目标
请你设计一个管理 n 个座位预约的系统,座位编号从 1 到 n 。
请你实现 SeatManager 类:
- SeatManager(int n) 初始化一个 SeatManager 对象,它管理从 1 到 n 编号的 n 个座位。所有座位初始都是可预约的。
- int reserve() 返回可以预约座位的 最小编号 ,此座位变为不可预约。
- void unreserve(int seatNumber) 将给定编号 seatNumber 对应的座位变成可以预约。
示例 1:
输入:
["SeatManager", "reserve", "reserve", "unreserve", "reserve", "reserve", "reserve", "reserve", "unreserve"]
[[5], [], [], [2], [], [], [], [], [5]]
输出:
[null, 1, 2, null, 2, 3, 4, 5, null]
解释:
SeatManager seatManager = new SeatManager(5); // 初始化 SeatManager ,有 5 个座位。
seatManager.reserve(); // 所有座位都可以预约,所以返回最小编号的座位,也就是 1 。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5] ,返回最小编号的座位,也就是 2 。
seatManager.unreserve(2); // 将座位 2 变为可以预约,现在可预约的座位为 [2,3,4,5] 。
seatManager.reserve(); // 可以预约的座位为 [2,3,4,5] ,返回最小编号的座位,也就是 2 。
seatManager.reserve(); // 可以预约的座位为 [3,4,5] ,返回最小编号的座位,也就是 3 。
seatManager.reserve(); // 可以预约的座位为 [4,5] ,返回最小编号的座位,也就是 4 。
seatManager.reserve(); // 唯一可以预约的是座位 5 ,所以返回 5 。
seatManager.unreserve(5); // 将座位 5 变为可以预约,现在可预约的座位为 [5] 。说明:
- 1 <= n <= 10^5
- 1 <= seatNumber <= n
- 每一次对 reserve 的调用,题目保证至少存在一个可以预约的座位。
- 每一次对 unreserve 的调用,题目保证 seatNumber 在调用函数前都是被预约状态。
- 对 reserve 和 unreserve 的调用 总共 不超过 10^5 次。
思路
设计一个座位预约系统,初始化 n 个座位,可以预约尚未预约的编号最小的座位,支持取消预约操作。
核心是解决取消预约后如何获取编号最小值的问题,可以使用最小堆维护剩余座位。
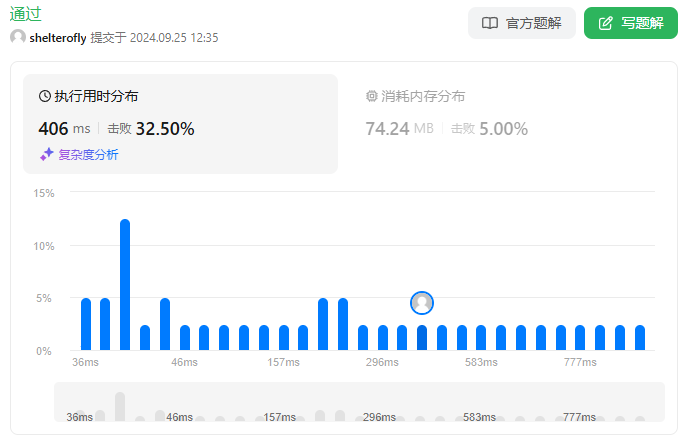
网友指出,初始化的复杂度与 n 有关,当 n 规模过大时会超时。可以使用最小堆维护取消预订的座位,显然取消预订的座位编号一定小于未被预定的座位编号。记录已预定出去的座位最高位 max,如果堆不为空则取堆顶元素,否则返回 max + 1。
