目标
给你两个整数 red 和 blue,分别表示红色球和蓝色球的数量。你需要使用这些球来组成一个三角形,满足第 1 行有 1 个球,第 2 行有 2 个球,第 3 行有 3 个球,依此类推。
每一行的球必须是 相同 颜色,且相邻行的颜色必须 不同。
返回可以实现的三角形的 最大 高度。
示例 1:

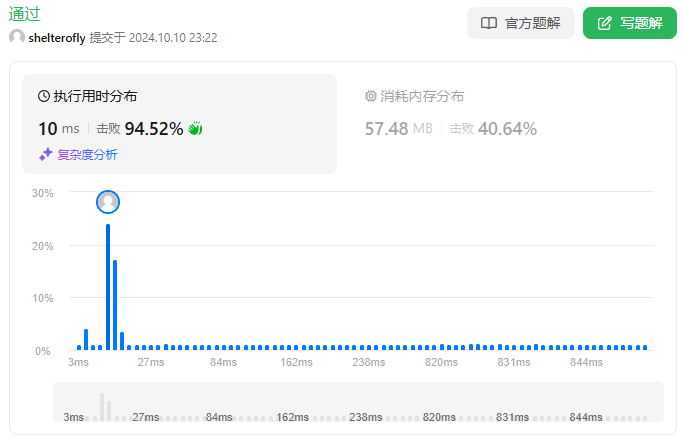
输入: red = 2, blue = 4
输出: 3
解释:
上图显示了唯一可能的排列方式。示例 2:

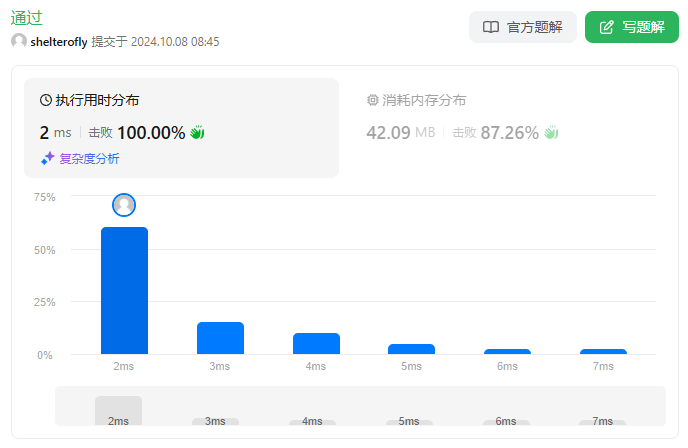
输入: red = 2, blue = 1
输出: 2
解释:
上图显示了唯一可能的排列方式。示例 3:
输入: red = 1, blue = 1
输出: 1示例 4:

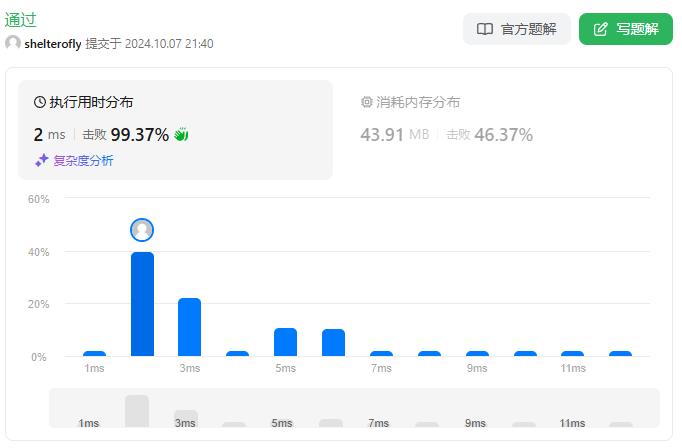
输入: red = 10, blue = 1
输出: 2
解释:
上图显示了唯一可能的排列方式。说明:
- 1 <= red, blue <= 100
思路
有红球 red 个,蓝球 blue 个,使用这两种球组成三角形,要求每一行只能由同一种颜色的球组成,且相邻行球的颜色不同,问三角形的最大高度。
三角形第 i 行球的个数为 i,奇数行的总个数为 1 + 3 + 5 + …… 偶数行的总个数为 2 + 4 + 6 + ……,根据等差数列求和公式,奇数行所需球的总个数为 oddRowCnt^2,偶数行所需球的总个数为 evenRowCnt^2 + evenRowCnt。
假设 red 放在奇数行,代入可得 redOddRowCnt = sqrt(red),如果放在偶数行,则 redEvenRowCnt = (sqrt(1 + 4 * red) - 1) / 2。同理可求出 blueOddRowCnt blueEvenRowCnt。
接下来分两种情况讨论:
- 红色球放第一行:如果
|redOddRowCnt - blueEvenRowCnt| > 1,取Math.min(redOddRowCnt, blueEvenRowCnt) * 2 + 1,否则取Math.min(redOddRowCnt, blueEvenRowCnt) * 2。 - 蓝色球放第一行:如果
|blueOddRowCnt - redEvenRowCnt| > 1,取Math.min(blueOddRowCnt, redEvenRowCnt) * 2 + 1,否则取Math.min(blueOddRowCnt, redEvenRowCnt) * 2。
取上面两种情况的最大值即可。
代码
/**
* @date 2024-10-15 9:25
*/
public class MaxHeightOfTriangle3200 {
public int maxHeightOfTriangle(int red, int blue) {
int redOddRowCnt = (int) Math.sqrt(red);
int redEvenRowCnt = (int) ((Math.sqrt(1 + 4 * red) - 1) / 2);
int blueOddRowCnt = (int) Math.sqrt(blue);
int blueEvenRowCnt = (int) ((Math.sqrt(1 + 4 * blue) - 1) / 2);
int r, b;
if (redOddRowCnt - blueEvenRowCnt >= 1) {
r = 2 * blueEvenRowCnt + 1;
} else {
r = 2 * redOddRowCnt;
}
if (blueOddRowCnt - redEvenRowCnt >= 1) {
b = 2 * redEvenRowCnt + 1;
} else {
b = 2 * blueOddRowCnt;
}
return Math.max(r, b);
}
}
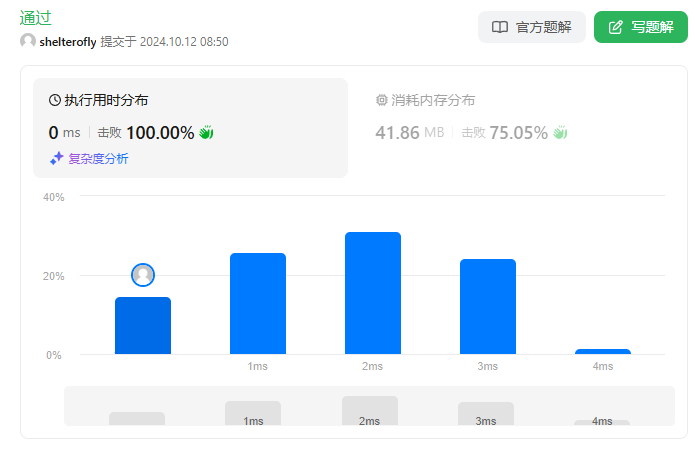
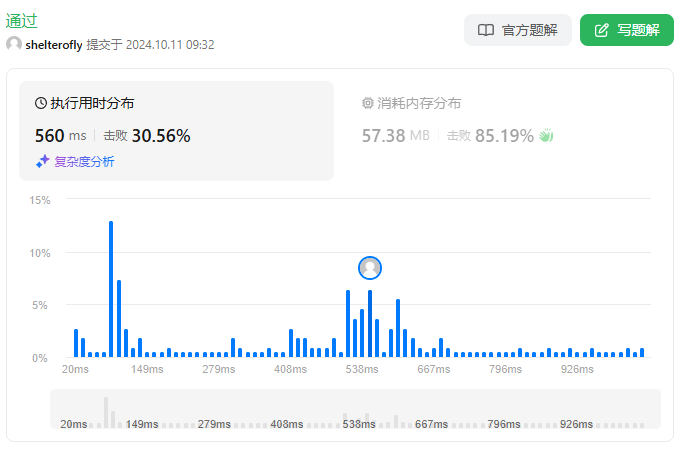
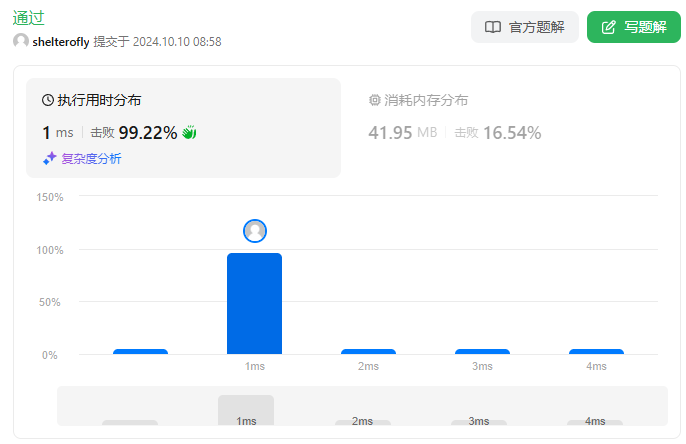
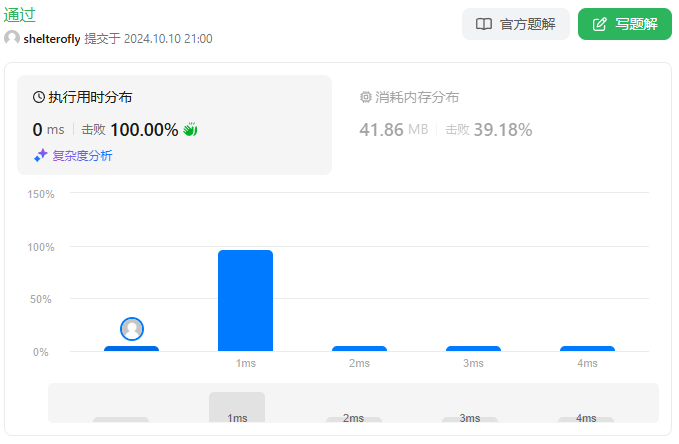
性能