目标
给你一个正整数 n ,你需要找到一个下标从 0 开始的数组 powers ,它包含 最少 数目的 2 的幂,且它们的和为 n 。powers 数组是 非递减 顺序的。根据前面描述,构造 powers 数组的方法是唯一的。
同时给你一个下标从 0 开始的二维整数数组 queries ,其中 queries[i] = [lefti, righti] ,其中 queries[i] 表示请你求出满足 lefti <= j <= righti 的所有 powers[j] 的乘积。
请你返回一个数组 answers ,长度与 queries 的长度相同,其中 answers[i]是第 i 个查询的答案。由于查询的结果可能非常大,请你将每个 answers[i] 都对 10^9 + 7 取余 。
示例 1:
输入:n = 15, queries = [[0,1],[2,2],[0,3]]
输出:[2,4,64]
解释:
对于 n = 15 ,得到 powers = [1,2,4,8] 。没法得到元素数目更少的数组。
第 1 个查询的答案:powers[0] * powers[1] = 1 * 2 = 2 。
第 2 个查询的答案:powers[2] = 4 。
第 3 个查询的答案:powers[0] * powers[1] * powers[2] * powers[3] = 1 * 2 * 4 * 8 = 64 。
每个答案对 10^9 + 7 得到的结果都相同,所以返回 [2,4,64] 。示例 2:
输入:n = 2, queries = [[0,0]]
输出:[2]
解释:
对于 n = 2, powers = [2] 。
唯一一个查询的答案是 powers[0] = 2 。答案对 10^9 + 7 取余后结果相同,所以返回 [2] 。说明:
- 1 <= n <= 10^9
- 1 <= queries.length <= 10^5
- 0 <= starti <= endi < powers.length
思路
