目标
给你一个字符串 s 。
你的任务是重复以下操作删除 所有 数字字符:
- 删除 第一个数字字符 以及它左边 最近 的 非数字 字符。
请你返回删除所有数字字符以后剩下的字符串。
示例 1:
输入:s = "abc"
输出:"abc"
解释:
字符串中没有数字。示例 2:
输入:s = "cb34"
输出:""
解释:
一开始,我们对 s[2] 执行操作,s 变为 "c4" 。
然后对 s[1] 执行操作,s 变为 "" 。说明:
- 1 <= s.length <= 100
- s 只包含小写英文字母和数字字符。
- 输入保证所有数字都可以按以上操作被删除。
思路
删除给定字符串中的数字字符,每次删除操作需要同步删除该字符左侧最后一个非数字字符。
遍历的过程中使用栈保存非数字字符,遇到数字字符就弹栈,然后返回栈底到栈顶的字符即可。
知识点:
-
ArrayDeque 双端队列的特性取决于如何放入数据
start last first offer 4 3 2 1 push 1 2 3 4 -
offer是向左添加数据
-
push是向右添加数据
-
poll/pop/remove 默认从右向左取数据
-
如果api中带last,例如pollLast、removeLast则是从左向右取,first则相反
代码
/**
* @date 2024-09-05 8:47
*/
public class ClearDigits3174 {
public String clearDigits(String s) {
int n = s.length();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < n; i++) {
char c = s.charAt(i);
if (c > '9' || c < '0') {
sb.append(c);
} else {
sb.deleteCharAt(sb.length() - 1);
}
}
return sb.toString();
}
}
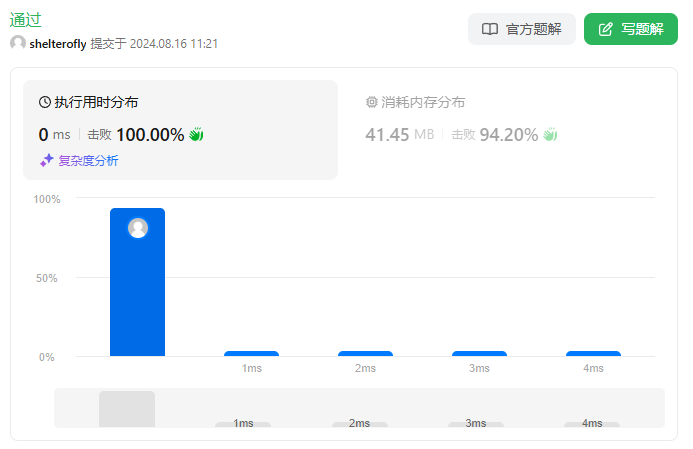
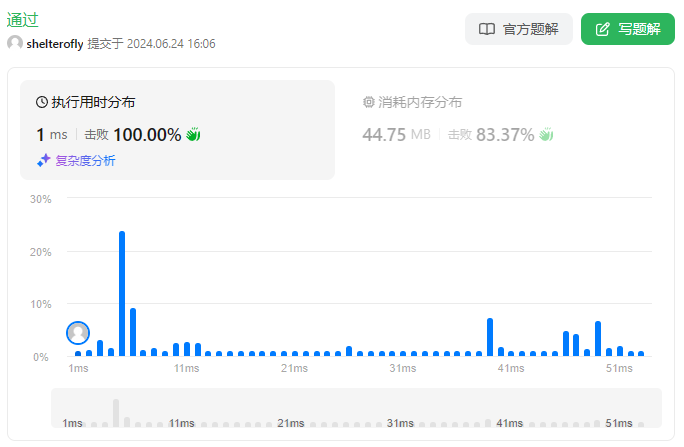
性能