有空补上
月度归档: 2024 年 2 月
2867.统计树中的合法路径数目
目标
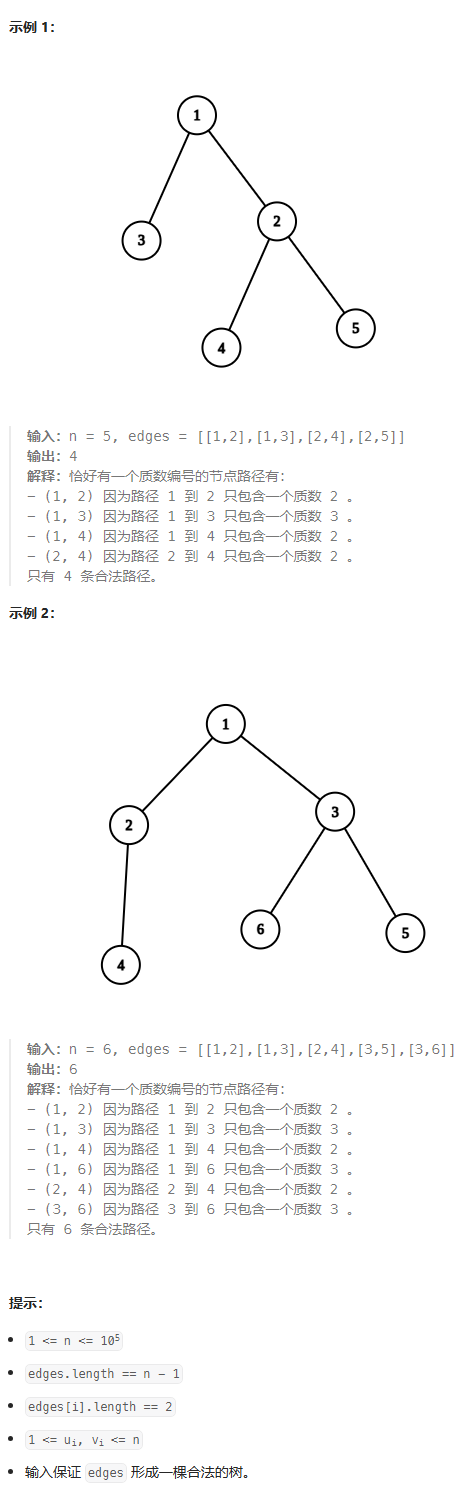
给你一棵 n 个节点的无向树,节点编号为 1 到 n 。给你一个整数 n 和一个长度为 n - 1 的二维整数数组 edges ,其中 edges[i] = [ui, vi] 表示节点 ui 和 vi 在树中有一条边。
请你返回树中的 合法路径数目 。
如果在节点 a 到节点 b 之间 恰好有一个 节点的编号是质数,那么我们称路径 (a, b) 是 合法的 。
注意:
- 路径 (a, b) 指的是一条从节点 a 开始到节点 b 结束的一个节点序列,序列中的节点 互不相同 ,且相邻节点之间在树上有一条边。
- 路径 (a, b) 和路径 (b, a) 视为 同一条 路径,且只计入答案 一次 。
思路
质数是指在大于1的自然数(非负整数)中,除了1和它本身以外不再有其他因数的自然数。
现在有一颗 n 个节点的无向树,要求任意两个连通节点间恰好有一个质数节点的路径数。树是一种无环连通图,问题可以转化为从树中选取两个节点,节点之间的路径只经过一个质数节点。由于没有环,所以两点之间的路径是唯一的。
- 两个都是质数节点要排除掉。
- 以质数节点为中心,与它邻接的非质数节点符合条件。即以质数节点为中心加上与之相连的非质数节点任取两个均可。我们可以称直接与质数节点相连的非质数节点为直接节点。
- 直接节点连通的非质数节点也可能满足条件,需要要减去直接节点向外连通的路径,即直接节点加上其向外连通的节点之间任取两个的路径数。
按照上面的思路,先要找到所有的质数节点,涉及到质数判断。同时保存与之直接相连的非质数节点。然后保存非质数节点的边,使用Map保存,边的两个端点都保存进去,方便后续向外查找连通的节点。
得到满足条件的节点总数,根据排列组合公式C(n,2) = n!/(2!(n-2)!) = (n-1)n/2 求得路径总数D。
将外围节点k向外连通节点总数记为Ik,无效路径数为(Ik-1)Ik/2。
最终的结果就是D - Σ(Ik-1)Ik/2
代码
/**
* @date 2024-02-27 0:22
*/
public class CountPaths {
public Map<Integer, Set<Integer>> primeEdges = new HashMap<>();
public Map<Integer, Set<Integer>> notPrimeEdges = new HashMap<>();
public Map<Integer, Integer> indirectNodesNumMap = new HashMap<>();
Set<Integer> counter = new HashSet<>();
public long countPaths(int n, int[][] edges) {
for (int i = 0; i < n - 1; i++) {
int[] edge = edges[i];
boolean i0 = isPrimeNumber(edge[0]);
boolean i1 = isPrimeNumber(edge[1]);
if (i0 && !i1) {
primeEdges.computeIfAbsent(edge[0], k -> new HashSet<>());
primeEdges.get(edge[0]).add(edge[1]);
} else if (!i0 && i1) {
primeEdges.computeIfAbsent(edge[1], k -> new HashSet<>());
primeEdges.get(edge[1]).add(edge[0]);
} else if(!i0){
notPrimeEdges.computeIfAbsent(edge[0], k -> new HashSet<>());
notPrimeEdges.computeIfAbsent(edge[1], k -> new HashSet<>());
notPrimeEdges.get(edge[0]).add(edge[1]);
notPrimeEdges.get(edge[1]).add(edge[0]);
}
