目标
在考场里,一排有 N 个座位,分别编号为 0, 1, 2, ..., N-1 。
当学生进入考场后,他必须坐在能够使他与离他最近的人之间的距离达到最大化的座位上。如果有多个这样的座位,他会坐在编号最小的座位上。(另外,如果考场里没有人,那么学生就坐在 0 号座位上。)
返回 ExamRoom(int N) 类,它有两个公开的函数:其中,函数 ExamRoom.seat() 会返回一个 int (整型数据),代表学生坐的位置;函数 ExamRoom.leave(int p) 代表坐在座位 p 上的学生现在离开了考场。每次调用 ExamRoom.leave(p) 时都保证有学生坐在座位 p 上。
示例:
输入:["ExamRoom","seat","seat","seat","seat","leave","seat"], [[10],[],[],[],[],[4],[]]
输出:[null,0,9,4,2,null,5]
解释:
ExamRoom(10) -> null
seat() -> 0,没有人在考场里,那么学生坐在 0 号座位上。
seat() -> 9,学生最后坐在 9 号座位上。
seat() -> 4,学生最后坐在 4 号座位上。
seat() -> 2,学生最后坐在 2 号座位上。
leave(4) -> null
seat() -> 5,学生最后坐在 5 号座位上。说明:
- 1 <= N <= 10^9
- 在所有的测试样例中 ExamRoom.seat() 和 ExamRoom.leave() 最多被调用 10^4 次。
- 保证在调用 ExamRoom.leave(p) 时有学生正坐在座位 p 上。
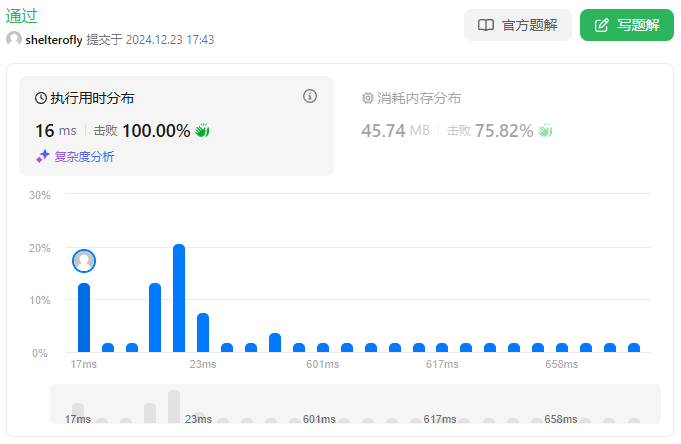
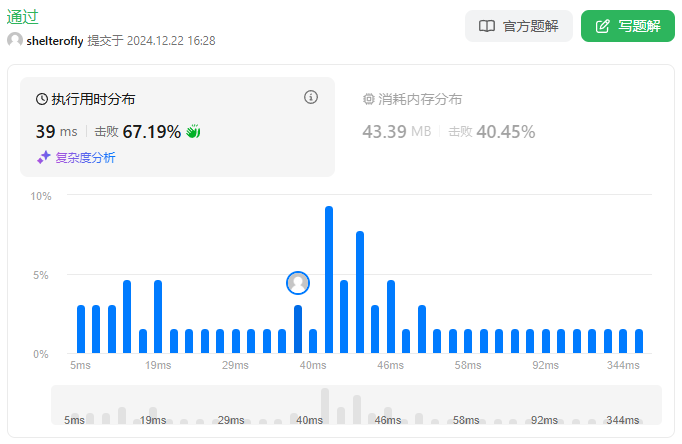
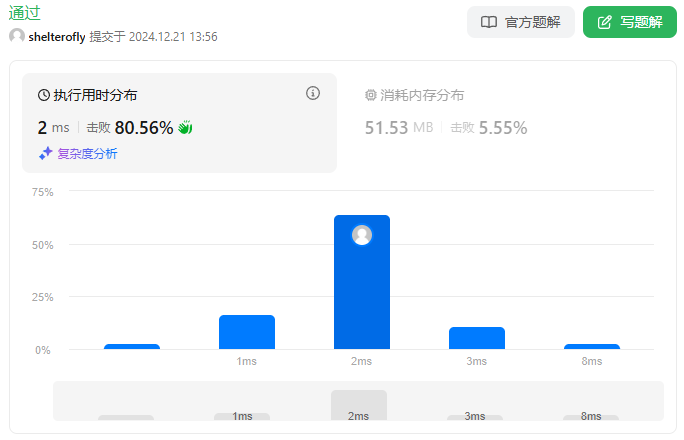
思路
有一排座位编号为 0 ~ N - 1,当学生进入考场后可以选择距离其它同学最远的位置坐下。实现 ExamRoom 类,提供 seat() 方法返回合法的座位,以及 leave() 方法允许学生离开考场。
显然下一个进入考场的同学应该坐在当前相邻座位最大距离的中间位置,考虑到允许离开座位,那么端点的座位离开的情况也要考虑。我们需要提供一个类,快速地查询相邻学生座位的最大值,并且支持座位的删减。
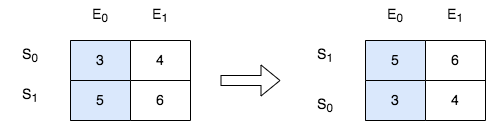
