目标
给你一个由 n 个整数组成的数组 nums 和一个整数 k,请你确定是否存在 两个 相邻 且长度为 k 的 严格递增 子数组。具体来说,需要检查是否存在从下标 a 和 b (a < b) 开始的 两个 子数组,并满足下述全部条件:
- 这两个子数组 nums[a..a + k - 1] 和 nums[b..b + k - 1] 都是 严格递增 的。
- 这两个子数组必须是 相邻的,即 b = a + k。
如果可以找到这样的 两个 子数组,请返回 true;否则返回 false。
子数组 是数组中的一个连续 非空 的元素序列。
示例 1:
输入:nums = [2,5,7,8,9,2,3,4,3,1], k = 3
输出:true
解释:
从下标 2 开始的子数组为 [7, 8, 9],它是严格递增的。
从下标 5 开始的子数组为 [2, 3, 4],它也是严格递增的。
两个子数组是相邻的,因此结果为 true。示例 2:
输入:nums = [1,2,3,4,4,4,4,5,6,7], k = 5
输出:false说明:
- 2 <= nums.length <= 100
- 1 <= 2 * k <= nums.length
- -1000 <= nums[i] <= 1000
思路
判断是否存在两个长度为 k 的相邻的子数组,要求子数组内严格递增。
定义 dp[i] 表示以 i 结尾的递增子数组的最大长度,如果 nums[i] > nums[i - 1], dp[i] = dp[i - 1] + 1,否则 dp[i] = 1。最后只需判断是否存在 i 使得 dp[i] >= k && dp[i + k] >= k 即可。
代码
/**
* @date 2025-10-14 9:02
*/
public class HasIncreasingSubarrays3349 {
public boolean hasIncreasingSubarrays(List<Integer> nums, int k) {
int n = nums.size();
int[] dp = new int[n];
dp[0] = 1;
for (int i = 1; i < n; i++) {
if (nums.get(i) > nums.get(i - 1)) {
dp[i] = dp[i - 1] + 1;
} else {
dp[i] = 1;
}
}
for (int i = k - 1; i + k < n; i++) {
if (dp[i] >= k && dp[i + k] >= k) {
return true;
}
}
return false;
}
}
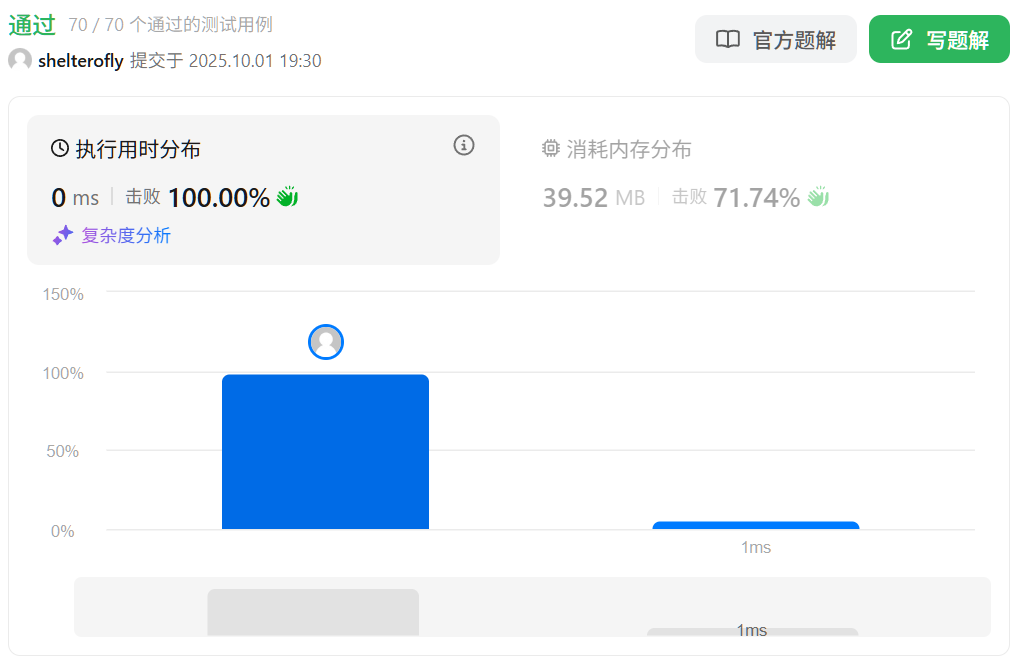
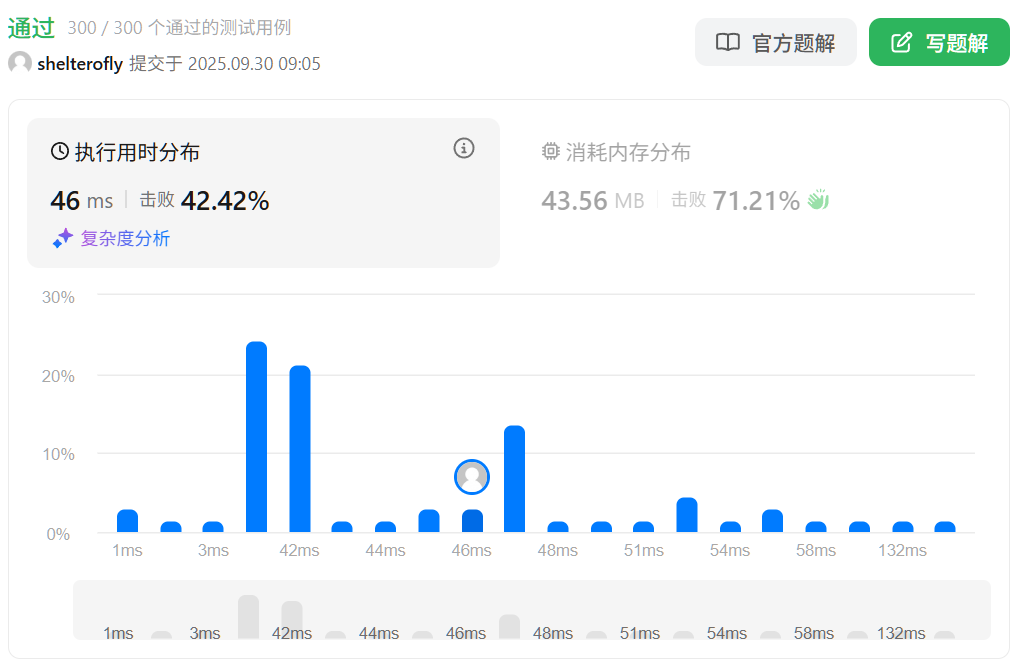
性能