}
long res = 0;
for (Integer primeNode : primeEdges.keySet()) {
Set<Integer> nonPrimeNodesOfPrimeEdge = primeEdges.get(primeNode);
counter.clear();
int total = 0;
for (int nonPrimeNode : nonPrimeNodesOfPrimeEdge) {
counter.add(nonPrimeNode);
if (indirectNodesNumMap.get(nonPrimeNode) == null) {
indirectNodesNumMap.put(nonPrimeNode, 1);
countEdges(nonPrimeNode, nonPrimeNode);
}
total += indirectNodesNumMap.get(nonPrimeNode);
}
total = total + 1;
res += total * (total - 1L) / 2L;
for (int nonPrimeNode : nonPrimeNodesOfPrimeEdge) {
int indirectNodesNum = indirectNodesNumMap.get(nonPrimeNode);
res -= indirectNodesNum * (indirectNodesNum - 1L) / 2L;
}
}
return res;
}
public Set<Integer> countEdges(int key, int nonPrimeNode) {
if (notPrimeEdges.get(nonPrimeNode) != null) {
for (Integer node : notPrimeEdges.get(nonPrimeNode)) {
if (!counter.contains(node)) {
indirectNodesNumMap.put(key, indirectNodesNumMap.get(key) + 1);
counter.add(node);
countEdges(key, node);
}
}
}
return counter;
}
public boolean isPrimeNumber(int num) {
if (num == 1) {
return false;
}
if (num == 2) {
return true;
}
if (num % 2 == 0) {
return false;
}
for (int i = 3; i * i <= num; i+=2) {
if (num % i == 0) {
return false;
}
}
return true;
}
public static void main(String[] args) {
// int[][] edges = new int[][]{new int[]{1, 2}, new int[]{1, 3}, new int[]{2, 4}, new int[]{2, 5}};
int[][] edges = new int[][]{new int[]{1, 2}, new int[]{4, 1}, new int[]{3, 4}};
CountPaths main = new CountPaths();
// System.out.println(main.countPaths(5, edges));
System.out.println(main.countPaths(4, edges));
}
}
性能
勉强通过。有时间再回来看看题解吧。
938.二叉搜索树的范围和
目标
给定二叉搜索树的根结点 root,返回值位于范围 [low, high] 之间的所有结点的值的和。
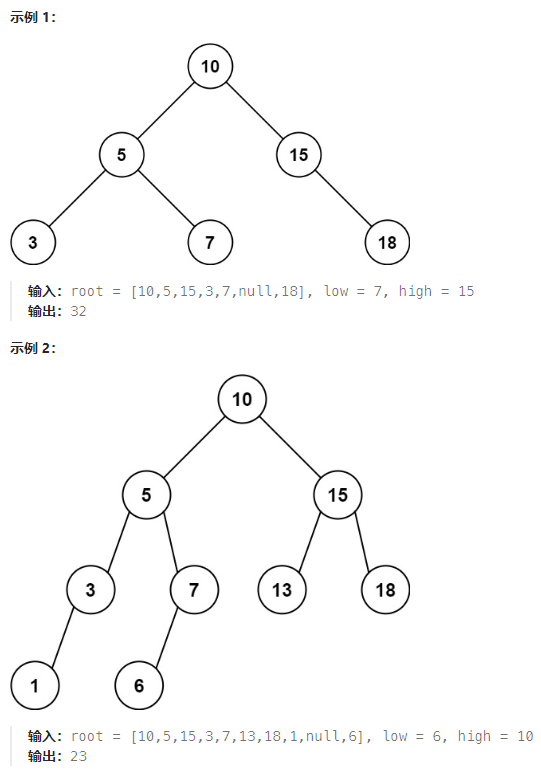
说明:
- 树中节点数目在范围 [1, 2 * 10^4] 内
- 1 <= Node.val <= 10^5
- 1 <= low <= high <= 10^5
- 所有 Node.val 互不相同
思路
