目标
你有 n 台电脑。给你整数 n 和一个下标从 0 开始的整数数组 batteries ,其中第 i 个电池可以让一台电脑 运行 batteries[i] 分钟。你想使用这些电池让 全部 n 台电脑 同时 运行。
一开始,你可以给每台电脑连接 至多一个电池 。然后在任意整数时刻,你都可以将一台电脑与它的电池断开连接,并连接另一个电池,你可以进行这个操作 任意次 。新连接的电池可以是一个全新的电池,也可以是别的电脑用过的电池。断开连接和连接新的电池不会花费任何时间。
注意,你不能给电池充电。
请你返回你可以让 n 台电脑同时运行的 最长 分钟数。
示例 1:

输入:n = 2, batteries = [3,3,3]
输出:4
解释:
一开始,将第一台电脑与电池 0 连接,第二台电脑与电池 1 连接。
2 分钟后,将第二台电脑与电池 1 断开连接,并连接电池 2 。注意,电池 0 还可以供电 1 分钟。
在第 3 分钟结尾,你需要将第一台电脑与电池 0 断开连接,然后连接电池 1 。
在第 4 分钟结尾,电池 1 也被耗尽,第一台电脑无法继续运行。
我们最多能同时让两台电脑同时运行 4 分钟,所以我们返回 4 。示例 2:
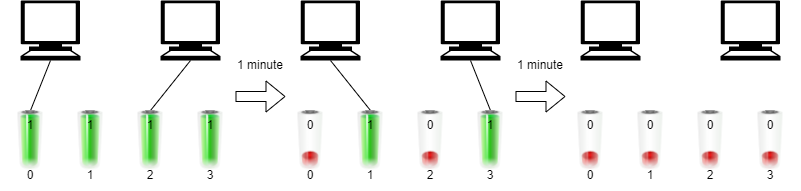
输入:n = 2, batteries = [1,1,1,1]
输出:2
解释:
一开始,将第一台电脑与电池 0 连接,第二台电脑与电池 2 连接。
一分钟后,电池 0 和电池 2 同时耗尽,所以你需要将它们断开连接,并将电池 1 和第一台电脑连接,电池 3 和第二台电脑连接。
1 分钟后,电池 1 和电池 3 也耗尽了,所以两台电脑都无法继续运行。
我们最多能让两台电脑同时运行 2 分钟,所以我们返回 2 。说明:
