目标
排排坐,分糖果。
我们买了一些糖果 candies,打算把它们分给排好队的 n = num_people 个小朋友。
给第一个小朋友 1 颗糖果,第二个小朋友 2 颗,依此类推,直到给最后一个小朋友 n 颗糖果。
然后,我们再回到队伍的起点,给第一个小朋友 n + 1 颗糖果,第二个小朋友 n + 2 颗,依此类推,直到给最后一个小朋友 2 * n 颗糖果。
重复上述过程(每次都比上一次多给出一颗糖果,当到达队伍终点后再次从队伍起点开始),直到我们分完所有的糖果。注意,就算我们手中的剩下糖果数不够(不比前一次发出的糖果多),这些糖果也会全部发给当前的小朋友。
返回一个长度为 num_people、元素之和为 candies 的数组,以表示糖果的最终分发情况(即 ans[i] 表示第 i 个小朋友分到的糖果数)。
示例 1:
输入:candies = 7, num_people = 4
输出:[1,2,3,1]
解释:
第一次,ans[0] += 1,数组变为 [1,0,0,0]。
第二次,ans[1] += 2,数组变为 [1,2,0,0]。
第三次,ans[2] += 3,数组变为 [1,2,3,0]。
第四次,ans[3] += 1(因为此时只剩下 1 颗糖果),最终数组变为 [1,2,3,1]。
示例 2:
输入:candies = 10, num_people = 3
输出:[5,2,3]
解释:
第一次,ans[0] += 1,数组变为 [1,0,0]。
第二次,ans[1] += 2,数组变为 [1,2,0]。
第三次,ans[2] += 3,数组变为 [1,2,3]。
第四次,ans[0] += 4,最终数组变为 [5,2,3]。
说明:
- 1 <= candies <= 10^9
- 1 <= num_people <= 1000
思路
现在有一些糖果要分给一排小朋友,第一个小朋友分1个,第二个分2个,依次类推,即分配的糖果总比上一次分的多一个,如果不够就剩多少分多少。如果一轮下来没有分完,就接着从第一个小朋友开始依次分配。问最终每个小朋友能够分得的糖果数量。
我们可以很容易地模拟这个分配过程,记录当前分配的糖果数量,并计算剩余糖果数量直到0。
网友最快的题解使用了数学公式,使时间复杂度从O(num_people+sqrt(candies)) 降为O(num_people)。
代码
/**
* @date 2024-06-03 0:06
*/
public class DistributeCandies1103 {
public int[] distributeCandies_v1(int candies, int num_people) {
