目标
请你设计一个数据结构来高效管理网络路由器中的数据包。每个数据包包含以下属性:
- source:生成该数据包的机器的唯一标识符。
- destination:目标机器的唯一标识符。
- timestamp:该数据包到达路由器的时间戳。
实现 Router 类:
Router(int memoryLimit):初始化路由器对象,并设置固定的内存限制。
- memoryLimit 是路由器在任意时间点可以存储的 最大 数据包数量。
- 如果添加一个新数据包会超过这个限制,则必须移除 最旧的 数据包以腾出空间。
bool addPacket(int source, int destination, int timestamp):将具有给定属性的数据包添加到路由器。
- 如果路由器中已经存在一个具有相同 source、destination 和 timestamp 的数据包,则视为重复数据包。
- 如果数据包成功添加(即不是重复数据包),返回 true;否则返回 false。
int[] forwardPacket():以 FIFO(先进先出)顺序转发下一个数据包。
- 从存储中移除该数据包。
- 以数组 [source, destination, timestamp] 的形式返回该数据包。
- 如果没有数据包可以转发,则返回空数组。
int getCount(int destination, int startTime, int endTime):
- 返回当前存储在路由器中(即尚未转发)的,且目标地址为指定 destination 且时间戳在范围 [startTime, endTime](包括两端)内的数据包数量。
注意:对于 addPacket 的查询会按照 timestamp 的递增顺序进行。
示例 1:
输入:
["Router", "addPacket", "addPacket", "addPacket", "addPacket", "addPacket", "forwardPacket", "addPacket", "getCount"]
[[3], [1, 4, 90], [2, 5, 90], [1, 4, 90], [3, 5, 95], [4, 5, 105], [], [5, 2, 110], [5, 100, 110]]
输出:
[null, true, true, false, true, true, [2, 5, 90], true, 1]
解释:
Router router = new Router(3); // 初始化路由器,内存限制为 3。
router.addPacket(1, 4, 90); // 数据包被添加,返回 True。
