7,4]
解释:
我们返回值为 2 的节点,在图中用黄色标记。
在图中用蓝色标记的是树的最深的节点。
注意,节点 5、3 和 2 包含树中最深的节点,但节点 2 的子树最小,因此我们返回它。示例 2:
输入:root = [1]
输出:[1]
解释:根节点是树中最深的节点。示例 3:
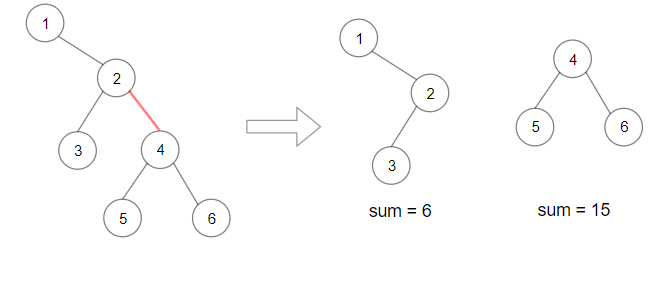
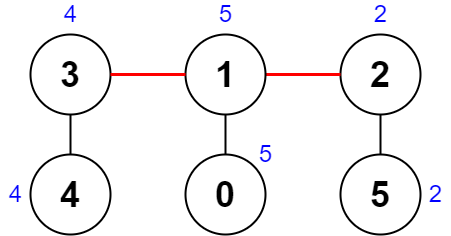
输入:root = [0,1,3,null,2]
输出:[2]
解释:树中最深的节点为 2 ,有效子树为节点 2、1 和 0 的子树,但节点 2 的子树最小。说明:
- 树中节点的数量在 [1, 500] 范围内。
- 0 <= Node.val <= 500
- 每个节点的值都是 独一无二 的。
思路
有一颗二叉树 root,返回包含所有最深节点的最小子树。
dfs 返回子树最大深度,如果左右子树的深度都等于全局的最大深度,则返回当前节点。也就是找到所有最深节点的最近公共祖先。
代码
/**
* @date 2026-01-09 8:45
*/
public class SubtreeWithAllDeepest865 {
