目标
给你一个二进制字符串 binary ,它仅有 0 或者 1 组成。你可以使用下面的操作任意次对它进行修改:
-
操作 1 :如果二进制串包含子字符串 "00" ,你可以用 "10" 将其替换。
比方说, "00010" -> "10010"
-
操作 2 :如果二进制串包含子字符串 "10" ,你可以用 "01" 将其替换。
比方说, "00010" -> "00001"
请你返回执行上述操作任意次以后能得到的 最大二进制字符串 。如果二进制字符串 x 对应的十进制数字大于二进制字符串 y 对应的十进制数字,那么我们称二进制字符串 x 大于二进制字符串 y 。
示例 1:
输入:binary = "000110"
输出:"111011"
解释:一个可行的转换为:
"000110" -> "000101"
"000101" -> "100101"
"100101" -> "110101"
"110101" -> "110011"
"110011" -> "111011"示例 2:
输入:binary = "01"
输出:"01"
解释:"01" 没办法进行任何转换。说明:
- 1 <= binary.length <= 10^5
- binary 仅包含 '0' 和 '1'
思路
看到这道题我最先想到的是使用字符串替换,先把00的都替换为10,直到不能替换为止。然后再替换10为01,直到不能替换为止。然后再从头替换,相当于是一个while里面套两个while。
通过对具体例子的观察可以发现将10替换为01不是无条件的,我甚至还写了比较字符串大小的方法,如果字符串变小了就不变了。但其实是不行的,因为中间过程确实存在变小的情况。
最后经过观察分析发现必须要前面有0才可以替换,因为这样可以将高位的0置为1。以01110为例,最后能够转换为10111。
于是就想通过replace方法替换捕获组来实现,例如匹配 0(1*)0,替换为 10(匹配到的1),试了一下发现replacement不支持。Pattern 类也是无法使用的。
基于上面的分析,我们可以通过算法模拟出替换过程,这里面需要用到双指针 start 与 i:
- 如果
start与i相同且都指向1,那么直接跳过 - 如果
start与i相差1,且i指向0,即00的情况,那么将start指向置1,start++ - 否则,如果
start与i相差大于1,且i指向0,即0(1+)0的情况,那么需要将start指向置1,start后面的置0,i指向的置1 即可
需要注意的是,如果 start 与 i 不同,那么 start 指向的一定是0。其实步骤2与3可以合并,只需先将 i 置1,然后再将 start 后面的置0即可。
看了官网的题解,还提供了一种直接构建的算法。
如果字符串中有多个0,总可以将它们通过10->01将其前移至第一个0的位置,然后通过00->10,使高位的0变为1。最终的结果中至多包含1个0。
因此,直接构建的方法是:从第一个0开始,后面的0全置为1,然后将第一个0后移 0的个数减1 个位置。
代码
/**
* @date 2024-04-10 0:53
*/
public class MaximumBinaryString1702 {
/** 直接构造 */
public String maximumBinaryString_v2(String binary) {
char[] b = binary.toCharArray();
int firstZero = binary.indexOf('0');
if (firstZero == -1) {
return binary;
}
int cnt = 0;
for (int i = firstZero; i < b.length; i++) {
cnt += '1' - b[i];
b[i] = '1';
}
b[firstZero + cnt - 1] = '0';
return new String(b);
}
public String maximumBinaryString_v1(String binary) {
char[] b = binary.toCharArray();
int start = 0;
for (int i = 0; i < b.length; i++) {
if (start == i && '1' == b[i]) {
start++;
} else if (start <= i - 1 && '0' == b[i]) {
b[start++] = '1';
b[i] = '1';
b[start] = '0';
}
}
return new String(b);
}
public String maximumBinaryString(String binary) {
char[] b = binary.toCharArray();
int start = 0;
for (int i = 0; i < b.length; i++) {
if (start == i && '1' == b[i]) {
start++;
} else if (start == i - 1 && '0' == b[i]) {
b[start++] = '1';
} else if (start < i - 1 && '0' == b[i]) {
b[start++] = '1';
b[start] = '0';
b[i] = '1';
}
}
return new String(b);
}
}
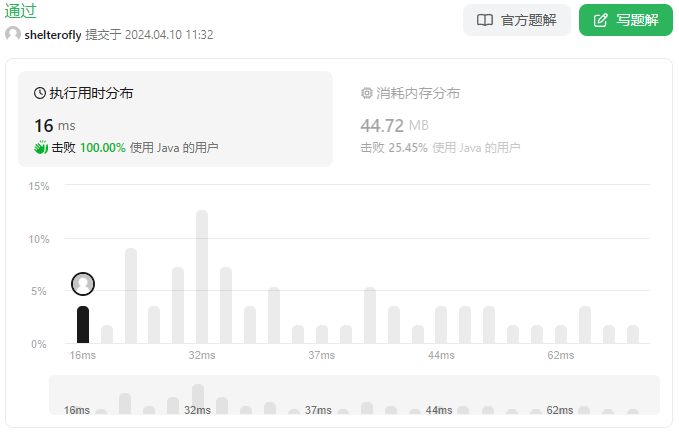
性能