目标
你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下:
写出一个秘密数字,并请朋友猜这个数字是多少。朋友每猜测一次,你就会给他一个包含下述信息的提示:
- 猜测数字中有多少位属于数字和确切位置都猜对了(称为 "Bulls",公牛),
- 有多少位属于数字猜对了但是位置不对(称为 "Cows",奶牛)。也就是说,这次猜测中有多少位非公牛数字可以通过重新排列转换成公牛数字。
给你一个秘密数字 secret 和朋友猜测的数字 guess ,请你返回对朋友这次猜测的提示。
提示的格式为 "xAyB" ,x 是公牛个数, y 是奶牛个数,A 表示公牛,B 表示奶牛。
请注意秘密数字和朋友猜测的数字都可能含有重复数字。
示例 1:
输入:secret = "1807", guess = "7810"
输出:"1A3B"
解释:数字和位置都对(公牛)用 '|' 连接,数字猜对位置不对(奶牛)的采用斜体加粗标识。
"1807"
|
"7810"示例 2:
输入:secret = "1123", guess = "0111"
输出:"1A1B"
解释:数字和位置都对(公牛)用 '|' 连接,数字猜对位置不对(奶牛)的采用斜体加粗标识。
"1123" "1123"
| or |
"0111" "0111"
注意,两个不匹配的 1 中,只有一个会算作奶牛(数字猜对位置不对)。通过重新排列非公牛数字,其中仅有一个 1 可以成为公牛数字。说明:
- 1 <= secret.length, guess.length <= 1000
- secret.length == guess.length
- secret 和 guess 仅由数字组成
思路
这个题目的算法还是挺直接的,就是比较相应位置上的数字是否一致,如果一致bulls加1,否则就要累加错误数字的出现次数,但最多不能超过其在secret中的个数。
代码
/**
* @date 2024-03-10 0:36
*/
public class GetHint {
public String getHint(String secret, String guess) {
int bulls = 0;
int cows = 0;
char[] secretCharArray = secret.toCharArray();
int[] missArray = new int[10];
int[] cowsArray = new int[10];
for (int i = 0; i < secretCharArray.length; i++) {
int guessCharacter = guess.charAt(i) - '0';
int secretCharacter = secretCharArray[i] - '0';
if (guessCharacter == secretCharacter) {
bulls++;
} else {
missArray[secretCharacter] += 1;
cowsArray[guessCharacter] += 1;
}
}
for (int i = 0; i < cowsArray.length; i++) {
if (missArray[i] > 0 && cowsArray[i] > 0) {
cows += Math.min(missArray[i], cowsArray[i]);
}
}
StringBuilder sb = new StringBuilder();
return sb.append(bulls).append('A').append(cows).append('B').toString();
}
}这里面有几点需要注意:
- 数组只需要保留0-9十个数字即可
- 数字字符减去
'0'可以得到对应的整型数字 - 不要使用加号拼接返回的结果,因为每一次字符串的修改都会创建新的对象,会显著影响性能
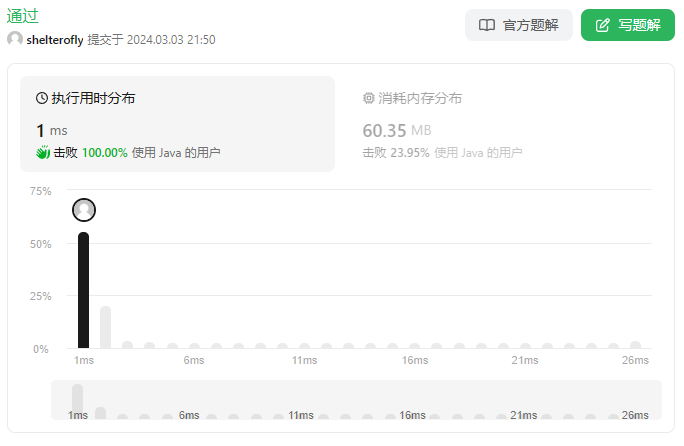
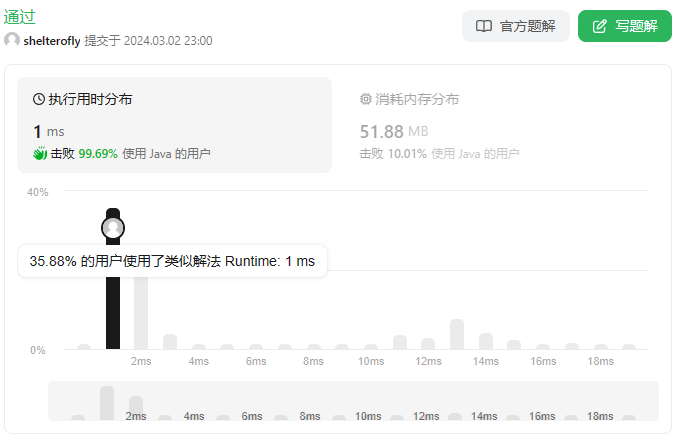
性能