目标
给你一个整数数组 nums,它表示一个循环数组。请你遵循以下规则创建一个大小 相同 的新数组 result :
对于每个下标 i(其中 0 <= i < nums.length),独立执行以下操作:
- 如果 nums[i] > 0:从下标 i 开始,向 右 移动 nums[i] 步,在循环数组中落脚的下标对应的值赋给 result[i]。
- 如果 nums[i] < 0:从下标 i 开始,向 左 移动 abs(nums[i]) 步,在循环数组中落脚的下标对应的值赋给 result[i]。
- 如果 nums[i] == 0:将 nums[i] 的值赋给 result[i]。
返回新数组 result。
注意:由于 nums 是循环数组,向右移动超过最后一个元素时将回到开头,向左移动超过第一个元素时将回到末尾。
示例 1:
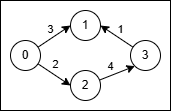
输入: nums = [3,-2,1,1]
输出: [1,1,1,3]
解释:
对于 nums[0] 等于 3,向右移动 3 步到 nums[3],因此 result[0] 为 1。
对于 nums[1] 等于 -2,向左移动 2 步到 nums[3],因此 result[1] 为 1。
对于 nums[2] 等于 1,向右移动 1 步到 nums[3],因此 result[2] 为 1。
对于 nums[3] 等于 1,向右移动 1 步到 nums[0],因此 result[3] 为 3。示例 2:
输入: nums = [-1,4,-1]
输出: [-1,-1,4]
解释:
对于 nums[0] 等于 -1,向左移动 1 步到 nums[2],因此 result[0] 为 -1。
对于 nums[1] 等于 4,向右移动 4 步到 nums[2],因此 result[1] 为 -1。
对于 nums[2] 等于 -1,向左移动 1 步到 nums[1],因此 result[2] 为 4。说明:
- 1 <= nums.length <= 100
- -100 <= nums[i] <= 100
思路
将循环数组 nums 根据规则转换成一个新数组,新数组下标 i 的值是 nums[offset],当 nums[i] > 0 时,offset 取 i 右边 nums[i] 个位置上的值,当 nums[i] < 0 时,取 i 左边 nums[i] 个位置上的值,如果为 0,取 nums[i]。
代码
/**
* @date 2026-02-05 8:43
*/
public class ConstructTransformedArray3379 {
public int[] constructTransformedArray_v1(int[] nums) {
int n = nums.length;
int[] res = new int[n];
for (int i = 0; i < n; i++) {
res[i] = nums[((i + nums[i]) % n + n) % n];
}
return res;
}
}
性能