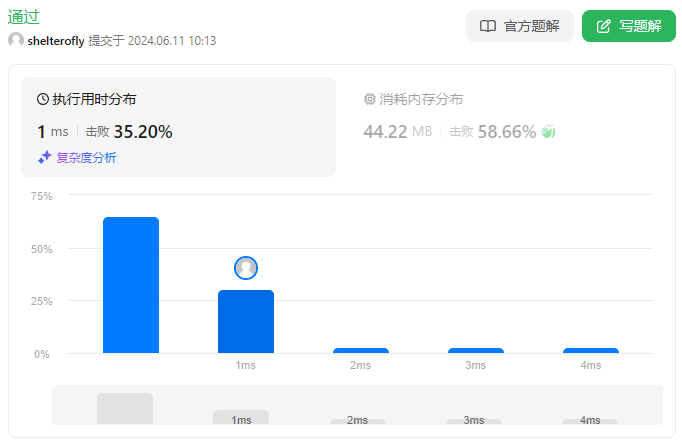
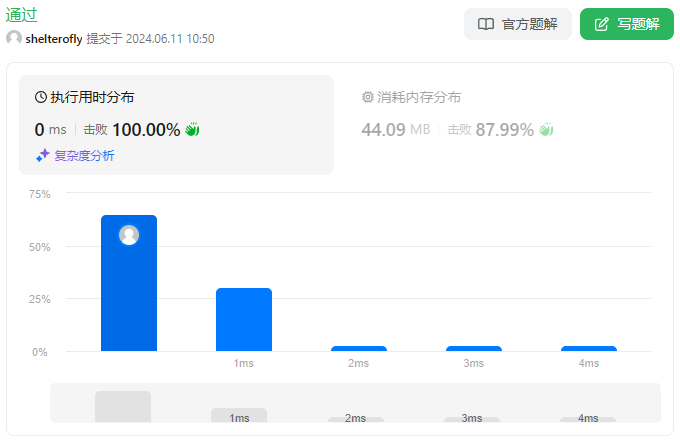
目标
给你一个下标从 0 开始的整数数组 nums 。如果下标对 i、j 满足 0 ≤ i < j < nums.length ,如果 nums[i] 的 第一个数字 和 nums[j] 的 最后一个数字 互质 ,则认为 nums[i] 和 nums[j] 是一组 美丽下标对 。
返回 nums 中 美丽下标对 的总数目。
对于两个整数 x 和 y ,如果不存在大于 1 的整数可以整除它们,则认为 x 和 y 互质 。换而言之,如果 gcd(x, y) == 1 ,则认为 x 和 y 互质,其中 gcd(x, y) 是 x 和 y 的 最大公因数 。
示例 1:
输入:nums = [2,5,1,4]
输出:5
解释:nums 中共有 5 组美丽下标对:
i = 0 和 j = 1 :nums[0] 的第一个数字是 2 ,nums[1] 的最后一个数字是 5 。2 和 5 互质,因此 gcd(2,5) == 1 。
i = 0 和 j = 2 :nums[0] 的第一个数字是 2 ,nums[2] 的最后一个数字是 1 。2 和 5 互质,因此 gcd(2,1) == 1 。
i = 1 和 j = 2 :nums[1] 的第一个数字是 5 ,nums[2] 的最后一个数字是 1 。2 和 5 互质,因此 gcd(5,1) == 1 。
i = 1 和 j = 3 :nums[1] 的第一个数字是 5 ,nums[3] 的最后一个数字是 4 。2 和 5 互质,因此 gcd(5,4) == 1 。
i = 2 和 j = 3 :nums[2] 的第一个数字是 1 ,nums[3] 的最后一个数字是 4 。2 和 5 互质,因此 gcd(1,4) == 1 。
因此,返回 5 。示例 2:
输入:nums = [11,21,12]
输出:2
解释:共有 2 组美丽下标对:
i = 0 和 j = 1 :nums[0] 的第一个数字是 1 ,nums[1] 的最后一个数字是 1 。gcd(1,1) == 1 。
i = 0 和 j = 2 :nums[0] 的第一个数字是 1 ,nums[2] 的最后一个数字是 2 。gcd(1,2) == 1 。
因此,返回 2 。说明:
- 2 <= nums.length <= 100
- 1 <= nums[i] <= 9999
- nums[i] % 10 != 0
思路
有一个整数数组,从中任选两个元素,如果下标小的元素的第一个数字与下标大的元素的最后一个数字互质,则称这两个元素为美丽下标对。求数组中美丽下标对的总数。
知识点:
- 如何获取元素值的第一个数字,
while(num>=10){num /=10;} - 如何判断互质,欧几里得算法
代码
/**
* @date 2024-06-20 8:37
*/
public class CountBeautifulPairs2748 {
/**
* 优化,将外层循环获取第一个数字,然后依次向后比较
* 改为记录之前遍历过数字的第一个数(1~9)的出现次数
* 循环的时候只需遍历1~9 9个数字,取其中出现次数不为0的与当前数的最后一个数判断是否互质
* 累加出现次数即可
*/
public int countBeautifulPairs_v1(int[] nums) {
int res = 0;
int[] firstDigitsCnt = new int[10];
for (int num : nums) {
for (int j = 1; j < 10; j++) {
if (firstDigitsCnt[j] != 0 && gcd(j, num % 10) == 1) {
res += firstDigitsCnt[j];
}
}
while (num >= 10) {
num /= 10;
}
firstDigitsCnt[num]++;
}
return res;
}
public int gcd(int x, int y) {
return y == 0 ? x : gcd(y, x % y);
}
public int countBeautifulPairs_v2(int[] nums) {
int res = 0;
int[] firstDigitsCnt = new int[10];
int[][] prime = new int[][]{
{},
{1, 2, 3, 4, 5, 6, 7, 8, 9},
{1, 3, 5, 7, 9},
{1, 2, 4, 5, 7, 8},
{1, 3, 5, 7, 9},
{1, 2, 3, 4, 6, 7, 8, 9},
{1, 5, 7},
{1, 2, 3, 4, 5, 6, 8, 9},
{1, 3, 5, 7, 9},
{1, 2, 4, 5, 7, 8}
};
for (int num : nums) {
for (int p : prime[num % 10]) {
res += firstDigitsCnt[p];
}
while (num >= 10) {
num /= 10;
}
firstDigitsCnt[num]++;
}
return res;
}
}
性能
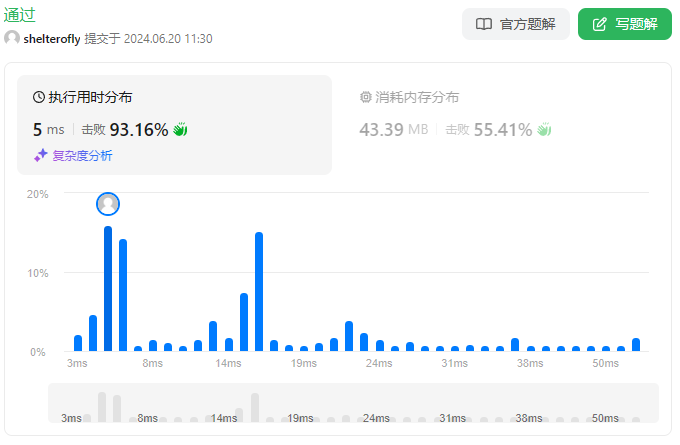
最快的算法是预处理1~9对应的互质数组