二叉搜索树,也叫二叉查找树(Binary Search Tree, BST)。BST是一颗二叉树,其中的每个节点都含有一个可比较的Key,并且每个节点的Key都大于其左子树中的任意节点的Key,而小于其右子树的任意节点的Key。
比较每个节点是否在给定的范围内,如果节点Key小于low去左子树找,大于high则去右子树找,如果在二者之间,累加和,继续遍历左右子树。
代码
/**
* @date 2024/2/26 10:37
*/
public class RangeSumBST {
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
public int sum = 0;
/** 省去了节点为空的判断嵌套*/
public int rangeSumBST_v1(TreeNode root, int low, int high) {
if (root == null) {
return 0;
}
if (low > root.val) {
rangeSumBST_v1(root.right, low, high);
}
if (high < root.val) {
rangeSumBST_v1(root.left, low, high);
}
if (high >= root.val && low <= root.val) {
sum += root.val;
rangeSumBST_v1(root.left, low, high);
rangeSumBST_v1(root.right, low, high);
}
return sum;
}
public int rangeSumBST(TreeNode root, int low, int high) {
if (low > root.val) {
if (root.right != null) {
rangeSumBST(root.right, low, high);
}
}
if (high < root.val) {
if (root.left != null) {
rangeSumBST(root.left, low, high);
}
}
if (high >= root.val && low <= root.val){
sum += root.val;
if (root.left != null) {
rangeSumBST(root.left, low, high);
}
if (root.right != null) {
rangeSumBST(root.right, low, high);
}
}
return sum;
}
}
性能
235.二叉搜索树的最近公共祖先
目标
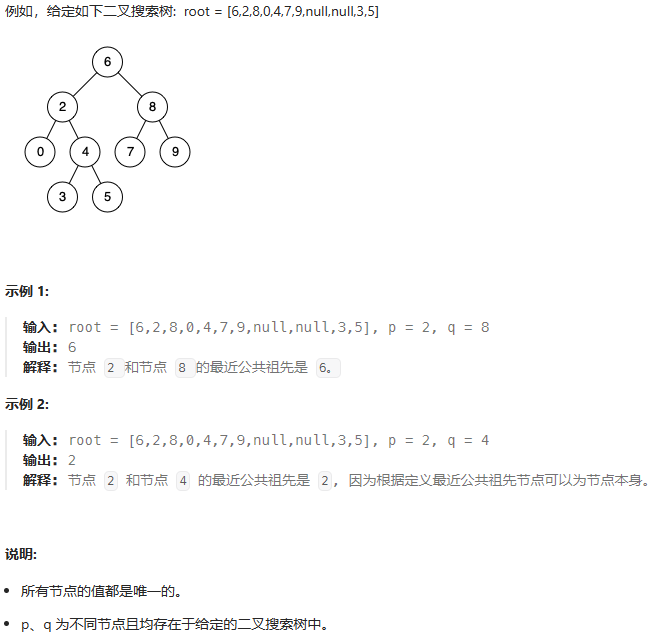
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。
思路
我第一次想到的方法是先找到这两个指定节点,然后交替求取位置索引较大节点的父节点。然后比较,如果值相等则为公共祖先。但是,题目给出的树结构中不包含指向父节点的引用,很自然地想到先将值保存到数组中,中序遍历二叉搜索树得到正序序列。然后二分查找出index,计算父节点index:左孩是奇数index,父index为(child-1)/2,右孩是偶数index,父index为(child-2)/2,注意排除root,index为0。接着比较父节点的值,还应该考虑输入节点本身就是父子关系的情况,如果pindex > qindex,应先求p节点的父index,因为index大,层数可能更高。再与qindex对应的值比较,不相等的话再求q节点的父index,依此类推。题目中有提到,树中的值都是唯一的。这个想法看起来正确,但真正去实现的时候就会发现是不可行的。首先是存储空间问题,要在数组中保留树的结构,在有许多空节点的情况下是不可行的。这个在 二叉搜索树最近节点查询 中提到过。然后是二分查找需要先排序的问题,这本身就打乱了树节点的index关系。
这几天刷题有一个感受,就是如果算法实现起来太过复杂那么一定是有问题的,很有可能是求解的方向不对。
于是我换了一种思路,还是先找到这两个节点,但是在找的过程中记录下访问的路径,然后再找到路径节点中所有相同节点中的最后一个即可。那么路径应该保存到哪里,又如何获取相同节点序列的最后一个呢?