router.addPacket(2, 5, 90); // 数据包被添加,返回 True。
router.addPacket(1, 4, 90); // 这是一个重复数据包,返回 False。
router.addPacket(3, 5, 95); // 数据包被添加,返回 True。
router.addPacket(4, 5, 105); // 数据包被添加,[1, 4, 90] 被移除,因为数据包数量超过限制,返回 True。
router.forwardPacket(); // 转发数据包 [2, 5, 90] 并将其从路由器中移除。
router.addPacket(5, 2, 110); // 数据包被添加,返回 True。
router.getCount(5, 100, 110); // 唯一目标地址为 5 且时间在 [100, 110] 范围内的数据包是 [4, 5, 105],返回 1。
示例 2:
输入:
["Router", "addPacket", "forwardPacket", "forwardPacket"]
[[2], [7, 4, 90], [], []]
输出:
[null, true, [7, 4, 90], []]
解释:
Router router = new Router(2); // 初始化路由器,内存限制为 2。
router.addPacket(7, 4, 90); // 返回 True。
router.forwardPacket(); // 返回 [7, 4, 90]。
router.forwardPacket(); // 没有数据包可以转发,返回 []。
说明:
- 2 <= memoryLimit <= 10^5
- 1 <= source, destination <= 2 * 10^5
- 1 <= timestamp <= 10^9
- 1 <= startTime <= endTime <= 10^9
- addPacket、forwardPacket 和 getCount 方法的总调用次数最多为 10^5。
- 对于 addPacket 的查询,timestamp 按递增顺序给出。
思路
//todo
代码
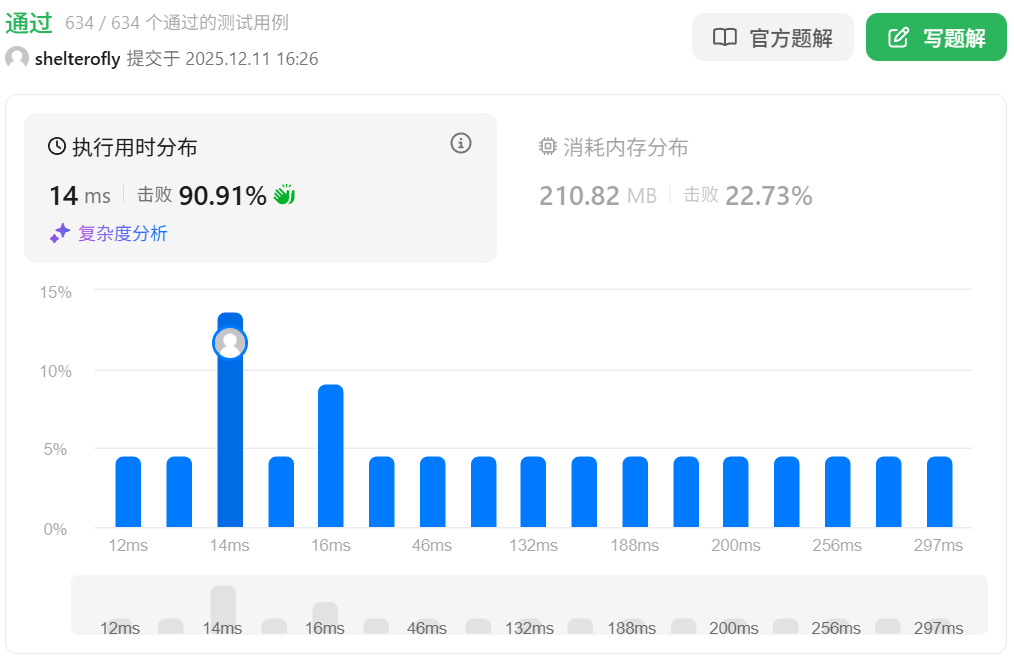
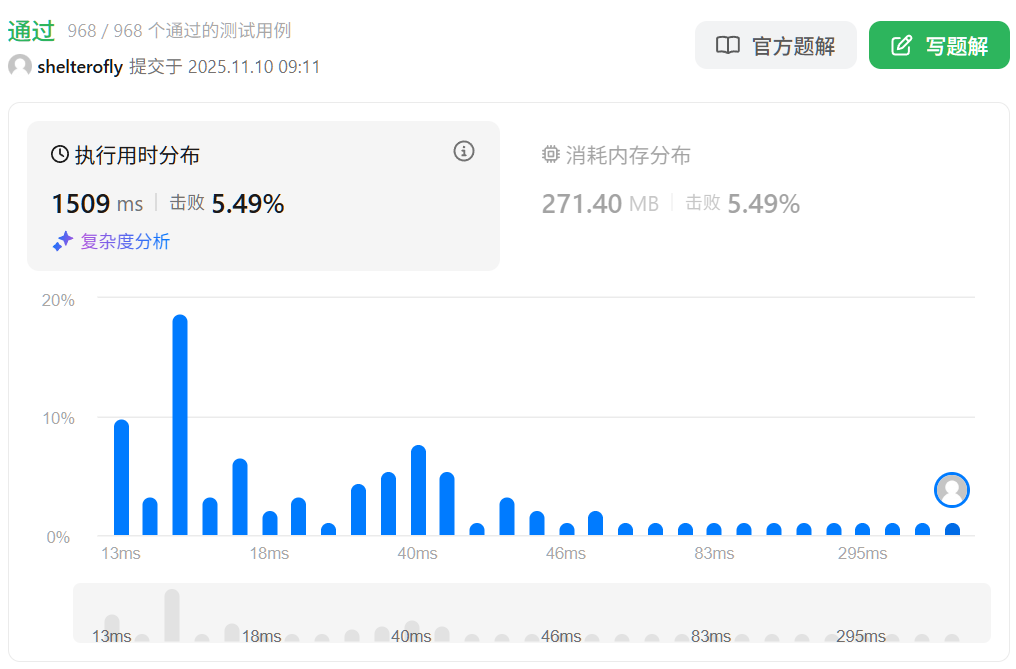
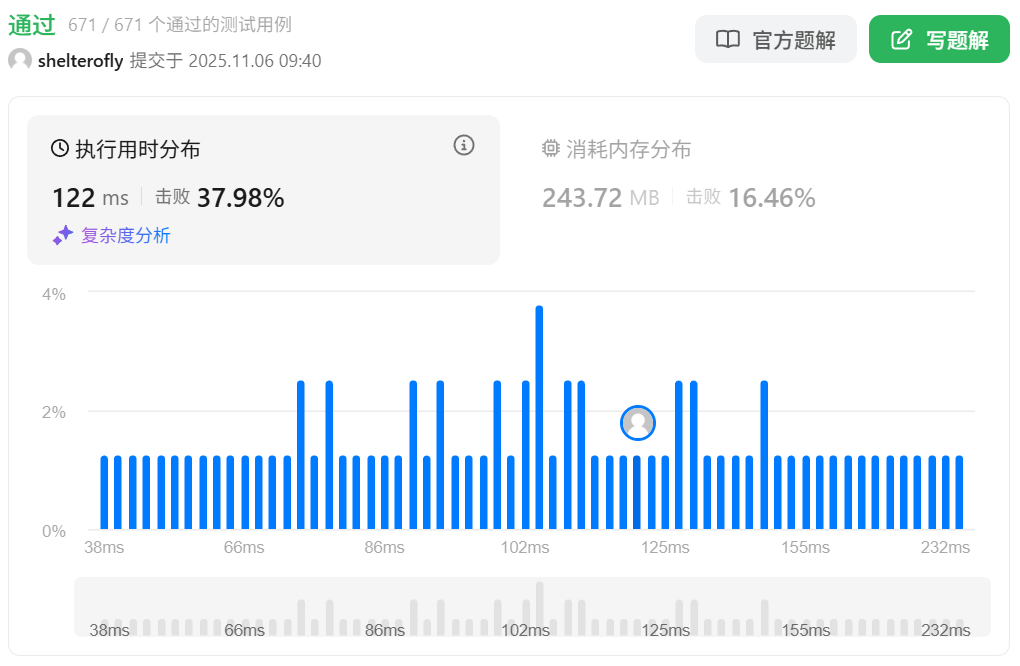
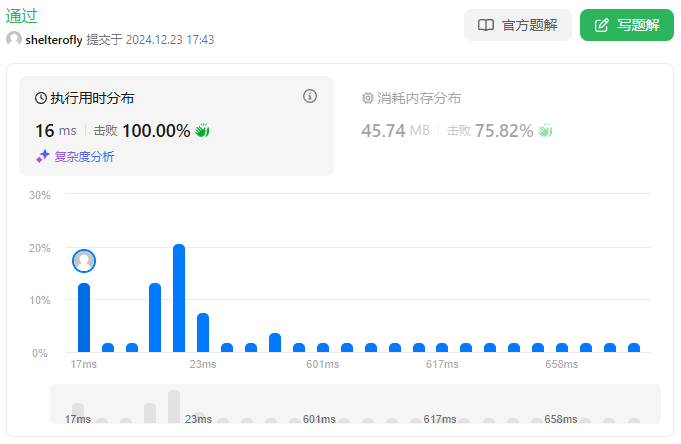
性能