目标
有一根长度为 n 个单位的木棍,棍上从 0 到 n 标记了若干位置。例如,长度为 6 的棍子可以标记如下:
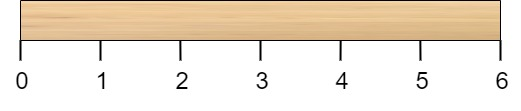
给你一个整数数组 cuts ,其中 cuts[i] 表示你需要将棍子切开的位置。
你可以按顺序完成切割,也可以根据需要更改切割的顺序。
每次切割的成本都是当前要切割的棍子的长度,切棍子的总成本是历次切割成本的总和。对棍子进行切割将会把一根木棍分成两根较小的木棍(这两根木棍的长度和就是切割前木棍的长度)。请参阅第一个示例以获得更直观的解释。
返回切棍子的 最小总成本 。
示例 1:
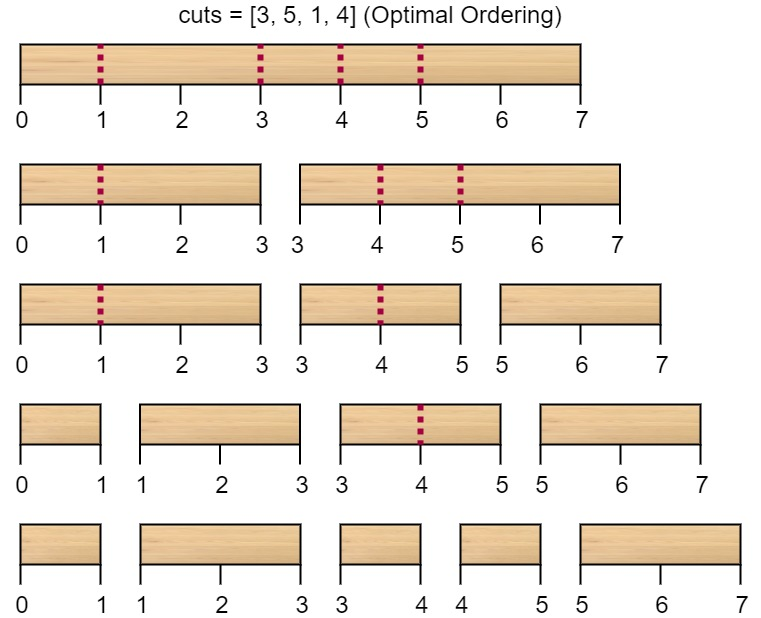
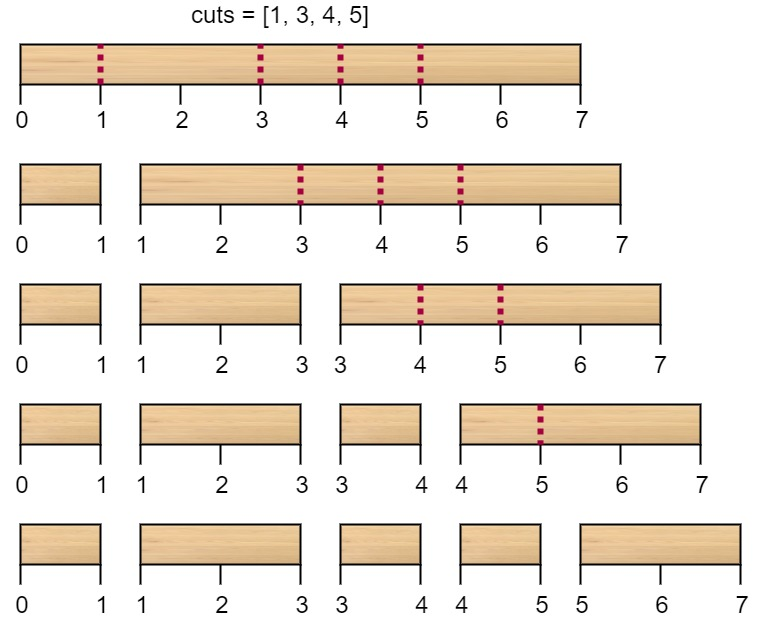
输入:n = 7, cuts = [1,3,4,5]
输出:16
解释:按 [1, 3, 4, 5] 的顺序切割的情况如下所示:
第一次切割长度为 7 的棍子,成本为 7 。第二次切割长度为 6 的棍子(即第一次切割得到的第二根棍子),第三次切割为长度 4 的棍子,最后切割长度为 3 的棍子。总成本为 7 + 6 + 4 + 3 = 20 。
而将切割顺序重新排列为 [3, 5, 1, 4] 后,总成本 = 16(如示例图中 7 + 4 + 3 + 2 = 16)。示例 2:
输入:n = 9, cuts = [5,6,1,4,2]
输出:22
解释:如果按给定的顺序切割,则总成本为 25 。总成本 <= 25 的切割顺序很多,例如,[4, 6, 5, 2, 1] 的总成本 = 22,是所有可能方案中成本最小的。说明:
- 2 <= n <= 10^6
- 1 <= cuts.length <= min(n - 1, 100)
- 1 <= cuts[i] <= n - 1
- cuts 数组中的所有整数都 互不相同