给定一个正整数,将其拆分成最少数目的 2 的幂,即二进制表示中每一个 1 所表示的 2 的幂,按照从小到大的顺序放入 nums。有一个查询数组 queries,queries[i] = [from, to] 表示查询 nums 从 from 到 to 的乘积,返回对应的结果数组。
由于 nums 长度最大 31,因此可以提前预处理所有子数组的乘积,或值直接暴力计算查询范围内的元素乘积。
注意不能计算前缀乘积,为了防止溢出存的是余数,相除后取余并不满足分配律。或者换一种思路计算幂次的前缀和,然后再计算 2 的幂对 mod 取余。
代码
/**
* @date 2025-08-11 9:52
*/
public class ProductQueries2438 {
public int[] productQueries(int n, int[][] queries) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 31; i++) {
int p = 1 << i;
if ((n & p) == p) {
list.add(p);
}
}
int mod = 1000000007;
int[] res = new int[queries.length];
for (int i = 0; i < queries.length; i++) {
int from = queries[i][0];
int to = queries[i][1];
res[i] = 1;
for (int j = from; j <= to; j++) {
res[i] = (int) ((long) res[i] * list.get(j) % mod);
}
}
return res;
}
}
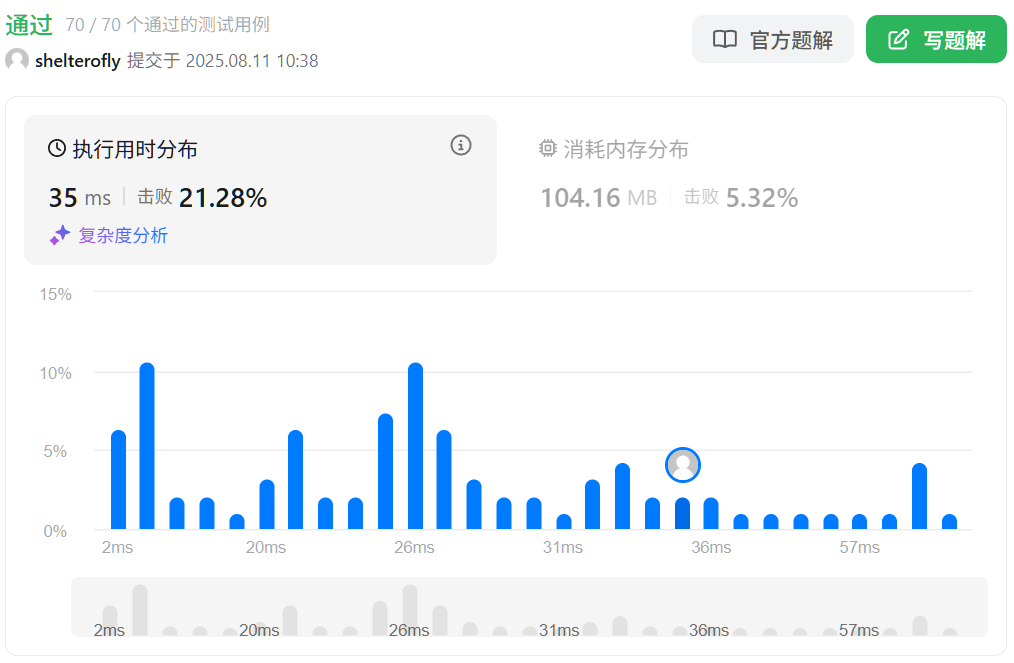
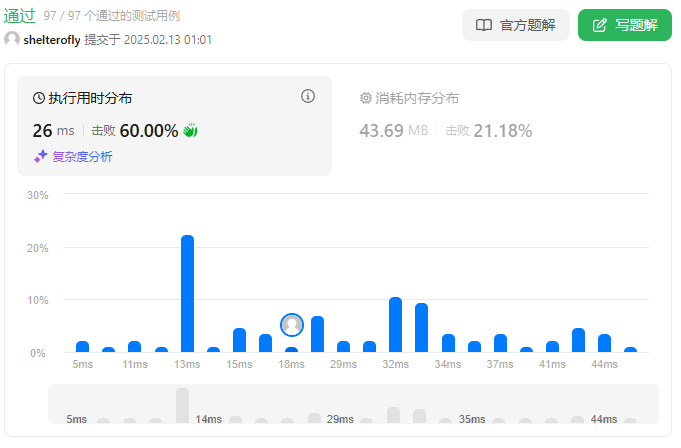
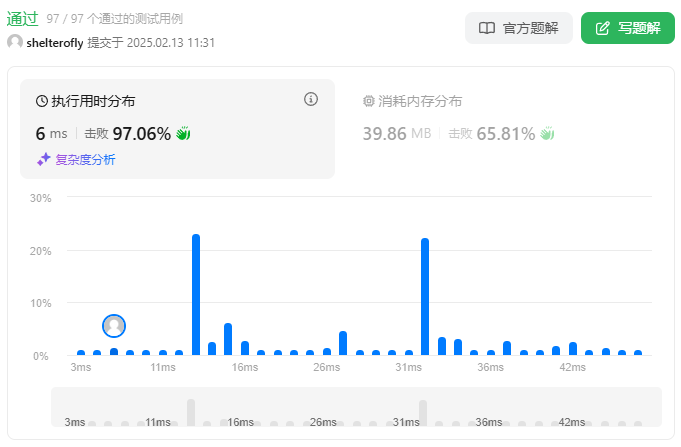
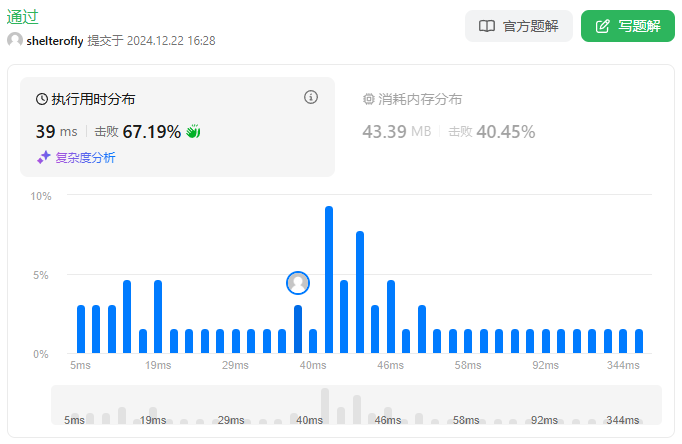
性能