目标
一个酒店里有 n 个房间,这些房间用二维整数数组 rooms 表示,其中 rooms[i] = [roomIdi, sizei] 表示有一个房间号为 roomIdi 的房间且它的面积为 sizei 。每一个房间号 roomIdi 保证是 独一无二 的。
同时给你 k 个查询,用二维数组 queries 表示,其中 queries[j] = [preferredj, minSizej] 。第 j 个查询的答案是满足如下条件的房间 id :
- 房间的面积 至少 为 minSizej ,且
- abs(id - preferredj) 的值 最小 ,其中 abs(x) 是 x 的绝对值。
如果差的绝对值有 相等 的,选择 最小 的 id 。如果 没有满足条件的房间 ,答案为 -1 。
请你返回长度为 k 的数组 answer ,其中 answer[j] 为第 j 个查询的结果。
示例 1:
输入:rooms = [[2,2],[1,2],[3,2]], queries = [[3,1],[3,3],[5,2]]
输出:[3,-1,3]
解释:查询的答案如下:
查询 [3,1] :房间 3 的面积为 2 ,大于等于 1 ,且号码是最接近 3 的,为 abs(3 - 3) = 0 ,所以答案为 3 。
查询 [3,3] :没有房间的面积至少为 3 ,所以答案为 -1 。
查询 [5,2] :房间 3 的面积为 2 ,大于等于 2 ,且号码是最接近 5 的,为 abs(3 - 5) = 2 ,所以答案为 3 。示例 2:
输入:rooms = [[1,4],[2,3],[3,5],[4,1],[5,2]], queries = [[2,3],[2,4],[2,5]]
输出:[2,1,3]
解释:查询的答案如下:
查询 [2,3] :房间 2 的面积为 3 ,大于等于 3 ,且号码是最接近的,为 abs(2 - 2) = 0 ,所以答案为 2 。
查询 [2,4] :房间 1 和 3 的面积都至少为 4 ,答案为 1 因为它房间编号更小。
查询 [2,5] :房间 3 是唯一面积大于等于 5 的,所以答案为 3 。说明:
- n == rooms.length
