目标
设计一个支持下述操作的食物评分系统:
- 修改 系统中列出的某种食物的评分。
- 返回系统中某一类烹饪方式下评分最高的食物。
实现 FoodRatings 类:
- FoodRatings(String[] foods, String[] cuisines, int[] ratings) 初始化系统。食物由 foods、cuisines 和 ratings 描述,长度均为 n 。
- foods[i] 是第 i 种食物的名字。
- cuisines[i] 是第 i 种食物的烹饪方式。
- ratings[i] 是第 i 种食物的最初评分。
- void changeRating(String food, int newRating) 修改名字为 food 的食物的评分。
- String highestRated(String cuisine) 返回指定烹饪方式 cuisine 下评分最高的食物的名字。如果存在并列,返回 字典序较小 的名字。
注意,字符串 x 的字典序比字符串 y 更小的前提是:x 在字典中出现的位置在 y 之前,也就是说,要么 x 是 y 的前缀,或者在满足 x[i] != y[i] 的第一个位置 i 处,x[i] 在字母表中出现的位置在 y[i] 之前。
示例:
输入
["FoodRatings", "highestRated", "highestRated", "changeRating", "highestRated", "changeRating", "highestRated"]
[[["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]], ["korean"], ["japanese"], ["sushi", 16], ["japanese"], ["ramen", 16], ["japanese"]]
输出
[null, "kimchi", "ramen", null, "sushi", null, "ramen"]
解释
FoodRatings foodRatings = new FoodRatings(["kimchi", "miso", "sushi", "moussaka", "ramen", "bulgogi"], ["korean", "japanese", "japanese", "greek", "japanese", "korean"], [9, 12, 8, 15, 14, 7]);
foodRatings.highestRated("korean"); // 返回 "kimchi"
// "kimchi" 是分数最高的韩式料理,评分为 9 。
foodRatings.highestRated("japanese"); // 返回 "ramen"
// "ramen" 是分数最高的日式料理,评分为 14 。
foodRatings.changeRating("sushi", 16); // "sushi" 现在评分变更为 16 。
foodRatings.highestRated("japanese"); // 返回 "sushi"
// "sushi" 是分数最高的日式料理,评分为 16 。
foodRatings.changeRating("ramen", 16); // "ramen" 现在评分变更为 16 。
foodRatings.highestRated("japanese"); // 返回 "ramen"
// "sushi" 和 "ramen" 的评分都是 16 。
// 但是,"ramen" 的字典序比 "sushi" 更小。说明:
- 1 <= n <= 2 * 10^4
- n == foods.length == cuisines.length == ratings.length
- 1 <= foods[i].length, cuisines[i].length <= 10
- foods[i]、cuisines[i] 由小写英文字母组成
- 1 <= ratings[i] <= 10^8
- foods 中的所有字符串 互不相同
- 在对 changeRating 的所有调用中,food 是系统中食物的名字。
- 在对 highestRated 的所有调用中,cuisine 是系统中 至少一种 食物的烹饪方式。
- 最多调用 changeRating 和 highestRated 总计 2 * 10^4 次
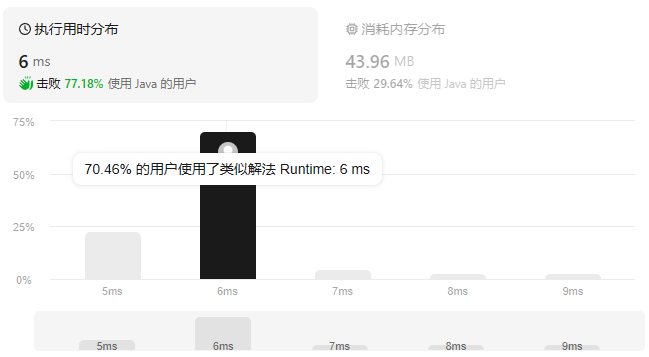
思路
设计一个食物评分系统,返回指定类别评分最高的食物,支持修改食物的评分。
要知道类别中评分最高的食物,优先队列/TreeSet 的元素应为 (rating, food) 键值对,根据评分从大到小排序,如果评分相同根据食物的字典序排列。
修改食物评分后需要更新对应类别的评分排名,因此需要维护 (food, cuisine) 的映射关系。如果使用懒加载,还需要记录食物最新的评分,维护 (food, rating)。如果使用红黑树,需要根据更新前的评分删除树中数据,同样需要维护 (food, rating)。
有人使用优先队列超时是因为删除元素的复杂度是 O(n)。考虑使用懒删除或者使用 有序集合 TreeSet。有序集合查找最大/最小节点的复杂度是 O(logn),最大/小节点是最右/左叶子节点,查找复杂度是树的高度。
代码
/**
* @date 2025-02-28 0:10
*/
public class FoodRatings {
Map<String, PriorityQueue<String[]>> map;
Map<String, String> foodMap;
Map<String, Integer> ratingMap;
public FoodRatings(String[] foods, String[] cuisines, int[] ratings) {
int n = foods.length;
map = new HashMap<>(n);
foodMap = new HashMap<>(n);
ratingMap = new HashMap<>(n);
for (int i = 0; i < n; i++) {
foodMap.put(foods[i], cuisines[i]);
ratingMap.put(foods[i], ratings[i]);
map.putIfAbsent(cuisines[i], new PriorityQueue<>((a, b) -> {
int compare = Integer.parseInt(b[0]) - Integer.parseInt(a[0]);
if (compare != 0) {
return compare;
}
return a[1].compareTo(b[1]);
}));
map.get(cuisines[i]).offer(new String[]{String.valueOf(ratings[i]), foods[i]});
}
}
public void changeRating(String food, int newRating) {
ratingMap.put(food, newRating);
map.get(foodMap.get(food)).offer(new String[]{String.valueOf(newRating), food});
}
public String highestRated(String cuisine) {
PriorityQueue<String[]> q = map.get(cuisine);
while (Integer.parseInt(q.peek()[0]) != ratingMap.get(q.peek()[1])) {
q.poll();
}
return q.peek()[1];
}
}
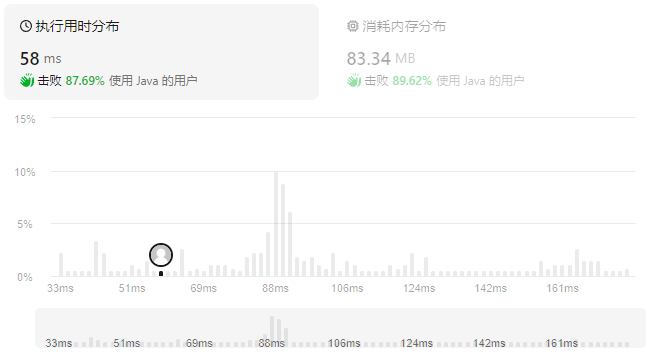
性能