int[] res = new int[num_people];
// 足量发放人次,解不等式:(n+1)n/2 <= candies
int n = (int) ((Math.sqrt(candies * 8F + 1) - 1) / 2);
// 足量发放的糖果数量,num_people <= 1000,其实不会溢出
int distributed = (int) ((1L + n) * n / 2);
// 剩余糖数量
int remainder = candies - distributed;
// 所有小朋友都得到糖果的轮次
int allGetLoops = n / num_people;
// 最后一轮获得糖果的人数
int lastLoopNum = n % num_people;
for (int i = 0; i < num_people; i++) {
// 收到糖果的次数 = 所有小朋友都得到糖果的轮次 + 最后一轮是否发放
int times = (lastLoopNum > i ? 1 : 0) + allGetLoops;
// 等差数列求和,公差为 num_people,a1 = i + 1,n = times;
res[i] = ((times - 1) * num_people + i * 2 + 2) * times / 2;
}
// 如果是最后一个,将剩余的全部分配
res[lastLoopNum] += remainder;
return res;
}
public int[] distributeCandies(int candies, int num_people) {
int[] res = new int[num_people];
int cnt = 1;
while (candies > 0) {
for (int i = 0; i < num_people && candies > 0; i++) {
int num = Math.min(cnt++, candies);
candies -= num;
res[i] += num;
}
}
return res;
}
}
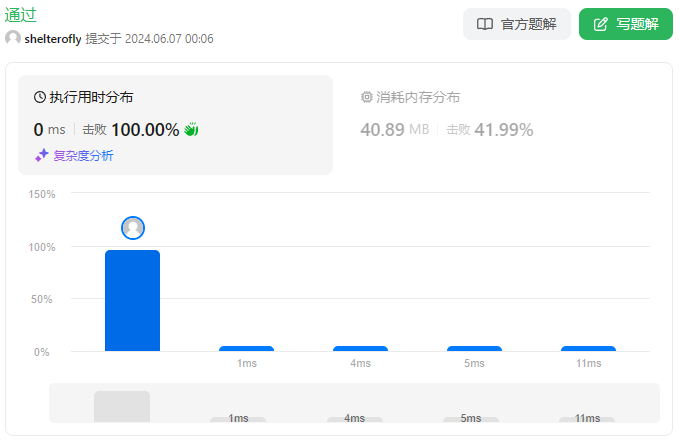
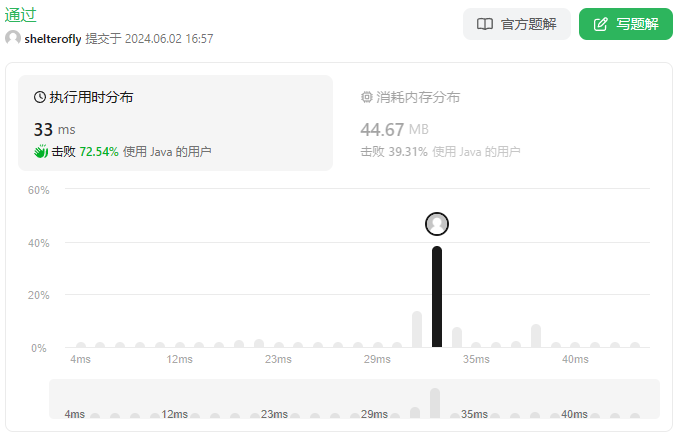
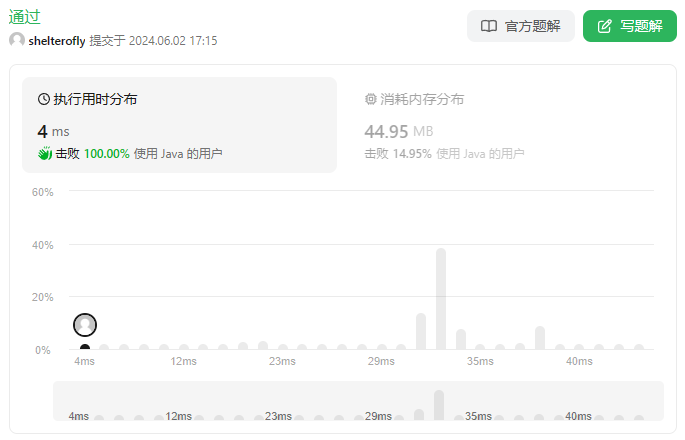
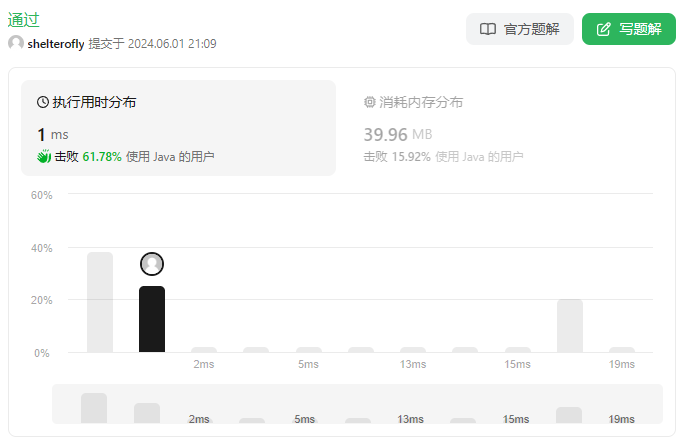
性能