提示:
- Build a dp array where
dp[i][j]is the minimum cost to achieve all the cuts between i and j. - When you try to get the minimum cost between i and j, try all possible cuts k between them,
dp[i][j] = min(dp[i][k] + dp[k][j]) + (j - i)for all possible cuts k between them.
思路
有一个长度为 n 的木棍,刻度从 0 ~ n,有一个整数数组 cuts,cuts[i] 表示需要在刻度 i 处进行切割,切割的成本为该刻度所在棍子的长度,求切割棍子的最小成本。
许多算法书上引入动态规划经常举的一个例子是钢条切割问题。已知特定长度钢条的价值,问怎样切可以使价值最大。而本题是给出必须要切的点,问按照什么顺序切成本最小。
定义 dp[i][j] 表示完成 (i, j) 之间所有切割点所需要的最小成本,dp[0][n] 就是答案。状态转移方程为 dp[i][j] = min(dp[i][k] + dp[k][j]) + j - i)。根据定义 dp 数组应该初始化为 0,因为无法切割时成本为 0。
但是由于切割点的范围太大 2 ~ 10^6,如果直接定义的话会超出内存限制。可以先将切割点排序,定义 i,j 为切点的下标,切点个数 m 最大为 100,时间复杂度为 O(m^3)。
考虑到切点本身不包含木棍的两个端点 0 和 n,我们定义端点 endpoint 数组,将这两个端点加进来,dp[0][m - 1] 即为所求。状态转移方程为 dp[i][j] = min(dp[i][k] + dp[k][j]) + endpoint[j] - endpoint[i]。
