目标
给你一个整数数组 arr。你可以从中选出一个整数集合,并删除这些整数在数组中的每次出现。
返回 至少 能删除数组中的一半整数的整数集合的最小大小。
示例 1:
输入:arr = [3,3,3,3,5,5,5,2,2,7]
输出:2
解释:选择 {3,7} 使得结果数组为 [5,5,5,2,2]、长度为 5(原数组长度的一半)。
大小为 2 的可行集合有 {3,5},{3,2},{5,2}。
选择 {2,7} 是不可行的,它的结果数组为 [3,3,3,3,5,5,5],新数组长度大于原数组的二分之一。示例 2:
输入:arr = [7,7,7,7,7,7]
输出:1
解释:我们只能选择集合 {7},结果数组为空。说明:
- 1 <= arr.length <= 10^5
- arr.length 为偶数
- 1 <= arr[i] <= 10^5
思路
从整数数组中选出一个元素集合,使该集合中元素在原数组中的出现次数超过原数组长度的一半,求集合大小的最小值。
统计每个元素的出现次数,将出现次数从大到小排序,然后开始选元素直到满足题目条件。
代码
/**
* @date 2024-12-15 0:17
*/
public class MinSetSize1338 {
public int minSetSize(int[] arr) {
int n = arr.length;
int[] cnt = new int[100001];
for (int i : arr) {
cnt[i]++;
}
PriorityQueue<Integer> q = new PriorityQueue<>((a, b) -> b - a);
for (int i : cnt) {
if (i > 0) {
q.offer(i);
}
}
int res = 0;
int l = 0;
while (!q.isEmpty()) {
l += q.poll();
res++;
if (l >= n / 2) {
break;
}
}
return res;
}
}
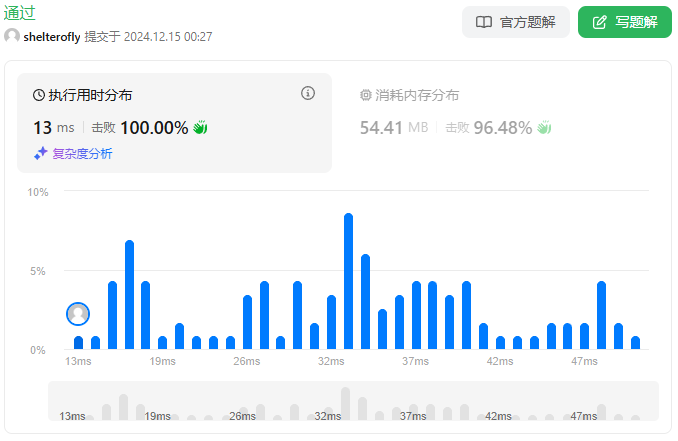
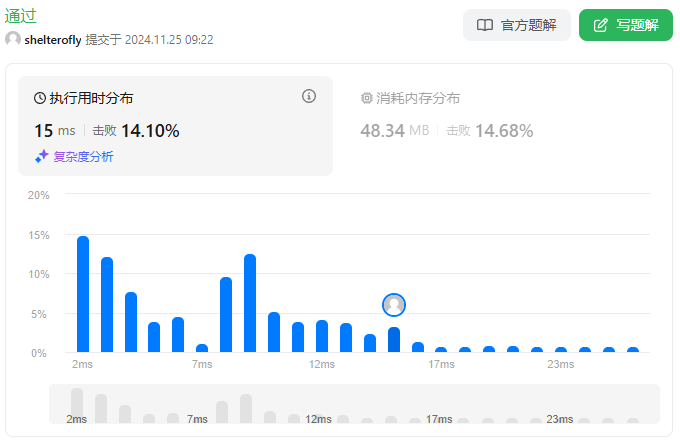
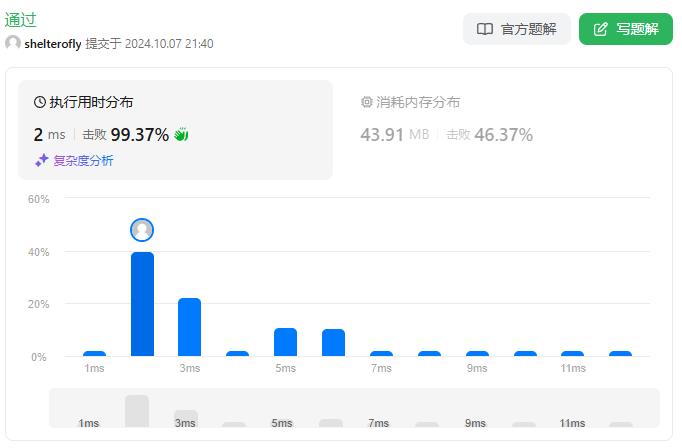
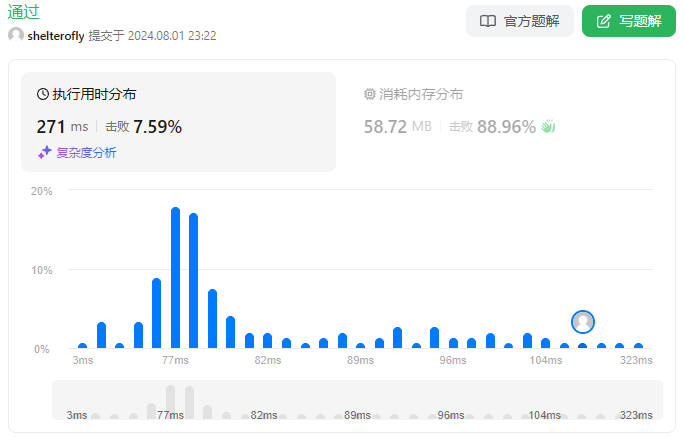
性能