代码
/**
* @date 2024-09-30 21:46
*/
public class SeatManager {
private PriorityQueue<Integer> q;
public SeatManager(int n) {
q = new PriorityQueue<>();
for (int i = 1; i <= n; i++) {
q.offer(i);
}
}
public int reserve() {
return q.poll();
}
public void unreserve(int seatNumber) {
q.offer(seatNumber);
}
}
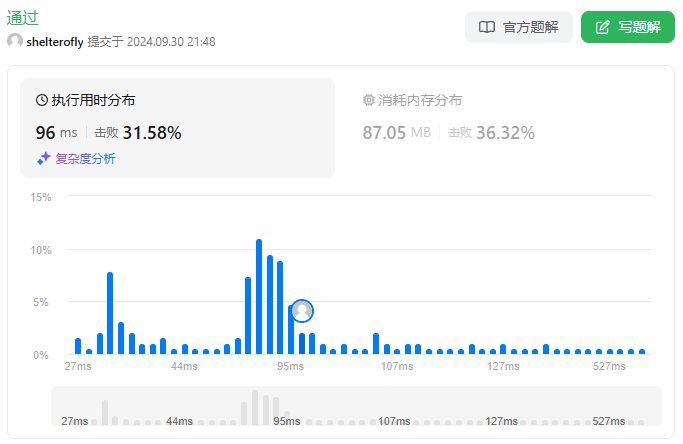
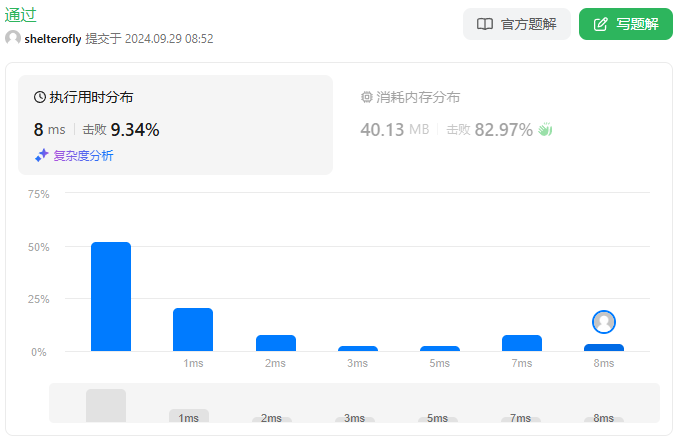
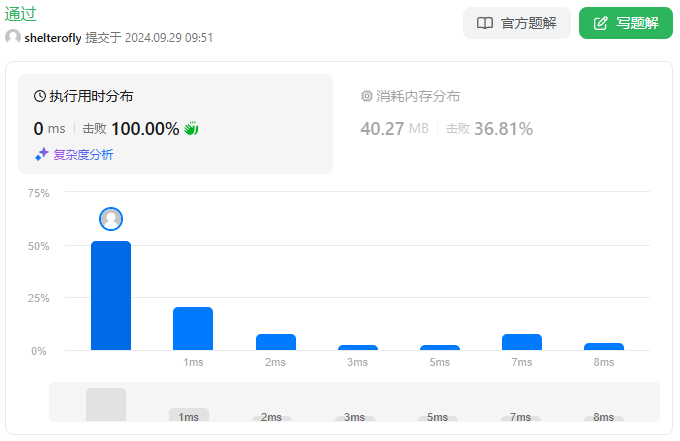
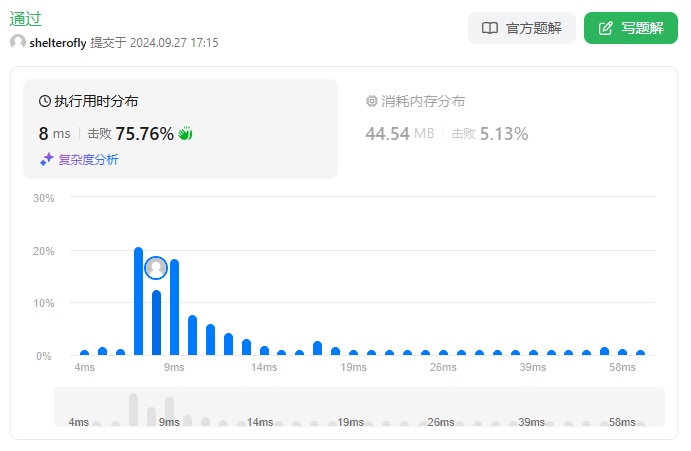
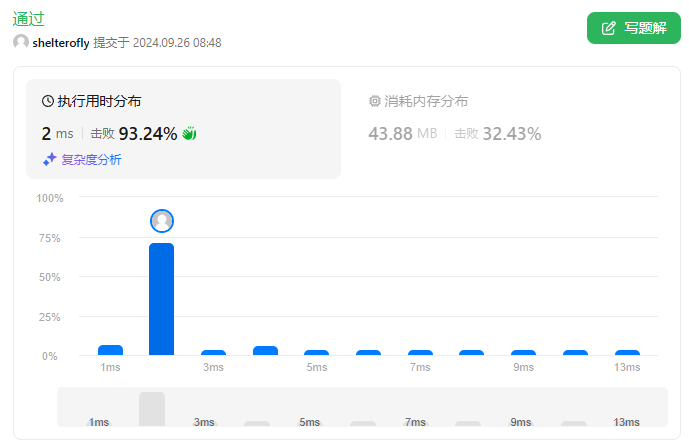
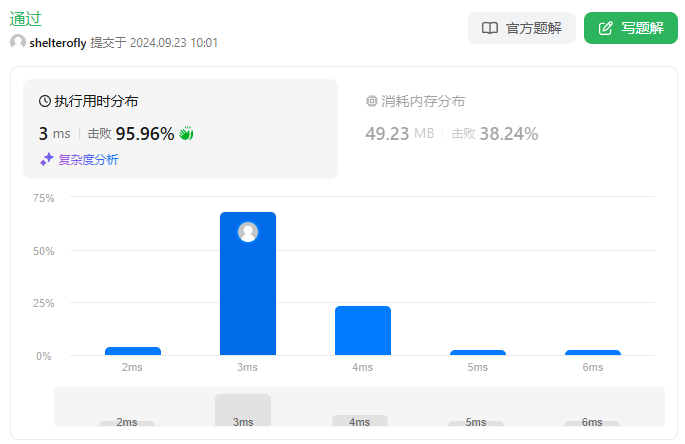
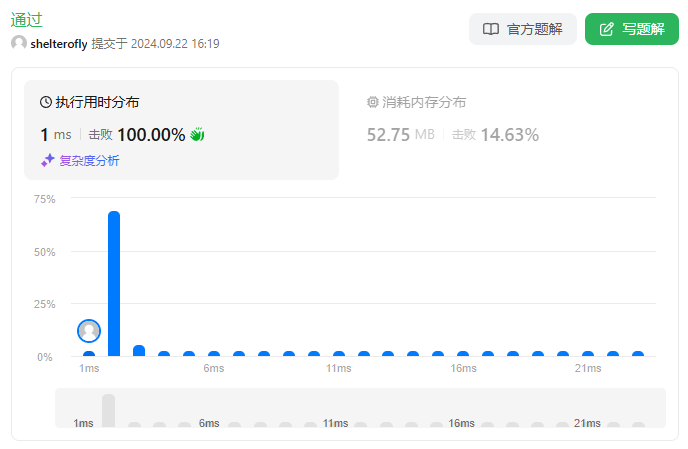
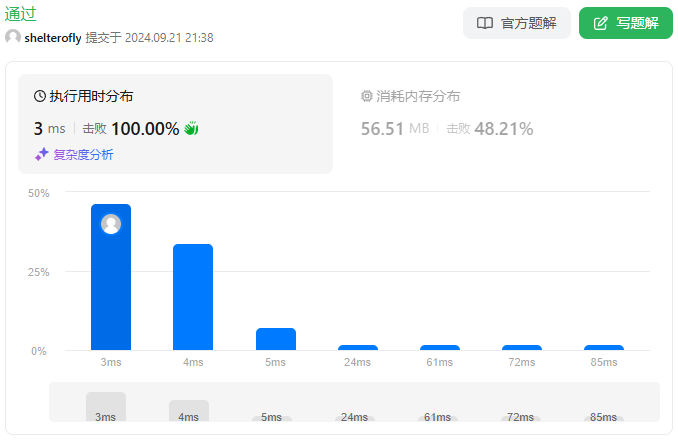
性能