在 Java 的标准库中,java.util.Stack 类是使用数组实现的。然而,从 Java 6 开始,java.util.Stack 类被标记为遗留(legacy),并建议使用 java.util.Deque 接口及其实现(如 ArrayDeque 或 LinkedList)来替代。Deque 接口表示双端队列,它支持在两端插入和删除元素,因此非常适合实现栈和队列。----AI的回答
无论是使用数组还是链表,最后查找的时候,都可以从头开始同时比较,直到第一个不相等节点出现即可。无需额外申请空间。
如果从尾开始比较的话,需要借助HashSet,将其中一个路径序列存入集合,然后循环弹另一个路径栈,第一个在集合中的被弹出元素就是最近的公共祖先。需要额外的空间。有的时候条件反转一下可以简化处理逻辑,而有时则相反!
另外数组长度固定,超过的话就会有重新分配空间的开销。
代码
public TreeNode lowestCommonAncestor_v1(TreeNode root, TreeNode p, TreeNode q) {
Stack<TreeNode> pStack = findPath(root, p.val, new Stack<>());
Stack<TreeNode> qStack = findPath(root, q.val, new Stack<>());
HashSet<Integer> set = new HashSet<>();
while (!pStack.empty()){
set.add(pStack.pop().val);
}
TreeNode res = null;
while (!qStack.empty()){
res = qStack.pop();
if (set.contains(res.val)) {
break;
}
}
return res;
}
public Stack<TreeNode> findPath(TreeNode subRoot, int value, Stack<TreeNode> stack) {
stack.push(subRoot);
if (subRoot.val == value) {
return stack;
} else if (subRoot.val > value) {
return findPath(subRoot.left, value, stack);
} else {
return findPath(subRoot.right, value, stack);
}
}
/**
* 还有一个更好的做法是一次遍历同时比较p,q,如果一个大于等于,一个小于等于 当前节点值,表明已经/准备分叉了
* 这个是看了题解之后发现的
*/
public TreeNode lowestCommonAncestor_v2(TreeNode root, TreeNode p, TreeNode q) {
if (root.val > p.val && root.val > q.val) {
return lowestCommonAncestor_v2(root.left, p, q);
} else if (root.val < p.val && root.val < q.val) {
return lowestCommonAncestor_v2(root.right, p, q);
} else {
return root;
}
}性能
2476.二叉搜索树最近节点查询
目标
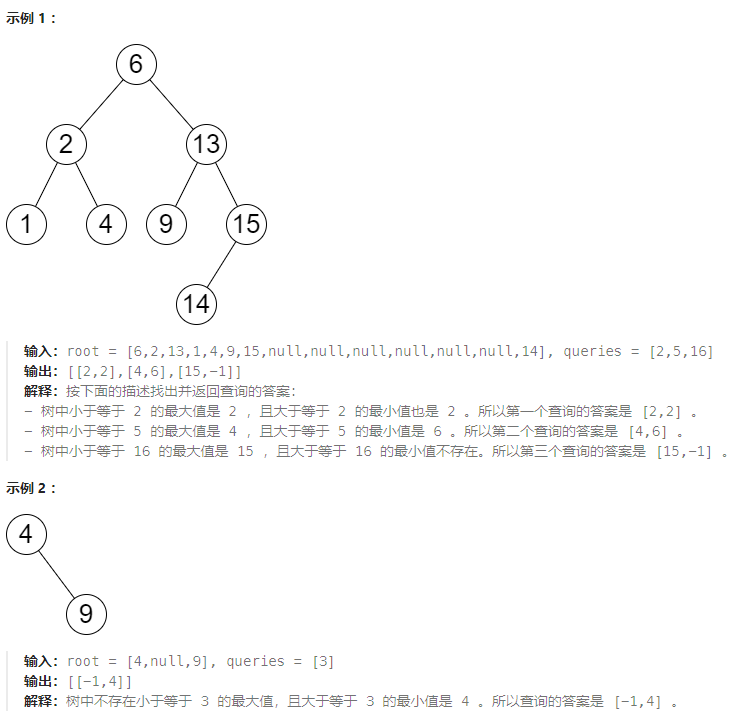
给你一个 二叉搜索树 的根节点 root ,和一个由正整数组成、长度为 n 的数组 queries 。
请你找出一个长度为 n 的 二维 答案数组 answer ,其中 answer[i] = [mini, maxi] :
- mini 是树中小于等于 queries[i] 的 最大值 。如果不存在这样的值,则使用 -1 代替。
- maxi 是树中大于等于 queries[i] 的 最小值 。如果不存在这样的值,则使用 -1 代替。
返回数组 answer 。
说明:
- 树中节点的数目在范围 [2, 10^5] 内
- 1 <= Node.val <= 10^6
- n == queries.length
