目标
给你一个下标从 0 开始的二维整数数组 nums 表示汽车停放在数轴上的坐标。对于任意下标 i,nums[i] = [starti, endi] ,其中 starti 是第 i 辆车的起点,endi 是第 i 辆车的终点。
返回数轴上被车 任意部分 覆盖的整数点的数目。
示例 1:
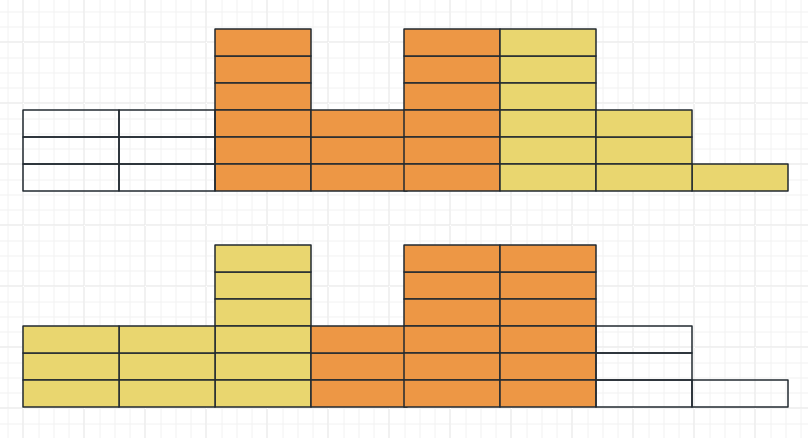
输入:nums = [[3,6],[1,5],[4,7]]
输出:7
解释:从 1 到 7 的所有点都至少与一辆车相交,因此答案为 7 。示例 2:
输入:nums = [[1,3],[5,8]]
输出:7
解释:1、2、3、5、6、7、8 共计 7 个点满足至少与一辆车相交,因此答案为 7 。说明:
- 1 <= nums.length <= 100
- nums[i].length == 2
- 1 <= starti <= endi <= 100
思路
用一个二维数组表示 n 个线段,每一行表示线段的两个端点,问这些线段覆盖的整数点个数。
简单的想法是将线段覆盖的每个整数加入 HashSet,最后返回集合大小即可。线段个数最多 100 个,端点的范围在 1 ~ 100 最多10000 次循环,可行。
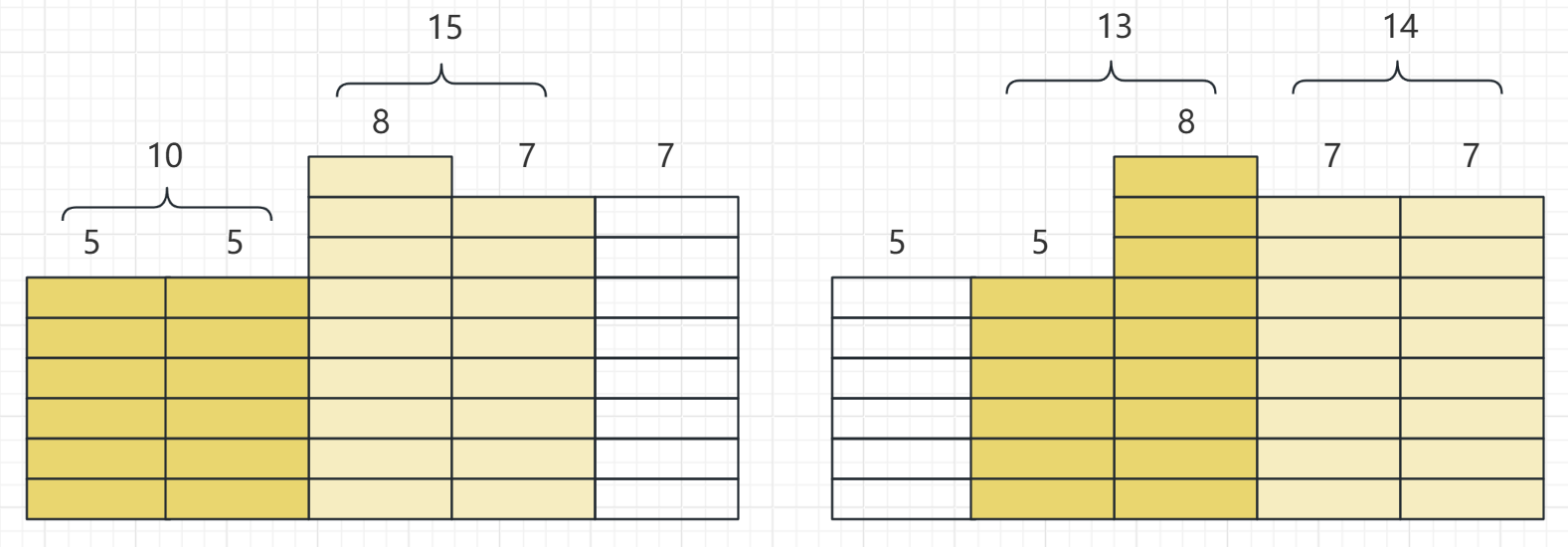
更好的做法是将相交的线段合并,最终仅计算相交线段的长度之和即可。先将线段按照起点排序,如果后面线段的起点小于前面的终点,取当前线段的终点与前面合并线段的终点中的较大值,否则计算长度并累加。
还想到了之前有一道题使用了 差分思想,那个是给定一个整数,判断覆盖该整数的线段有多少个。它是将 cnt[start]++; cnt[end + 1]--,直接累加 [0, query] 内的 cnt[i] 即为答案。
差分数组 diff 的核心思想是记录相邻元素的差,当对连续区间 [i, j] 同时增加 k,可以简化为 diff[i] + k; diff[j + 1] - k。原数组的第 i 个元素可以通过累加差分数组得到。