特别需要注意的是 dp 数组的遍历的顺序。当我们计算 dp[i][j] 时需要已经计算出 dp[k][j],枚举起点 i 应该倒序,因为 k > i,同理还需要计算出 dp[i][k],枚举终点 j 应该正序,因为 k > y。枚举 k 正序倒序都可以。
枚举 i,j 的先后顺序也是可以交换的。
代码
/**
* @date 2024-11-11 10:07
*/
public class MinCost1547 {
public int minCost(int n, int[] cuts) {
Arrays.sort(cuts);
int m = cuts.length;
int[] endpoint = new int[m + 2];
System.arraycopy(cuts, 0, endpoint, 1, m);
endpoint[m + 1] = n;
m = endpoint.length;
int[][] dp = new int[m][m];
for (int i = m - 3; i >= 0; i--) {
for (int j = i + 2; j < m; j++) {
int min = Integer.MAX_VALUE;
for (int k = i + 1; k < j; k++) {
min = Math.min(dp[i][k] + dp[k][j], min);
}
dp[i][j] = min + endpoint[j] - endpoint[i];
}
}
return dp[0][m - 1];
}
}
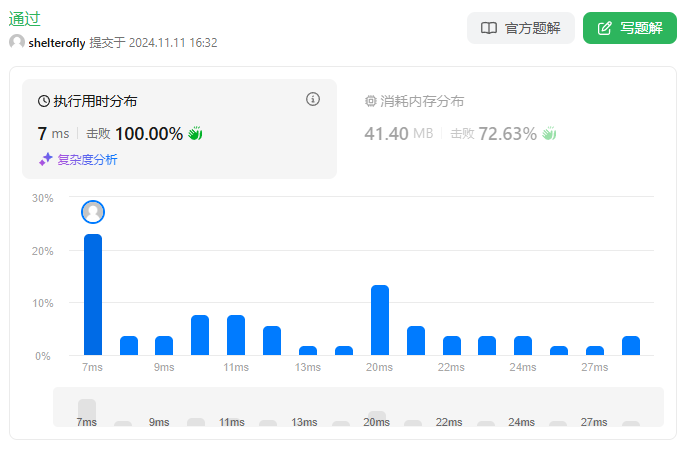
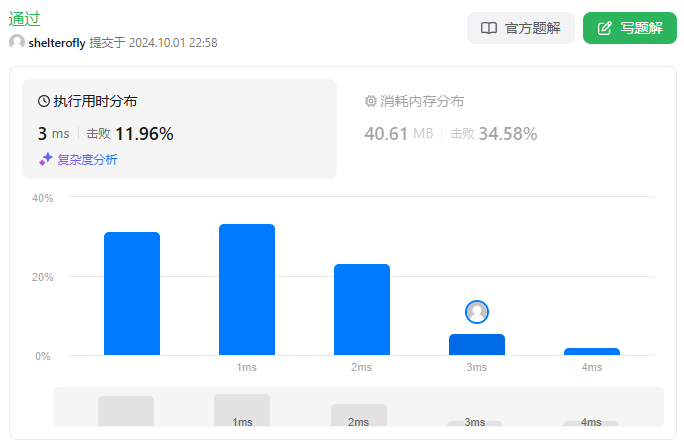
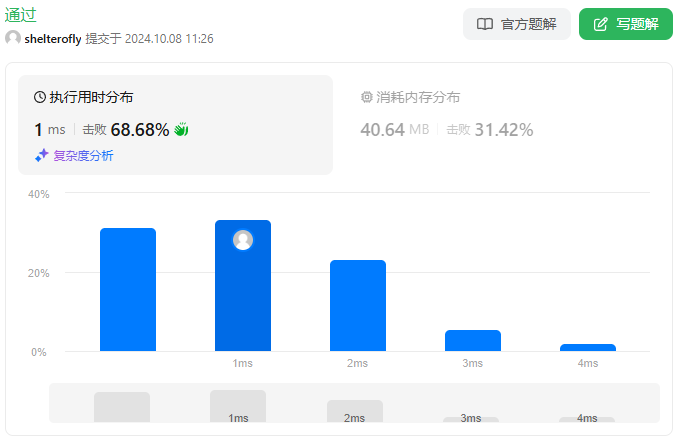
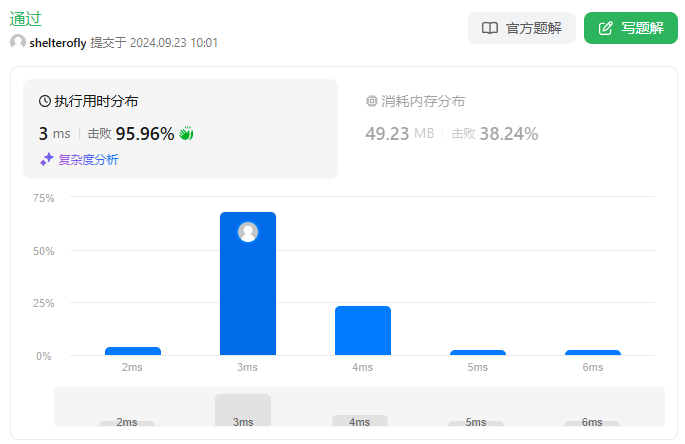
性能