- 1 <= n <= 10^5
- 1 <= queries[i] <= 10^6
思路
这个题目求的是最接近给定值的节点值。一个朴素的想法是将搜索树的值都列出来,然后从中查找前后的值。这里列出值无需保留树的结构,虽然节点数目范围是[2,10^5],但如果考虑一个极端的情况,树的深度就是10^5-1,保留树的结构就大约需要2^(10^5)约等于10^3010个元素。二叉搜索树如果采用中序遍历结果就是正序的。但是考虑到存在null值,数组可能填不满,这样就破坏了有序性。想要使用二分查找还要先排序。Arrays.binarySearch 的结果如果找到相应的值则返回对应的index>=0。如果没有找到,则返回-insertion point-1。所谓插入点,其前一个位置的值小于搜索的值。例如 arr = [2, 3, 4, 5, 6, 7, 9] 搜索值为8,使用二分查找则返回 -6-1,arr[5]的值是7,8应该插入到7后面,即插入点为6。因此,如果没查询到,可以使用-index-1得到最近的大于搜索值的位置,这里需要注意数组的边界。
代码
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* @date 2024-02-24 18:57
*/
public class ClosestNodes {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
public final int MAX = 100000;
public int[] values = new int[MAX];
public int i = 0;
public List<List<Integer>> closestNodes(TreeNode root, List<Integer> queries) {
Arrays.fill(values, -1);
traverseSubTree(root);
// 遍历之后values并非全部有序,因为存在null节点,没初始化 值为0
Arrays.sort(values);
List<List<Integer>> res = new ArrayList<>(queries.size());
for (Integer query : queries) {
List<Integer> tmp = new ArrayList<>(2);
int ri = Arrays.binarySearch(values, query);
if (ri < 0) {
ri = -ri - 1;
if (ri == values.length) {
tmp.add(values[values.length -1]);
tmp.add(-1);
} else if(ri == 0){
tmp.add(-1);
tmp.add(values[0]);
} else {
tmp.add(values[ri - 1]);
tmp.add(values[ri]);
}
} else {
// 如果存在
tmp.add(values[ri]);
tmp.add(values[ri]);
}
res.add(tmp);
}
return res;
}
public void traverseSubTree(TreeNode subTree) {
if (subTree.left != null) {
traverseSubTree(subTree.left);
}
values[i++] = subTree.val;
if (subTree.right != null) {
traverseSubTree(subTree.right);
}
}
}
性能
2583.二叉树中的第K大层和
目标
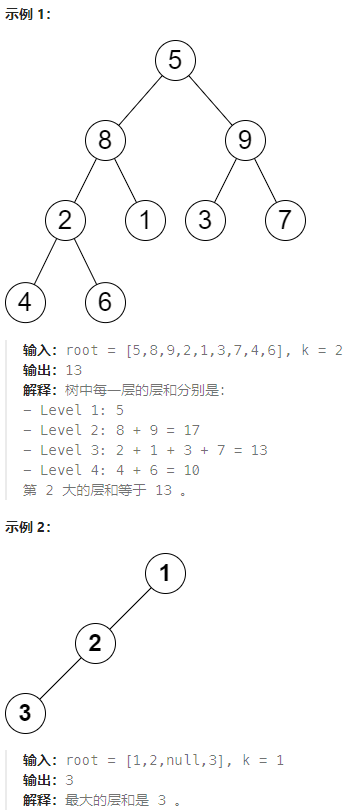
给你一棵二叉树的根节点 root 和一个正整数 k 。
树中的 层和 是指 同一层 上节点值的总和。
返回树中第 k 大的 层和(不一定不同)。如果树少于 k 层,则返回 -1 。
注意,如果两个节点与根节点的距离相同,则认为它们在同一层。
说明:
- 树中的节点数为 n
- 2 <= n <= 10^5
- 1 <= Node.val <= 10^6
- 1 <= k <= n
思路