刚开始理解差分数组可能会想不明白,为什么只修改差分数组两个端点的值就可以将区间内的值同时加 k。核心点是理解当前值是由差分数组累加得来的,从 i 开始,当前值加了 k,后面的差分值为0,因此值与 i 位置相同。当到达 j + 1 减去了 k,后面再累加就不会受到前面的影响。
针对这道题,将原数组视为每个整数点被覆盖的次数,开始时均为 0,差分数组也均为 0。最后只需统计覆盖次数大于 0 的整数个数即可。
代码
/**
* @date 2024-09-15 21:53
*/
public class NumberOfPoints2848 {
/**
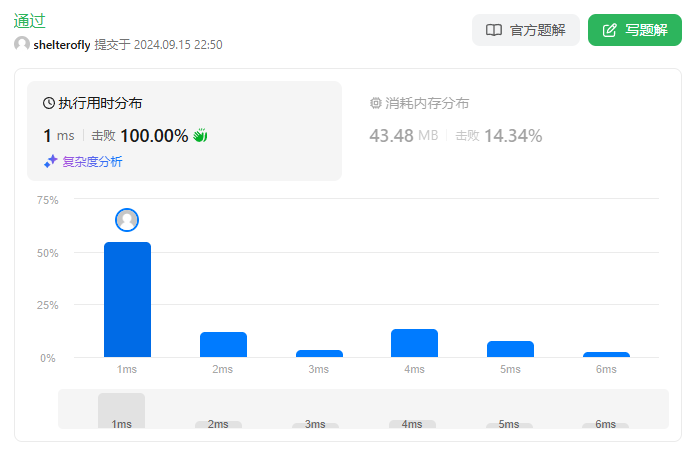
* 差分数组 1ms O(n)
*/
public int numberOfPoints_v2(List<List<Integer>> nums) {
// 数据范围为 1~100,0~100 共101个数,但是由于需要访问 end+1,因此初始化为102个
int[] diff = new int[102];
for (List<Integer> segment : nums) {
diff[segment.get(0)]++;
diff[segment.get(1) + 1]--;
}
int res = 0;
int cnt = 0;
for (int i : diff) {
cnt += i;
if (cnt > 0){
res++;
}
}
return res;
}
/**
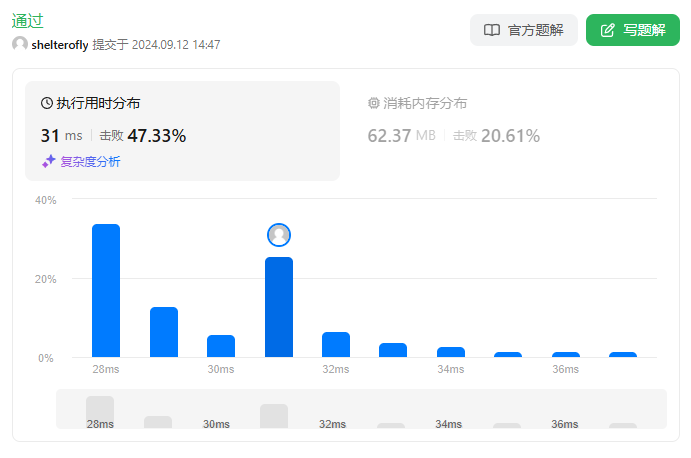
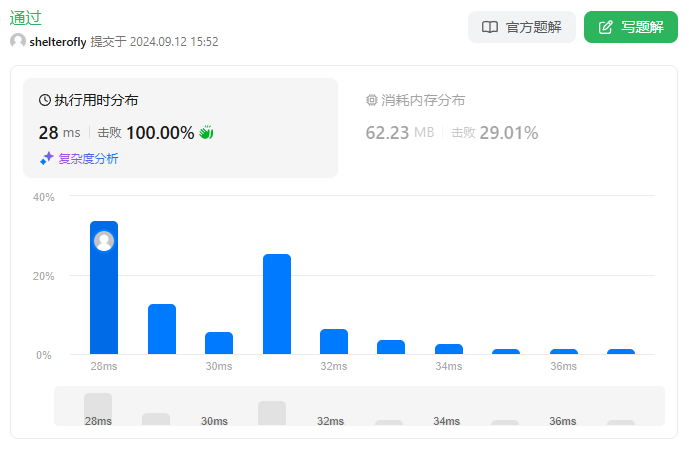
* 合并区间 排序 O(nlogn) 3ms
*/
public int numberOfPoints_v1(List<List<Integer>> nums) {