- 1 <= n <= batteries.length <= 10^5
- 1 <= batteries[i] <= 10^9
思路
有 m 个电池,batteries[i] 表示第 i 个电池的电量,将电池分成 n 组,要求每组电池电量和的最小值最大。
贪心的做法是找到上界 x = sum / n,从大到小遍历电池容量:
- 如果大于
x,超过的部分也不能再使用了,因为一个电池在同一时间只能为一台电池供电,问题规模缩小,sum -= batteries[i],n--。 - 如果小于等于
x,可以用完了再接上下一个电池,不会出现一个电池供两台电脑的情况,因为如果出现这种情况,总是可以将其放到一台的末尾与一台的开头将它们错开。
代码
/**
* @date 2025-12-01 8:57
*/
public class MaxRunTime2141 {
public long maxRunTime(int n, int[] batteries) {
long sum = 0L;
for (int battery : batteries) {
sum += battery;
}
Arrays.sort(batteries);
int m = batteries.length;
for (int i = m - 1; i >= 0; i--) {
long x = sum / n;
if (batteries[i] <= x) {
return x;
}
sum -= batteries[i];
n--;
}
return -1;
}
}
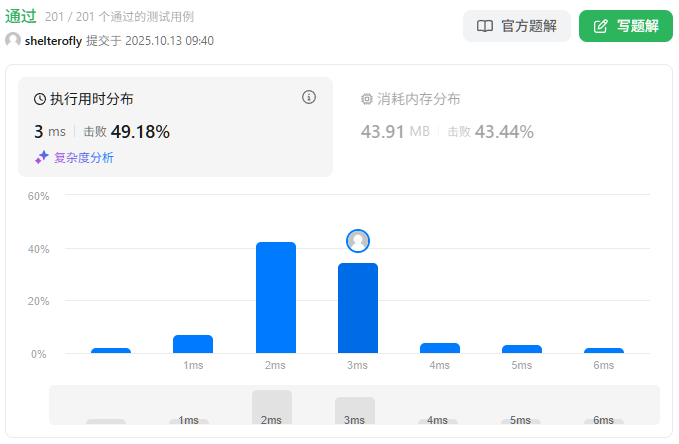
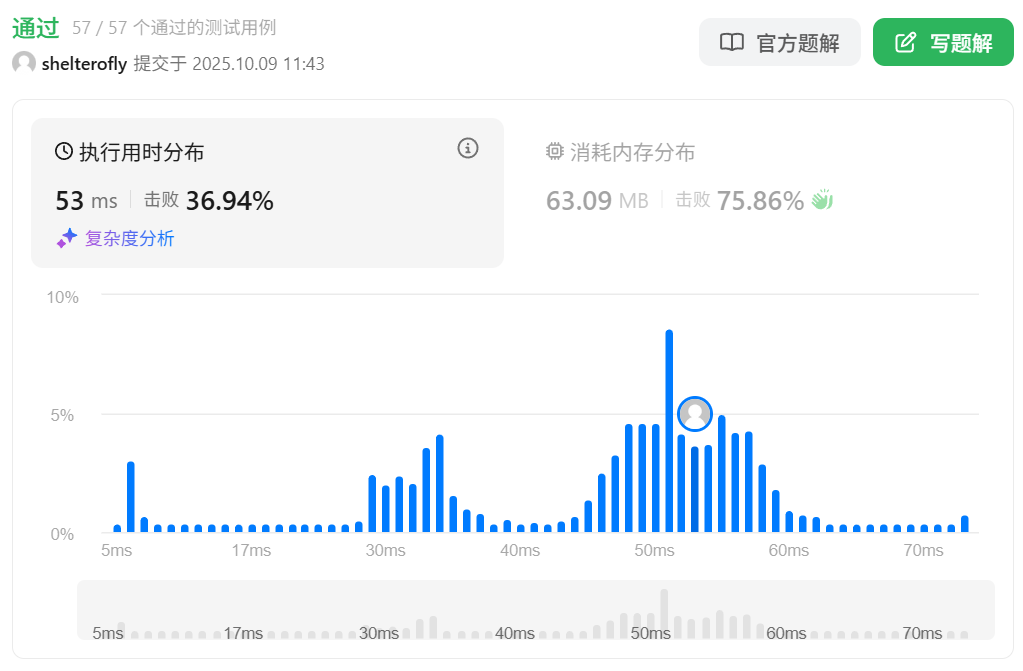
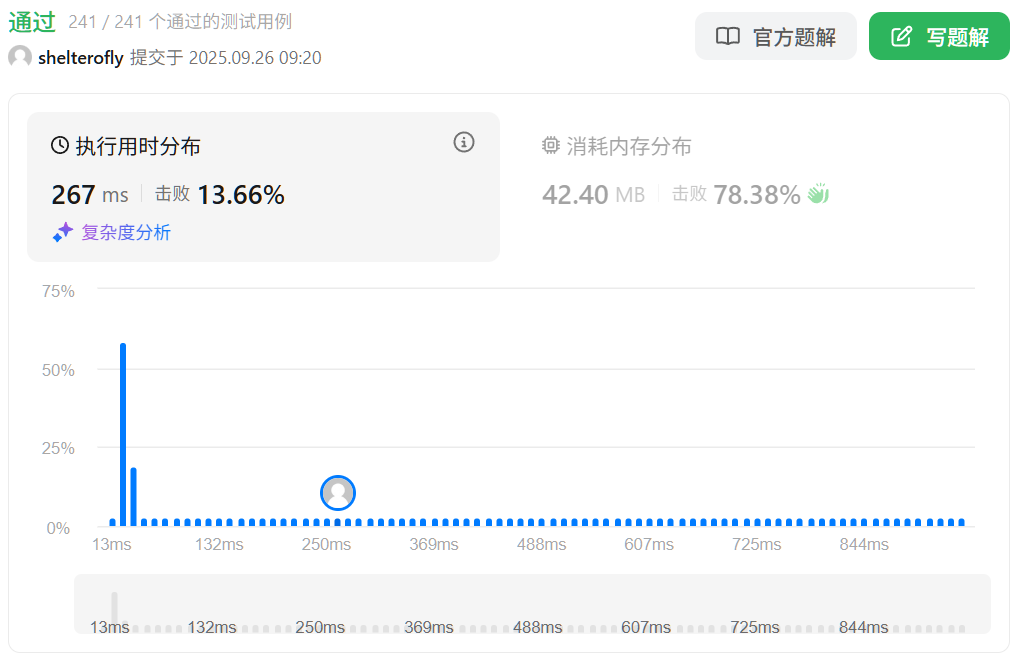
性能