public TreeNode subtreeWithAllDeepest(TreeNode root) {
dfs(root, -1);
return res;
}
public int dfs(TreeNode node, int deep) {
if (node == null) {
return deep;
}
int left = dfs(node.left, deep + 1);
int right = dfs(node.right, deep + 1);
int max = Math.max(left, right);
maxDeep = Math.max(max, maxDeep);
if (left == maxDeep && right == maxDeep) {
res = node;
}
return max;
}
}
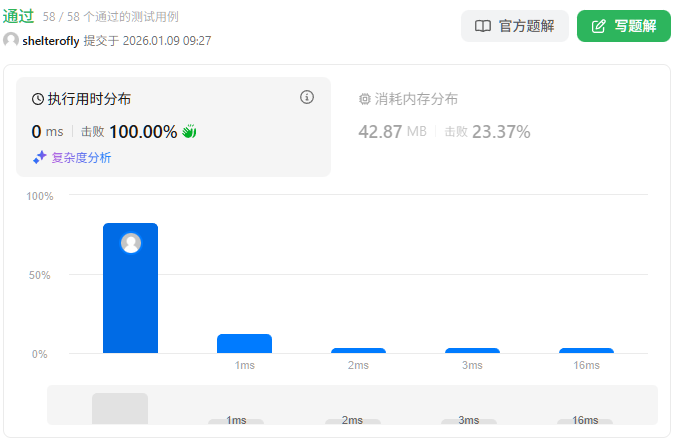
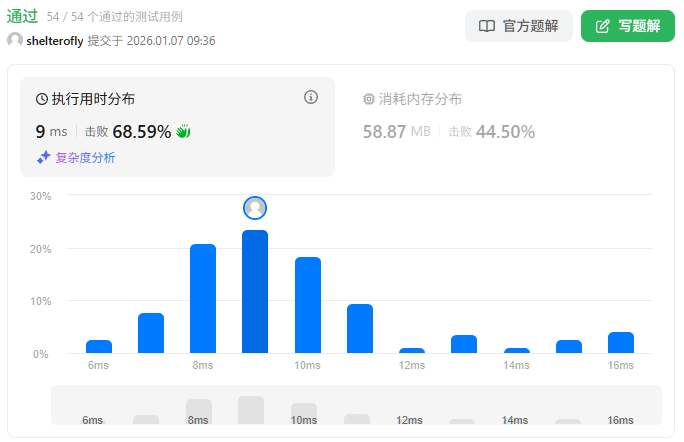
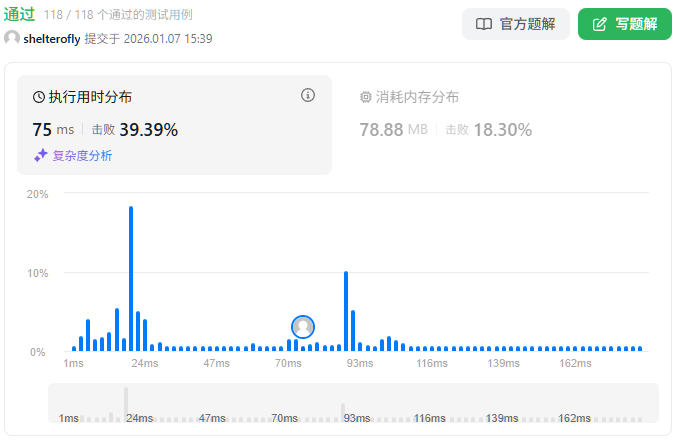
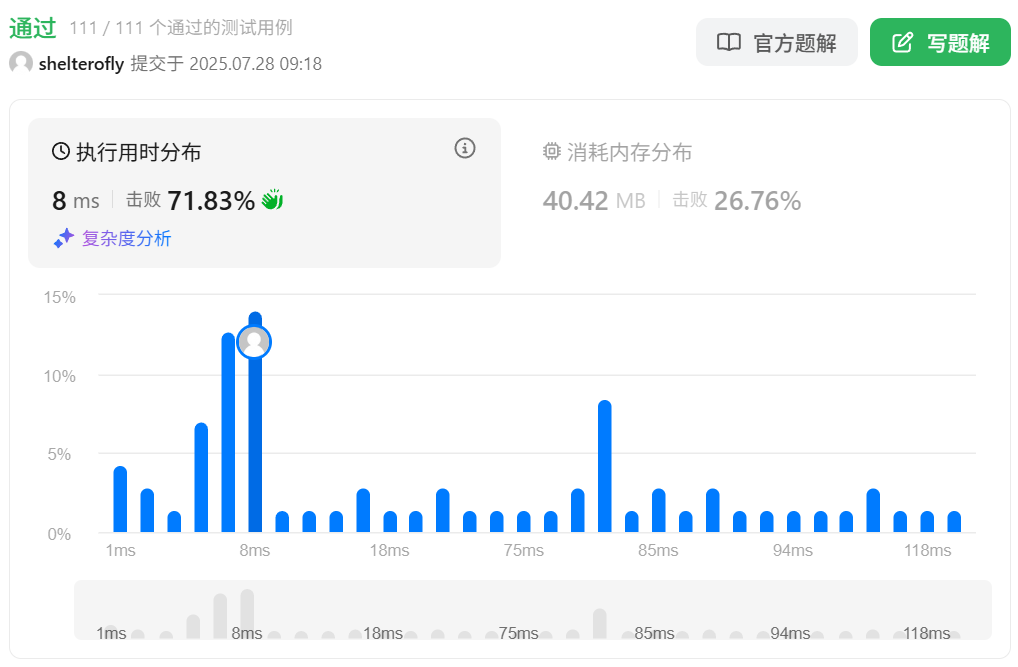
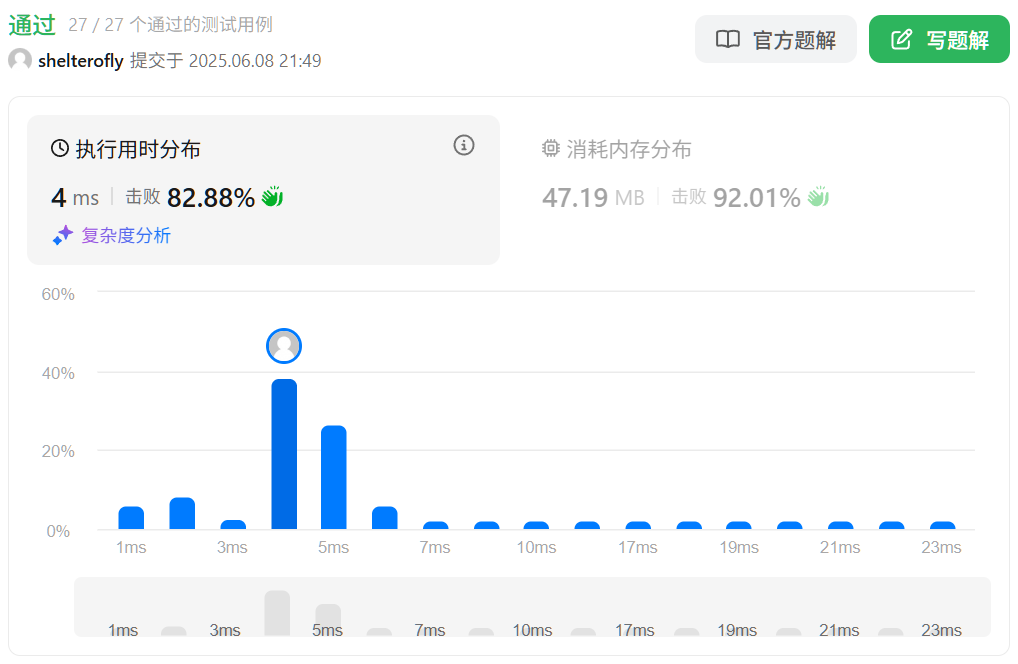
性能