PriorityQueue<int[]> q = new PriorityQueue<>((a, b) -> a[0] - b[0]);
for (List<Integer> num : nums) {
q.offer(new int[]{num.get(0), num.get(1)});
}
// 初始化为-1,是因为循环中第一次 res += maxEnd - start + 1; start maxEnd并不是实际的线段数据
int res = -1;
int start = 0;
int maxEnd = 0;
while (!q.isEmpty()) {
int[] segment = q.poll();
int s = segment[0];
int e = segment[1];
if (s > maxEnd) {
res += maxEnd - start + 1;
start = s;
maxEnd = e;
} else {
maxEnd = Math.max(maxEnd, e);
}
}
// 如果最后一个线段无需合并,那么需要单独将其长度加进来
// 如果最后一个线段需要合并,由于队列中没有数据了,也需要将最后合并的线段长度加进来
res += maxEnd - start + 1;
return res;
}
/**
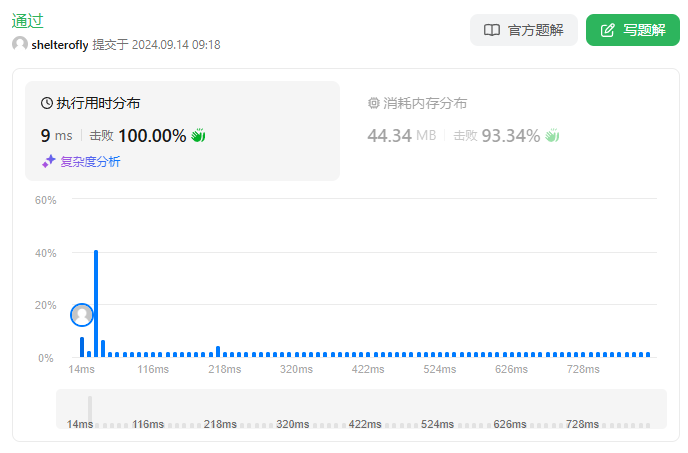
* 5ms O(c*n) c为区间最大长度
*/
public int numberOfPoints(List<List<Integer>> nums) {
Set<Integer> s = new HashSet<>(nums.size());
for (List<Integer> num : nums) {
for (int i = num.get(0); i <= num.get(1); i++) {
s.add(i);
}
}
return s.size();
}
}
性能