目标
给你一个整数 n ,表示下标从 0 开始的内存数组的大小。所有内存单元开始都是空闲的。
请你设计一个具备以下功能的内存分配器:
- 分配 一块大小为 size 的连续空闲内存单元并赋 id mID 。
- 释放 给定 id mID 对应的所有内存单元。
注意:
- 多个块可以被分配到同一个 mID 。
- 你必须释放 mID 对应的所有内存单元,即便这些内存单元被分配在不同的块中。
实现 Allocator 类:
- Allocator(int n) 使用一个大小为 n 的内存数组初始化 Allocator 对象。
- int allocate(int size, int mID) 找出大小为 size 个连续空闲内存单元且位于 最左侧 的块,分配并赋 id mID 。返回块的第一个下标。如果不存在这样的块,返回 -1 。
- int freeMemory(int mID) 释放 id mID 对应的所有内存单元。返回释放的内存单元数目。
示例:
输入
["Allocator", "allocate", "allocate", "allocate", "freeMemory", "allocate", "allocate", "allocate", "freeMemory", "allocate", "freeMemory"]
[[10], [1, 1], [1, 2], [1, 3], [2], [3, 4], [1, 1], [1, 1], [1], [10, 2], [7]]
输出
[null, 0, 1, 2, 1, 3, 1, 6, 3, -1, 0]
解释
Allocator loc = new Allocator(10); // 初始化一个大小为 10 的内存数组,所有内存单元都是空闲的。
loc.allocate(1, 1); // 最左侧的块的第一个下标是 0 。内存数组变为 [1, , , , , , , , , ]。返回 0 。
loc.allocate(1, 2); // 最左侧的块的第一个下标是 1 。内存数组变为 [1,2, , , , , , , , ]。返回 1 。
loc.allocate(1, 3); // 最左侧的块的第一个下标是 2 。内存数组变为 [1,2,3, , , , , , , ]。返回 2 。
loc.freeMemory(2); // 释放 mID 为 2 的所有内存单元。内存数组变为 [1, ,3, , , , , , , ] 。返回 1 ,因为只有 1 个 mID 为 2 的内存单元。
loc.allocate(3, 4); // 最左侧的块的第一个下标是 3 。内存数组变为 [1, ,3,4,4,4, , , , ]。返回 3 。
loc.allocate(1, 1); // 最左侧的块的第一个下标是 1 。内存数组变为 [1,1,3,4,4,4, , , , ]。返回 1 。
loc.allocate(1, 1); // 最左侧的块的第一个下标是 6 。内存数组变为 [1,1,3,4,4,4,1, , , ]。返回 6 。
loc.freeMemory(1); // 释放 mID 为 1 的所有内存单元。内存数组变为 [ , ,3,4,4,4, , , , ] 。返回 3 ,因为有 3 个 mID 为 1 的内存单元。
loc.allocate(10, 2); // 无法找出长度为 10 个连续空闲内存单元的空闲块,所有返回 -1 。
loc.freeMemory(7); // 释放 mID 为 7 的所有内存单元。内存数组保持原状,因为不存在 mID 为 7 的内存单元。返回 0 。
说明:
- 1 <= n, size, mID <= 1000
- 最多调用 allocate 和 free 方法 1000 次
提示:
- Can you simulate the process?