使用最大堆,堆中元素为 [距离左边相邻同学的距离,座位编号],根据 距离/2 排序,除以 2 是为了消除左右距离不等造成的影响。例如 0 4 9 这种情况,区间长度一个是 4,一个是 5,但是 2 ~ 4,4 ~ 6 的距离相同,应该取编号最小的。
计算下一个座位时,需要考虑三种情况:
- 如果是第一个同学进入考场,直接坐在 0 号位置
- 如果只有一个同学在考场,下一个同学需要坐在距离该位置距离最大的端点
- 如果有大于两个同学在考场,我们可以选择两个同学中间的位置,或者两端的位置
如何处理离开考场的情况?如果离开的同学左右位置有人,需要进行区间合并,将合并后的区间放入堆中,并且删除堆中左右两侧区间。但是在堆中查找元素的时间复杂度是 O(n),由于最多总共调用 10^4 次,leave 最多调用 k = 5 * 10^3 次,堆中元素个数随着调用减少,总复杂度为 O(k^2) 可能勉强通过。
为了快速访问左右的相邻座位以便区间合并以及左右端点的距离判断,使用 TreeSet 记录同学的座位编号。我们可以将删除操作延迟到获取座位的时候处理。
代码
/**
* @date 2024-12-23 14:28
*/
public class ExamRoom {
private TreeSet<Integer> occupied;
// [distance, no]
private PriorityQueue<int[]> q;
private int n;
public ExamRoom(int n) {
this.n = n;
occupied = new TreeSet<>();
q = new PriorityQueue<>((a, b) -> {
int compare = b[0] / 2 - a[0] / 2;
if (compare != 0) {
return compare;
}
return a[1] - b[1];
});
}
public int seat() {
if (occupied.size() == 0) {
occupied.add(0);
return 0;
} else if (occupied.size() == 1) {
Integer no = occupied.first();
int distance = n - 1 - no;
if (distance > no) {
q.offer(new int[]{distance, n - 1});
occupied.add(n - 1);
return n - 1;