- 1 <= n <= 10^5
- k == queries.length
- 1 <= k <= 10^4
- 1 <= roomIdi, preferredj <= 10^7
- 1 <= sizei, minSizej <= 10^7
思路
有一个数组 rooms,rooms[i][0] 表示第 i 个房间编号,房间编号不重复,rooms[i][1] 表示第 i 个房间大小。有一个查询数组 queries,queries[j][0] 表示第 j 个查询期望的房间编号,queries[j][1] 表示第 j 个查询最小的房间大小。返回查询数组对应的结果数组,查询结果为房间编号,该房间的面积至少为 queries[j][1],且房间编号与 queries[j][0] 的距离最小,如果存在距离相等的情况,取房间编号最小的。
首先按房间大小排序,大小相同的按编号排序。对于每个查询首先二分查找出第一个大于 queries[j][1] 的房间在数组中的位置,接下来需要从该位置往后计算距离 queries[j][0] 最近的房间编号。
// todo 官网题解 Bentley Ottmann, Sparse Table 倍增 RMQ,Range Maximum/Minimum Query
代码
/**
* @date 2024-12-16 16:23
*/
public class ClosestRoom1847 {
public int[] closestRoom(int[][] rooms, int[][] queries) {
Arrays.sort(rooms, (a, b) -> {
int compare = a[1] - b[1];
if (compare != 0) {
return compare;
}
return a[0] - b[0];
});
int n = rooms.length;
int k = queries.length;
int[] res = new int[k];
int i = 0;
for (int[] query : queries) {
