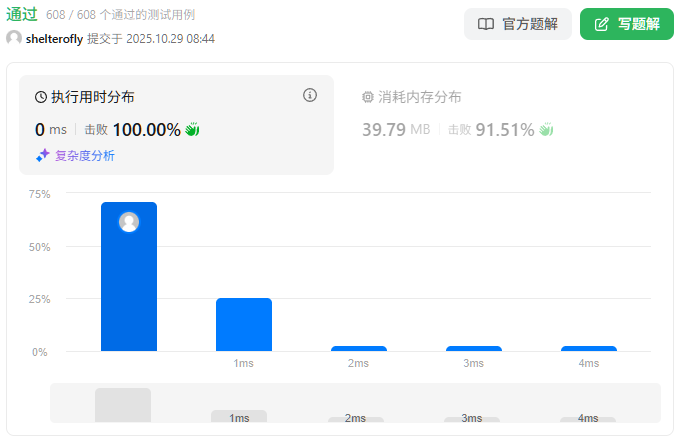
目标
给你一个整数数组 nums 。
开始时,选择一个满足 nums[curr] == 0 的起始位置 curr ,并选择一个移动 方向 :向左或者向右。
此后,你需要重复下面的过程:
- 如果 curr 超过范围 [0, n - 1] ,过程结束。
- 如果 nums[curr] == 0 ,沿当前方向继续移动:如果向右移,则 递增 curr ;如果向左移,则 递减 curr 。
- 如果 nums[curr] > 0:
- 将 nums[curr] 减 1 。
- 反转 移动方向(向左变向右,反之亦然)。
- 沿新方向移动一步。
如果在结束整个过程后,nums 中的所有元素都变为 0 ,则认为选出的初始位置和移动方向 有效 。
返回可能的有效选择方案数目。
示例 1:
输入:nums = [1,0,2,0,3]
输出:2
解释:
可能的有效选择方案如下:
选择 curr = 3 并向左移动。
[1,0,2,0,3] -> [1,0,2,0,3] -> [1,0,1,0,3] -> [1,0,1,0,3] -> [1,0,1,0,2] -> [1,0,1,0,2] -> [1,0,0,0,2] -> [1,0,0,0,2] -> [1,0,0,0,1] -> [1,0,0,0,1] -> [1,0,0,0,1] -> [1,0,0,0,1] -> [0,0,0,0,1] -> [0,0,0,0,1] -> [0,0,0,0,1] -> [0,0,0,0,1] -> [0,0,0,0,0].
选择 curr = 3 并向右移动。
[1,0,2,0,3] -> [1,0,2,0,3] -> [1,0,2,0,2] -> [1,0,2,0,2] -> [1,0,1,0,2] -> [1,0,1,0,2] -> [1,0,1,0,1] -> [1,0,1,0,1] -> [1,0,0,0,1] -> [1,0,0,0,1] -> [1,0,0,0,0] -> [1,0,0,0,0] -> [1,0,0,0,0] -> [1,0,0,0,0] -> [0,0,0,0,0].
示例 2:
输入:nums = [2,3,4,0,4,1,0]
输出:0
解释:
不存在有效的选择方案。
说明:
- 1 <= nums.length <= 100
- 0 <= nums[i] <= 100
- 至少存在一个元素 i 满足 nums[i] == 0 。
思路
有一个数组 nums,选一个元素值为 0 的位置作为起点,然后选择向左或向右移动,每遇到一个不为 0 的位置,将其元素值减一并沿相反方向继续移动,直到超出数组下标范围。求有多少种方案(由起点位置和初始移动方向唯一确定一个方案)可以使数组所有元素最终变为 0。
计算数组的前后缀,如果左侧等于右侧,可以选两个方向,如果左右两侧相差 1,可以选一个方向。
代码
/**
* @date 2025-10-28 8:49
*/
public class CountValidSelections3354 {
public int countValidSelections(int[] nums) {
int n = nums.length;
int[] prefix = new int[n + 1];
int[] suffix = new int[n + 1];
for (int i = 1; i <= n; i++) {
prefix[i] = prefix[i - 1] + nums[i - 1];
suffix[n - i] = suffix[n - i + 1] + nums[n - i];
}
int res = 0;
for (int i = 0; i < n; i++) {
if (nums[i] != 0) {
continue;
}
if (prefix[i] == suffix[i + 1]) {
res += 2;
}
if (prefix[i] == suffix[i + 1] + 1 || prefix[i] == suffix[i + 1] - 1) {
res++;
}
}
return res;
}
}
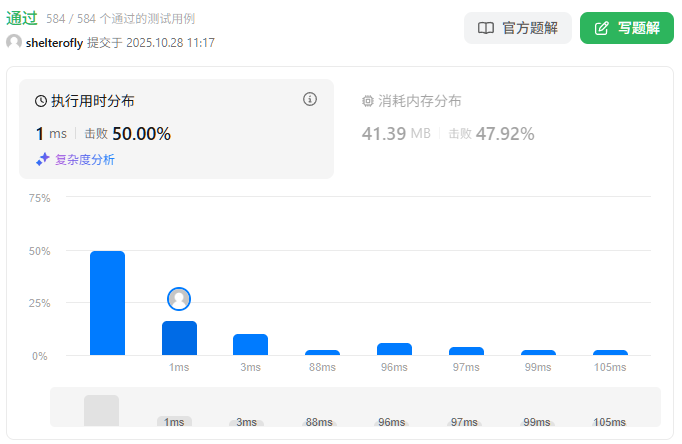
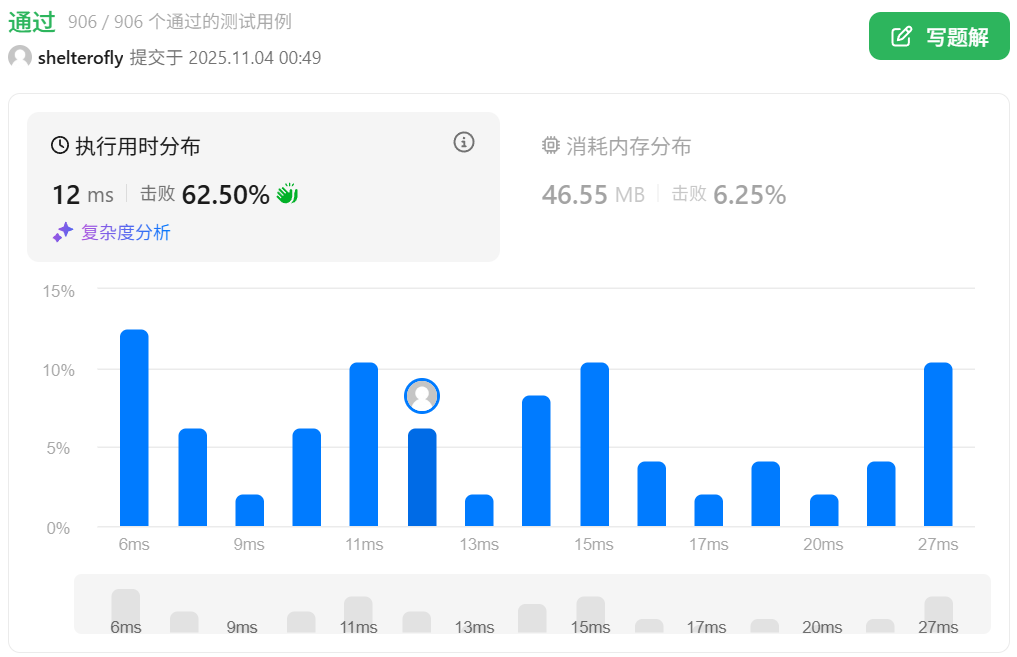
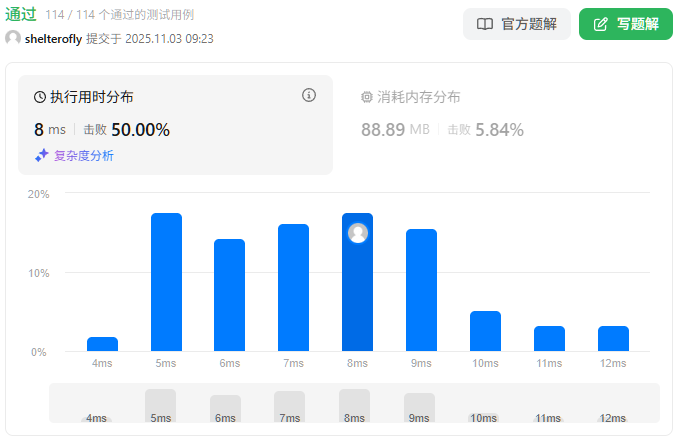
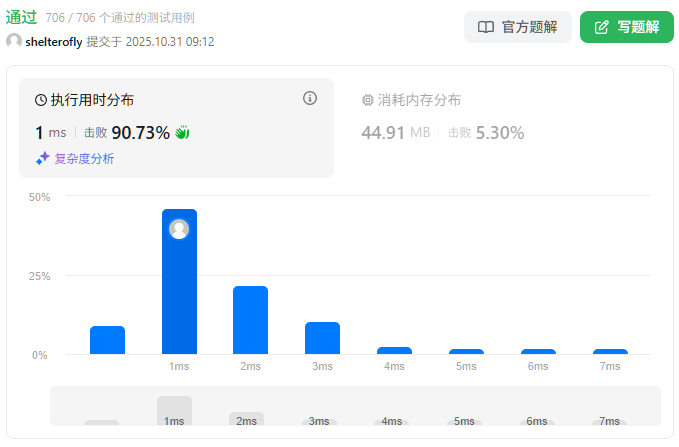
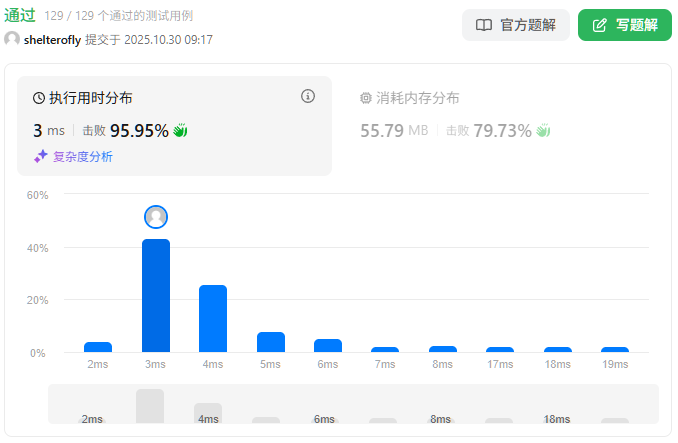
性能