目标
给你一个 二进制 字符串 s 和一个整数 k。
如果一个 二进制字符串 满足以下任一条件,则认为该字符串满足 k 约束:
- 字符串中 0 的数量最多为 k。
- 字符串中 1 的数量最多为 k。
返回一个整数,表示 s 的所有满足 k 约束 的 子字符串 的数量。
示例 1:
输入:s = "10101", k = 1
输出:12
解释:
s 的所有子字符串中,除了 "1010"、"10101" 和 "0101" 外,其余子字符串都满足 k 约束。示例 2:
输入:s = "1010101", k = 2
输出:25
解释:
s 的所有子字符串中,除了长度大于 5 的子字符串外,其余子字符串都满足 k 约束。示例 3:
输入:s = "11111", k = 1
输出:15
解释:
s 的所有子字符串都满足 k 约束。说明:
- 1 <= s.length <= 50
- 1 <= k <= s.length
- s[i] 是 '0' 或 '1'。
思路
定义二进制字符串满足 k 约束的条件是字符串中 0 的个数 或者 1 的个数都不超过 k。求给定字符串满足 k 约束的子字符串数量。子字符串 是字符串中 连续 的 非空 字符序列。
对于非定长滑动窗口,我们可以枚举左端点,扩展右端点;也可以枚举右端点,收缩左端点。对于这个题,我们需要累加的是子数组个数,即以枚举的元素为起点或终点的子数组个数,实际就是区间内元素个数。如果枚举左端点,右端点指向的是不满足条件的点,需要复杂的判断,非常容易出错。因此选择枚举右端点,收缩左端点。
代码
/**
* @date 2024-11-12 9:19
*/
public class CountKConstraintSubstrings3258 {
public int countKConstraintSubstrings(String s, int k) {
int n = s.length();
char[] chars = s.toCharArray();
int[] cnt = new int[2];
int res = 0, l = 0;
for (int i = 0; i < n; i++) {
cnt[chars[i] - '0']++;
while (l <= i && cnt[0] > k && cnt[1] > k) {
cnt[chars[l++] - '0']--;
}
res += i - l + 1;
}
return res;
}
}
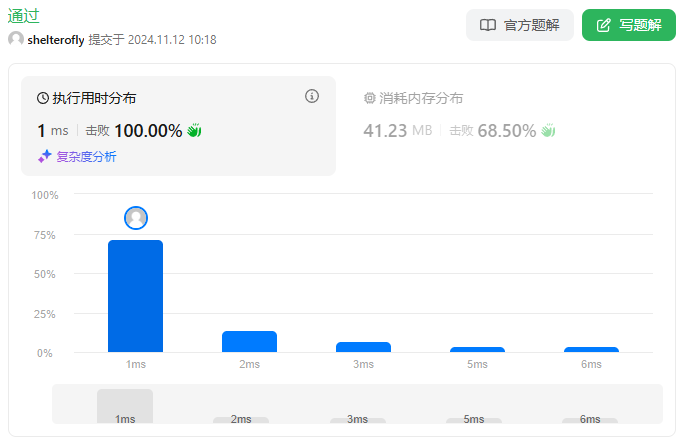
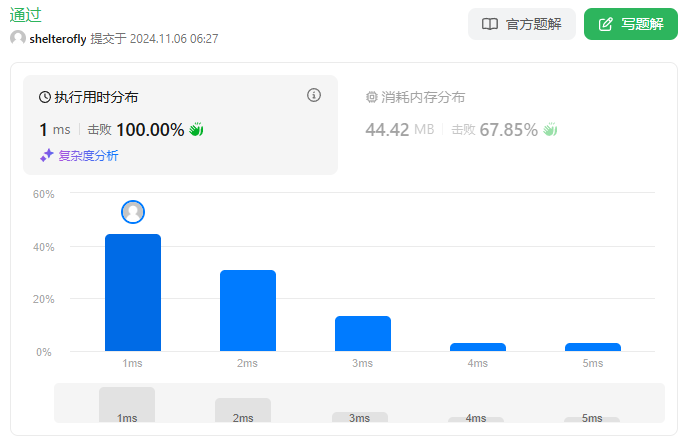
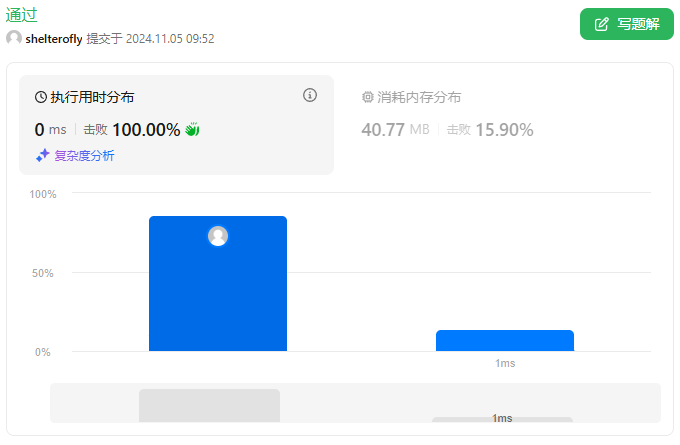
性能