- Use brute force to find the leftmost free block and free each occupied memory unit
思路
设计一个内存分配器来管理大小为 n 的内存数组,要求实现初始化、分配与释放方法。内存分配方法返回大小为 size 的连续空闲内存的最左侧下标,并为这些内存分配标识 mID。内存释放则是释放 mID 的所有内存单元。
有网友使用链表来维护空间的分配状态,定义节点属性:起点、大小、是否已分配、下一个节点、mID。分配空间时挨个查找,释放空间类似。使用节点对象表示区间,空间合并起来比较方便。
提示说可以使用暴力解法,暴力解的时间复杂度为 O(qn)。
// todo 线段树
代码
/**
* @date 2025-02-25 10:03
*/
class Allocator {
private int[] flag;
private int n;
public Allocator(int n) {
this.flag = new int[n];
this.n = n;
}
public int allocate(int size, int mID) {
int cnt = 0;
for (int i = 0; i < n; i++) {
if (flag[i] != 0) {
cnt = 0;
continue;
} else {
cnt++;
}
if (cnt == size) {
int start = i - size + 1;
for (; i >= start; i--) {
flag[i] = mID;
}
return start;
}
}
return -1;
}
public int freeMemory(int mID) {
int cnt = 0;
for (int i = 0; i < n; i++) {
if (flag[i] == mID) {
flag[i] = 0;
cnt++;
}
}
return cnt;
}
}
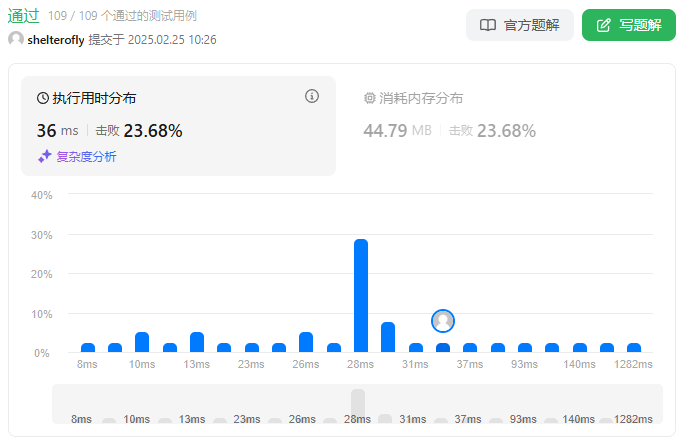
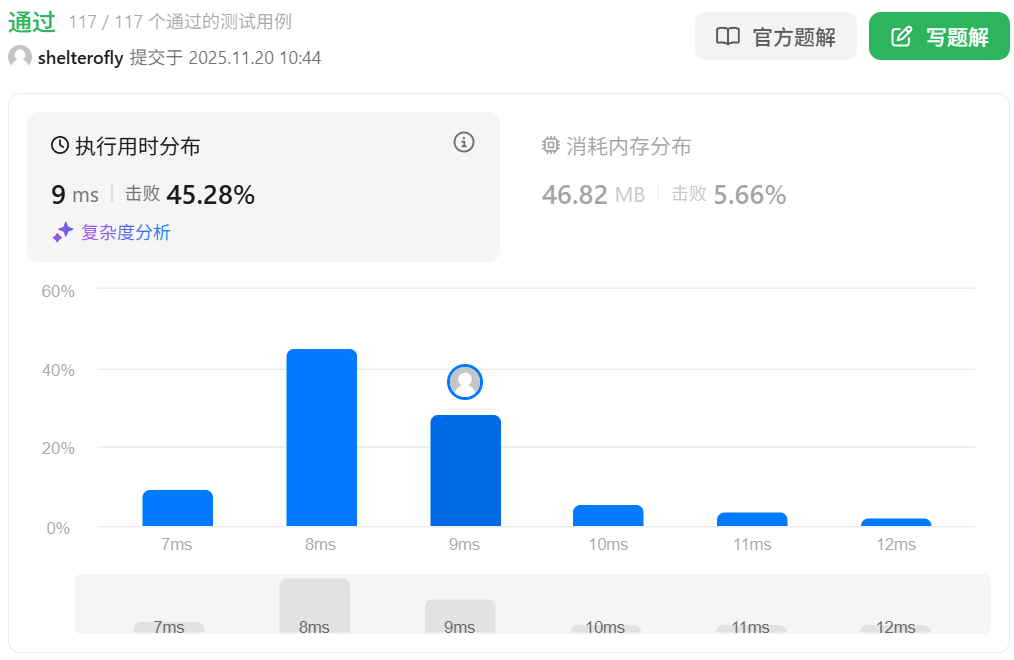
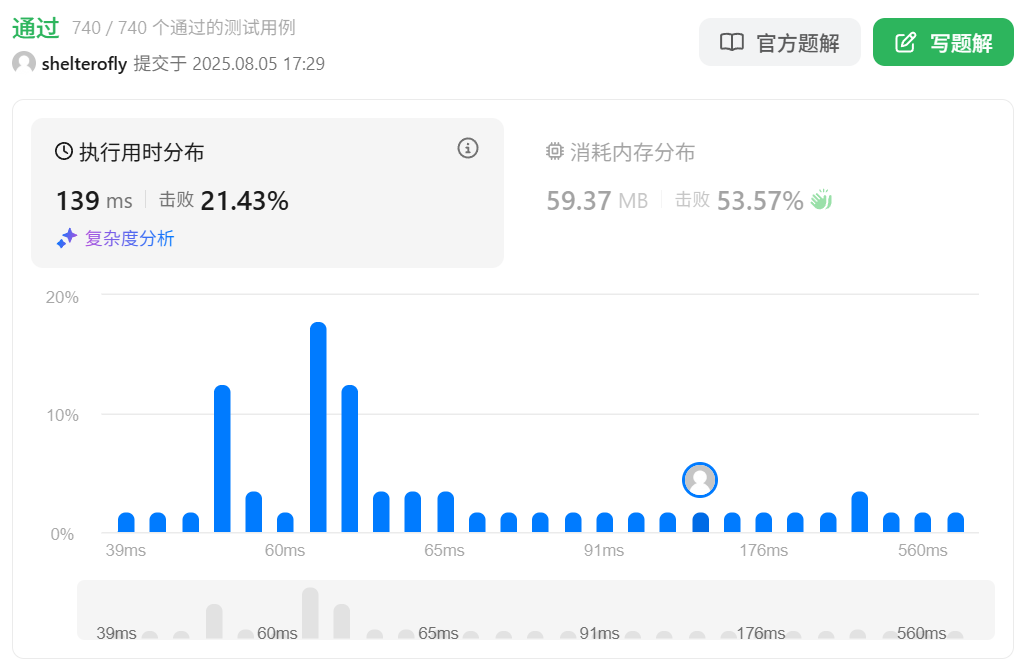
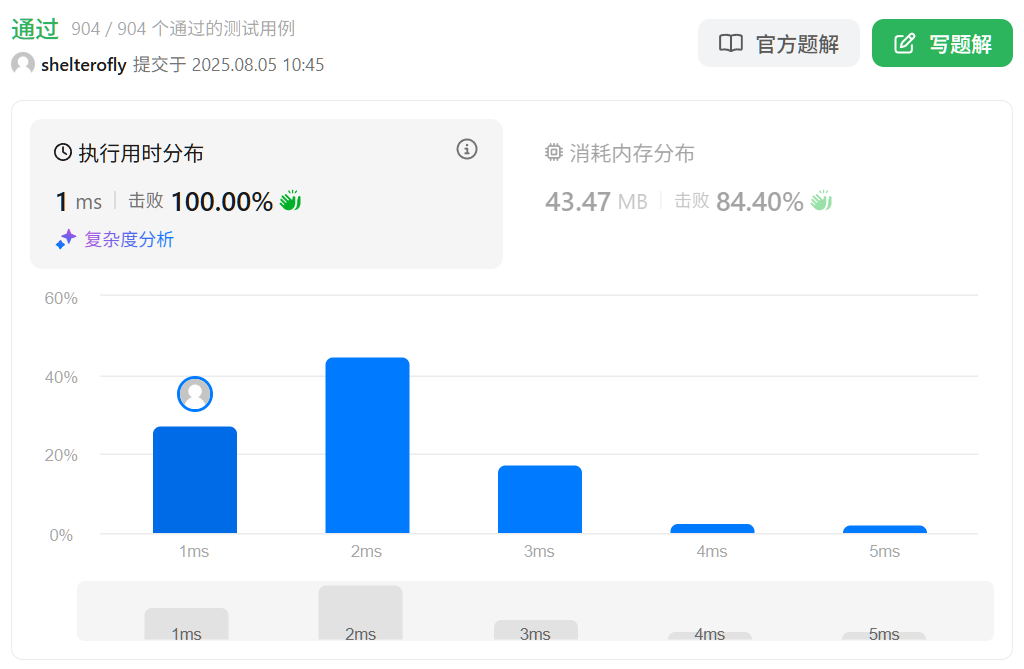
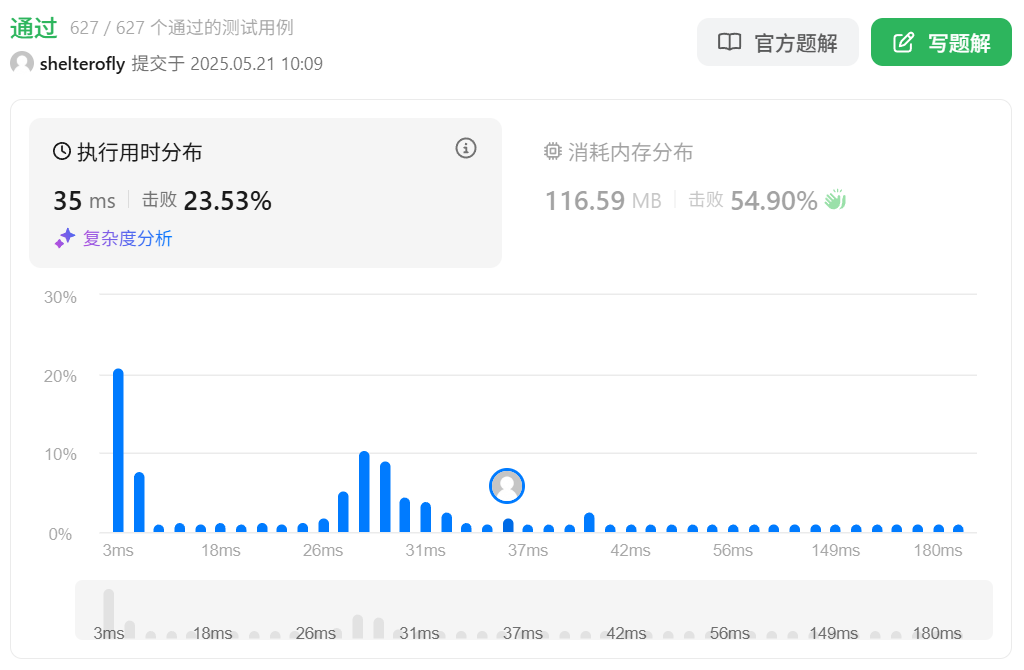
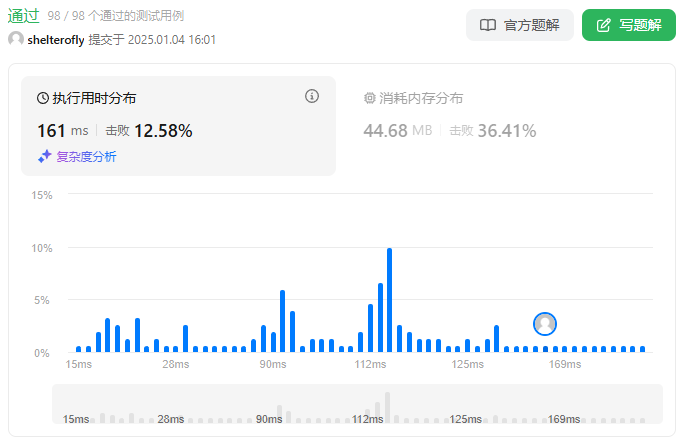
性能