这个问题的关键在于遍历的同时记录层数并进行累加。由于是升序排列所以取倒数第k个,即MAX-k。
代码
/**
* @date 2024-02-23 16:06
*/
public class KthLargestLevelSum {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
public static void main(String[] args) {
KthLargestLevelSum main = new KthLargestLevelSum();
long res = main.kthLargestLevelSum(new TreeNode(1, new TreeNode(2), new TreeNode(3)), 2);
System.out.println(res);
}
public final int MAX = 100000;
public long[] lacc = new long[MAX];
public int maxlevel = 0;
public long kthLargestLevelSum(TreeNode root, int k) {
traverseSubTree(root, 0);
if (k > maxlevel + 1) {
return -1;
}
Arrays.sort(lacc);
return lacc[MAX-k];
}
public void traverseSubTree(TreeNode subTree, int level) {
maxlevel = Math.max(maxlevel, level);
lacc[level] += subTree.val;
if (subTree.left != null) {
traverseSubTree(subTree.left, level + 1);
}
if (subTree.right != null) {
traverseSubTree(subTree.right, level + 1);
}
}
}Arrays.sort使用的是双轴快排(DualPivotQuicksort),时间复杂度是O(nlogn)。
性能
最优的算法是快速选择。因为我们并不需要所有的元素都有序,只要保证k位置的左侧都比k小,右侧均比k大即可,而两侧区间内部是不需要排序的。
889.从前序与后序遍历序列构造二叉树
目标
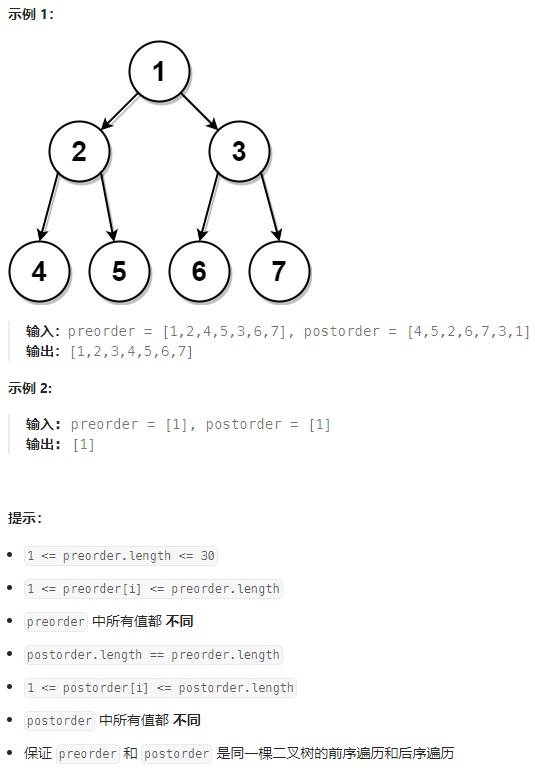
给定两个整数数组,preorder 和 postorder ,其中 preorder 是一个具有 无重复 值的二叉树的前序遍历,postorder 是同一棵树的后序遍历,重构并返回二叉树。
如果存在多个答案,您可以返回其中 任何 一个。
思路
本来看到这个题目觉得没什么新意,前面都已经做过 从前序与中序遍历序列构造二叉树 与 从中序与后序遍历序列构造二叉树这两个题目了,准备快速写一下。没想到,又花费了许多时间。虽然知道大体的方向,但真正写出来还是不那么容易的。对照着一个案例,按照大体思路写完解决方法之后,就急着去测试,结果有的例没有通过,有的数组越界。然后就开始调试,一会这加个判断,那处理一个特例,这个案例通过了,别的又不行了,一来二去就把自己绕晕了。之所以存在这样的情况还是对这个问题的理解不到位,没有一个清晰的思路。
有了前面的两道题的求解经验,我们知道这个题还是用递归求解更容易一些。求解的核心是遍历先序/后序序列,一个从前向后,一个从后向前。将遍历到的每一个节点去中序序列中找到相应位置然后划分左/右子树,然后递归处理子树。其实这里容易忽略一个问题,就是左/子树的节点一定会在先序/后序序列随后遍历中出现。可以根据这个来明确临界条件,否则容易漏掉或者弄错左右以及父节点。这也就是为什么先序序列先遍历左子树,后序先遍历右子树的原因。因为游标顺序移动,刚好可以覆盖相应的子树。刚开始我还想着分别在先序和后序维护两个游标,这是不可行的。
说回到这个题目,它不像前面两个那样可以明确左右子树。前面说前序序列的第二个节点是其左子树或右子树的根节点,并非是无法确定,而是需要结合实际情况看是否存在左子树,如果存在则一定是左子树根节点。这个可以在中序序列中找到相应位置就知道了。但是对于这个题而言左右是无法确定的,很简单的例子 [1,2] 与 [2,1]。