int minAreaRoomIndex = lowerBound(rooms, 0, n - 1, query[1]);
if (minAreaRoomIndex == n) {
res[i++] = -1;
continue;
}
int dist = Integer.MAX_VALUE;
int roomId = Integer.MAX_VALUE;
for (int j = minAreaRoomIndex; j < n; j++) {
int tmp = Math.abs(query[0] - rooms[j][0]);
if (tmp < dist) {
dist = tmp;
roomId = rooms[j][0];
} else if (tmp == dist) {
roomId = Math.min(rooms[j][0], roomId);
}
}
res[i++] = roomId;
}
return res;
}
public int lowerBound(int[][] rooms, int l, int r, int target) {
int m = l + ((r - l) >> 1);
while (l <= r) {
if (rooms[m][1] >= target) {
r = m - 1;
} else {
l = m + 1;
}
m = l + ((r - l) >> 1);
}
return l;
}
}
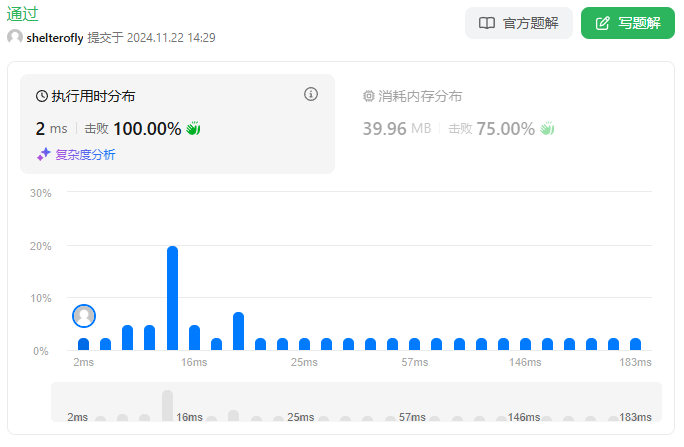
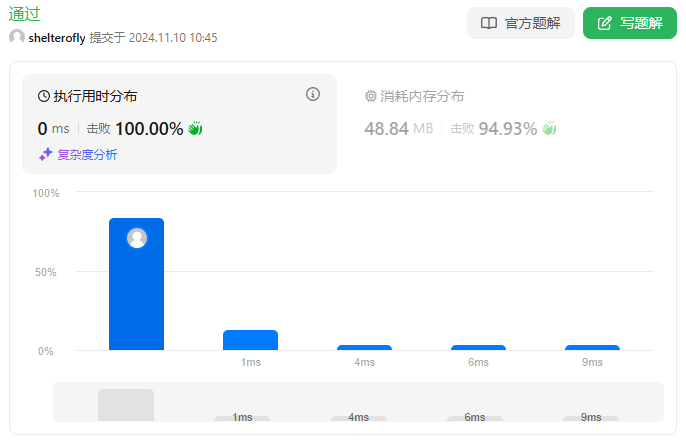
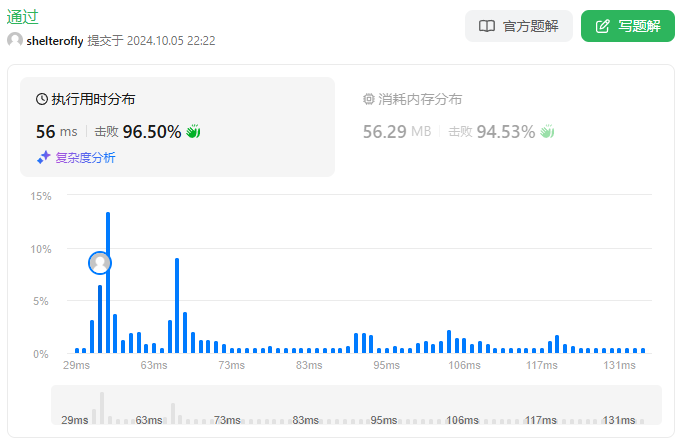
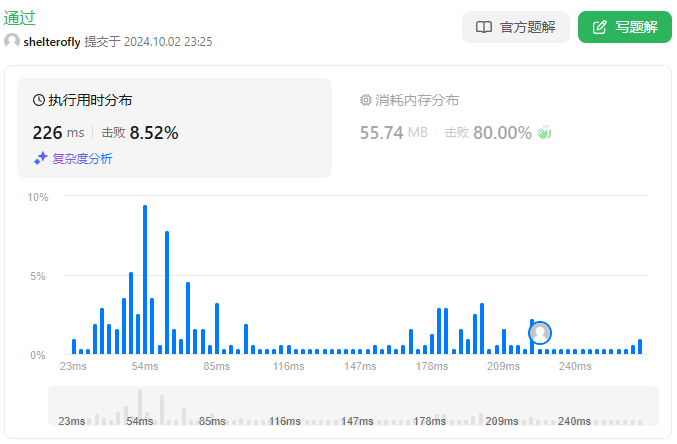
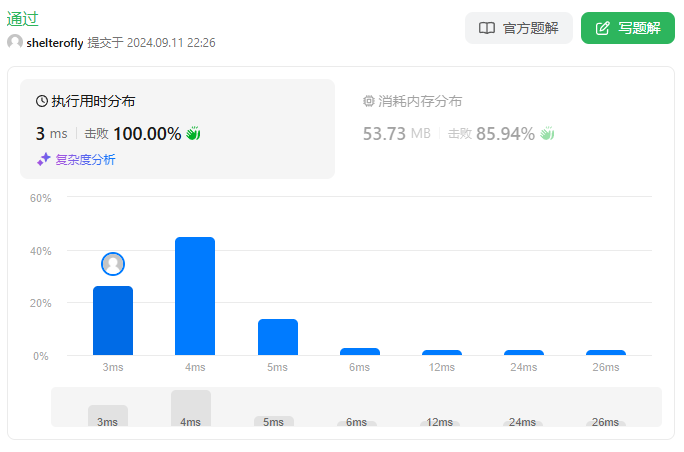
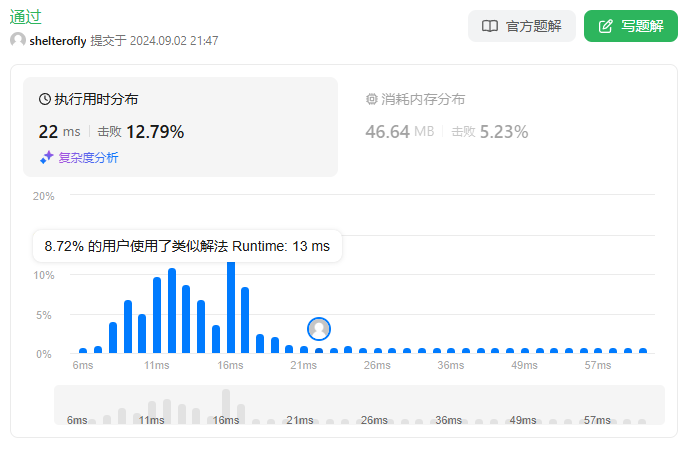
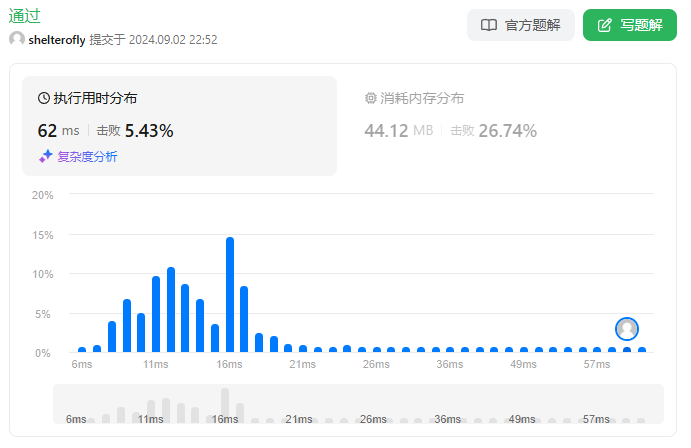
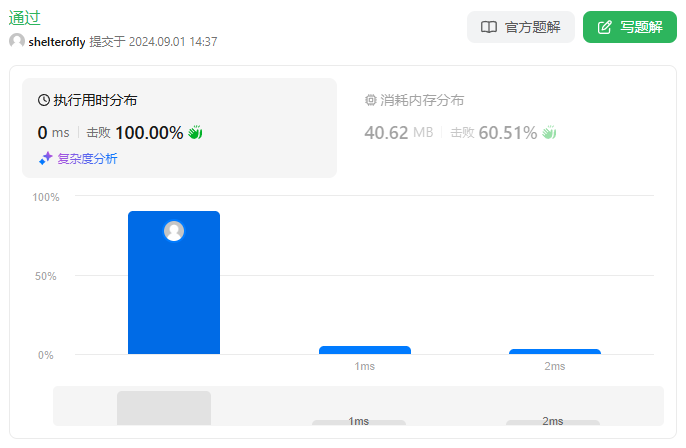
性能