} else {
q.offer(new int[]{no, no});
occupied.add(0);
return 0;
}
} else {
while (true) {
int first = occupied.first();
int last = occupied.last();
int rd = n - 1 - last;
int[] dn = q.peek();
int r = dn[1];
int l = r - dn[0];
// 注意第三个条件,可以防止离开座位后又有同学坐下,由于延迟删除,距离并未更新导致的计算错误
if (!occupied.contains(l) || !occupied.contains(r) || occupied.higher(l) != r) {
q.poll();
continue;
}
int distance = dn[0] / 2;
if (distance <= first || distance < rd) {
if (first < rd) {
q.offer(new int[]{rd, n - 1});
occupied.add(n - 1);
return n - 1;
} else {
q.offer(new int[]{l, l});
occupied.add(0);
return 0;
}
} else {
q.poll();
int m = l + (r - l) / 2;
occupied.add(m);
q.offer(new int[]{m - l, m});
q.offer(new int[]{r - m, r});
return m;
}
}
}
}
public void leave(int p) {
if (p != occupied.first() && p != occupied.last()) {
int l = occupied.lower(p);
int r = occupied.higher(p);
q.offer(new int[]{r - l, r});
}
occupied.remove(p);
}
}
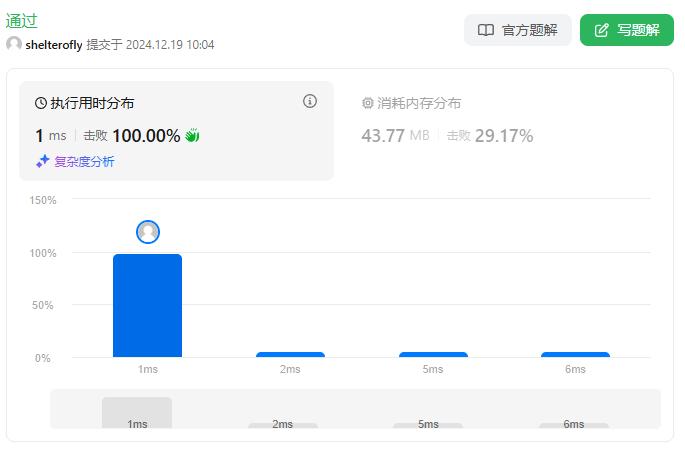
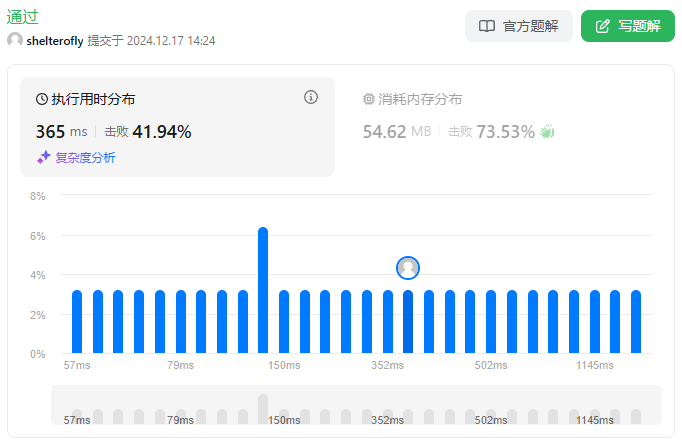
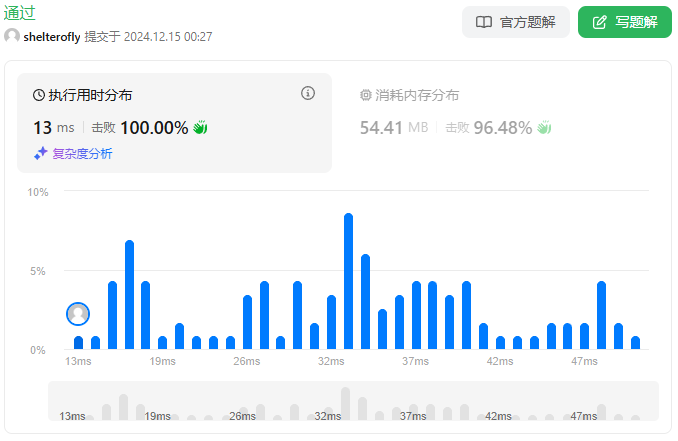
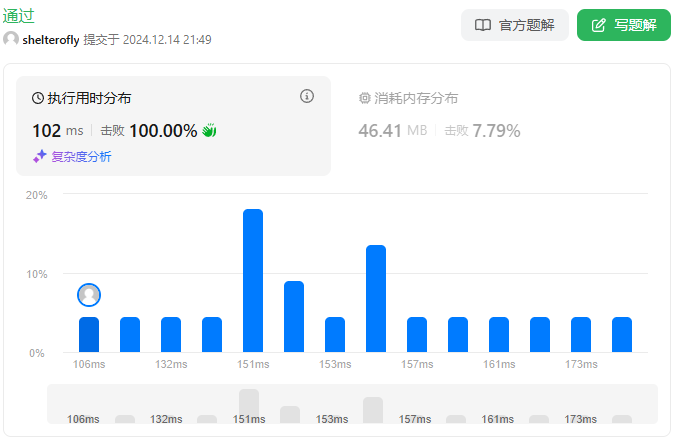
性能