我们的思路是遍历先序序列,找到其在后序序列的位置,该位置减1则是可能的右根节点,反查其在先序序列中的位置。这样我们就得到了一个左子树区间或者单个节点(无法确定左右)。这样我们就可以递归构建左子树,对于单个节点的情况需要将搜索范围扩展到序列结尾,否则可能反查不到节点在先序序列中的位置。
代码
/**
* @date 2024-02-23 10:05
*/
public class BuildBinaryTreeFromPrePost {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
public static int preCursor = 1;
public static void main(String[] args) {
BuildBinaryTreeFromPrePost main = new BuildBinaryTreeFromPrePost();
// int[] preorder = new int[]{1,2,4,5,3,6,7};
// int[] preorder = new int[]{3, 9, 20, 15, 7};
// int[] preorder = new int[]{1,2};
// int[] preorder = new int[]{2,1,3};
// int[] preorder = new int[]{4,2,1,3};
int[] preorder = new int[]{3,4,2,1};
// int[] preorder = new int[]{1};
// int[] postorder = new int[]{4,5,2,6,7,3,1};
// int[] postorder = new int[]{1};
// int[] postorder = new int[]{9, 15, 7, 20, 3};
// int[] postorder = new int[]{2,1};
// int[] postorder = new int[]{3,1,2};
// int[] postorder = new int[]{3,1,2,4};
int[] postorder = new int[]{2,1,4,3};
System.out.println(main.constructFromPrePost(preorder, postorder));
}
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
TreeNode root = new TreeNode(preorder[0]);
if (preorder.length == 1) {
return root;
}
int rightRootPreIndex = 0;
for (int i = 0; i < preorder.length; i++) {
if (postorder[postorder.length - 2] == preorder[i]){
rightRootPreIndex = i;
break;
}
}
// 注意当start == end时,搜索长度应扩展到整个数组长度,否则会导致查询不到当前节点的右子树根节点。
root.left = buildSubTree(preorder, postorder, preCursor, rightRootPreIndex == preCursor ? preorder.length:rightRootPreIndex);
if (preCursor >= rightRootPreIndex && preCursor < preorder.length) {
root.right = buildSubTree(preorder, postorder, rightRootPreIndex, preorder.length);
}
return root;
}
public TreeNode buildSubTree(int[] preorder, int[] postorder, int start, int end){
TreeNode root = new TreeNode(preorder[preCursor]);
