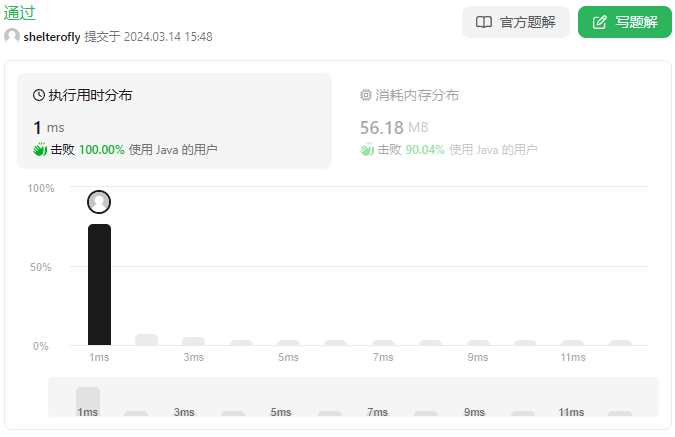
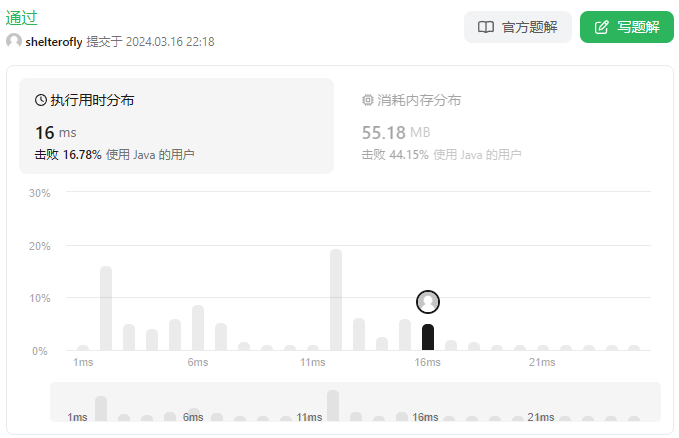
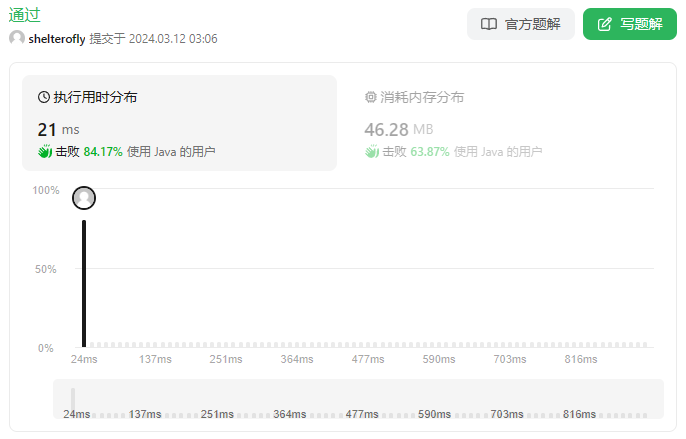
目标
给你一个整数数组 nums (下标从 0 开始)和一个整数 k 。
一个子数组 (i, j) 的 分数 定义为 min(nums[i], nums[i+1], ..., nums[j]) * (j - i + 1) 。一个 好 子数组的两个端点下标需要满足 i <= k <= j 。
请你返回 好 子数组的最大可能 分数 。
示例 1:
输入:nums = [1,4,3,7,4,5], k = 3
输出:15
解释:最优子数组的左右端点下标是 (1, 5) ,分数为 min(4,3,7,4,5) * (5-1+1) = 3 * 5 = 15 。示例 2:
输入:nums = [5,5,4,5,4,1,1,1], k = 0
输出:20
解释:最优子数组的左右端点下标是 (0, 4) ,分数为 min(5,5,4,5,4) * (4-0+1) = 4 * 5 = 20 。提示:
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 2 * 10^4
- 0 <= k < nums.length
思路
题目中定义的好子数组必须要包含下标k,且其元素最小值乘以它的长度应最大。相同长度的子数组其最小值通常不同,应取最小值中最大的,这样才能在窗口固定的情况下求得最大分数。
刚开始我把这个问题作为一个动态规划问题来求解:有一个窗口,在下标k的位置有一个固定轴,窗口可以左右滑动,拉伸,但窗口边缘不能越过k。然后求解窗口大小固定时,滑动窗口内最小元素取最大时的状态。接着扩展窗口,新窗口的取值依赖于上一窗口,只需在上一窗口的基础上左右各扩展一个元素进行比较即可。
但是我马上就遇到了问题,因为k的位置是不确定的,窗口左右滑动总会有一边先到达边界,然后怎么处理?上一个窗口取得较大的最小值可能是在k左侧,当窗口到达左侧边界后就无法再移动了,这样势必会有一部分覆盖到k右侧,我们无法再用一侧的最优解来掩盖另一侧了。而右边新加入窗口的元素与上一个状态选择的最小值无法确定新的最小值。因为窗口记录的是左右两侧的最优解,单独某一侧的状态并没有被记录。比如 nums=[10,9,8,7,6,5,3,2,2,4,9,4,11,3,4],k=5,当窗口大小为6时,左侧的最小值是5,右侧最小值是2(但是我们并没有记录),我们记录的是较大的5。当窗口大小为7时,左侧窗口最小值为3(必须跨过k了),右侧新加入窗口的值是4,如果与上一个状态比较,我们可能会选择4,但是右侧最小值是2,我们应该选3。
于是我想可能需要分别记录左右两侧的状态。我们为什么要记录状态?上面记录状态是为了与新进入窗口的元素比较来选择最优解,我们现在记录左右两侧的什么呢?
随着思考的深入,我觉得应该放弃所谓滑动窗口这个概念了,不应该在左右两侧同时求解。
思考这个问题,窗口增大之后,其中元素的最小值会怎么变?反正最小值一定不会变大。于是只要新加入的元素比窗口内已经选定的最小值大就可以一直扩张,因为最小值没有变化,窗口大小越大分数就越大。当遇到比当前窗口内最小值小的元素时就需要比较窗口另一侧的值,哪边的更大就从哪边扩张。如此反复即可。
代码
/**
* @date 2024-03-19 0:16
*/
public class MaximumScore {
public int maximumScore_v2(int[] nums, int k) {
if (nums.length == 1) {
return nums[0];
}
int res = 0;
int l = k - 1, r = k + 1;
int lmin = nums[k], rmin = nums[k];
while (l >= 0 || r < nums.length) {
if (l >= 0) {
lmin = Math.min(lmin, nums[l]);
}
if (r < nums.length) {
rmin = Math.min(rmin, nums[r]);
}
if ((lmin >= rmin && l >= 0) || r >= nums.length) {
l--;
while (l >= 0 && lmin <= nums[l]) {
l--;
}
// r-l是窗口大小(不包括r),由于l多减了1,所以这里要减去
res = Math.max(res, lmin * (r - l - 1));
} else {
r++;
while (r < nums.length && rmin <= nums[r]) {
r++;
}
// r-l是窗口大小(不包括l)由于r多加了1,所以这里要减去
res = Math.max(res, rmin * (r - l - 1));
}
}
return res;
}
}性能