int rightRootPostIndex = 0;
int rightRootPreIndex = 0;
for (int i = 0; i < postorder.length; i++) {
if (root.val == postorder[i]){
rightRootPostIndex = i;
preCursor++;
break;
}
}
if (rightRootPostIndex > 0) {
for (int i = start; i < end; i++) {
if (postorder[rightRootPostIndex - 1] == preorder[i]) {
rightRootPreIndex = i;
break;
}
}
if (preCursor < rightRootPreIndex) {
root.left = buildSubTree(preorder, postorder, preCursor, rightRootPreIndex == 0 ? preorder.length : rightRootPreIndex);
}
if (preCursor >= rightRootPreIndex && preCursor < end && rightRootPreIndex !=0) {
root.right = buildSubTree(preorder, postorder, rightRootPreIndex, end);
}
}
return root;
}
}先序序列的初始条件是直接从第二个位置开始的,直接从后序序列的倒数第二个反查其在先序序列的位置。
性能
LCP24.数字游戏
目标
小扣在秋日市集入口处发现了一个数字游戏。主办方共有 N 个计数器,计数器编号为 0 ~ N-1。每个计数器上分别显示了一个数字,小扣按计数器编号升序将所显示的数字记于数组 nums。每个计数器上有两个按钮,分别可以实现将显示数字加一或减一。小扣每一次操作可以选择一个计数器,按下加一或减一按钮。
主办方请小扣回答出一个长度为 N 的数组,第 i 个元素(0 <= i < N)表示将 0~i 号计数器 初始 所示数字操作成满足所有条件 nums[a]+1 == nums[a+1],(0 <= a < i) 的最小操作数。回答正确方可进入秋日市集。
由于答案可能很大,请将每个最小操作数对 1,000,000,007 取余。

思路
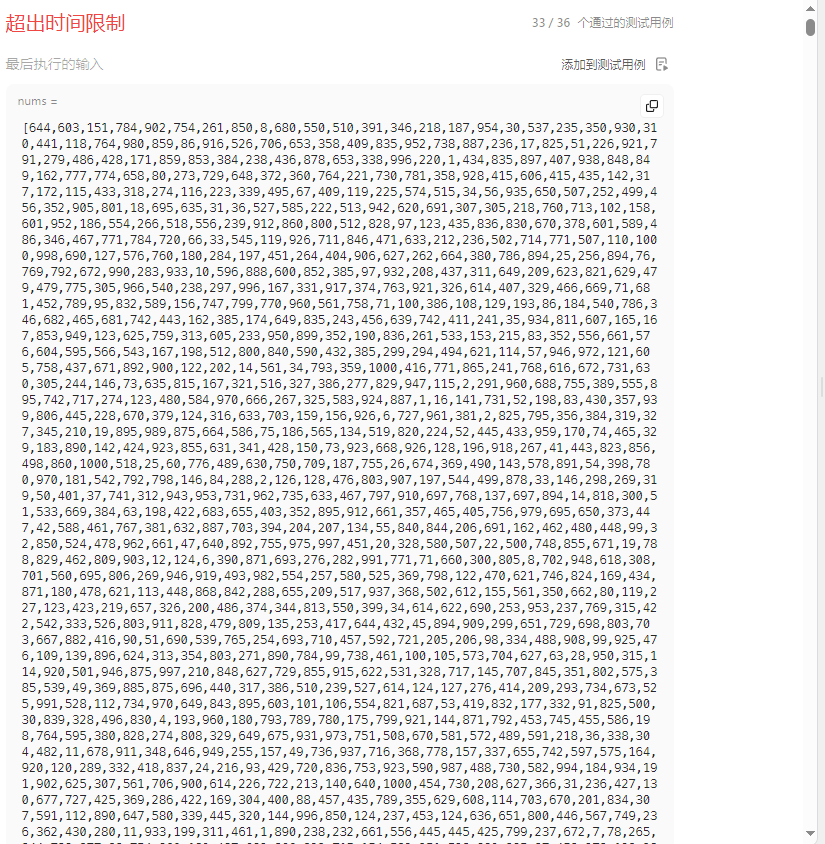
老实说这道题我花了好一会儿才弄清楚题目要求,最后解法还因为超时没有通过。
先解释一下目标吧,实际上需要求解的是每一个位置上的局部最优解。所谓局部指仅考虑当前位置及之前的所有位置的操作次数。所谓最优是指初始序列达到满足条件的状态(公差为1的等差数列)时所做操作总和的最小值。如果有N个计数器,那么就有N个满足条件的序列,有可能前面操作最少的序列并不是后面操作最少的序列,即前面位置的总操作次数可能并不是当前最优解的一部分。可以参考上面图片的示例3。
我的思路就是直接暴力破解,循环遍历输入的数组,在第i次遍历中,分别将(0 ~ i-1)位置上的元素作为基点k,左侧的序列依次减1,右侧的依次加1。在第k个序列中求解(0 ~ i-1)位置上操作次数的累加和。在第j个位置上的操作次数为 nums[k]-(k-j)。
代码
public static int[] numsGame2(int[] nums) {
int[] res = new int[nums.length];
// 累加k序列的操作总和
int[] acc = new int[nums.length];
for (int i = 1; i < nums.length; i++) {
for (int k = 0; k <= i; k++) {
int temp = acc[k];
// 增加一些判断跳过一些计算
if(temp >= res[i] && res[i] != 0){
continue;
}
// 这里看似套了3个循环,但其实只有在k序列第一次出现时才会循环i次,那么前面的i-1次只需从acc中累计即可,实际时间复杂度是O(n^2)
for (int j = temp == 0 ? 0 : i; j <= i; j++) {
temp += Math.abs(nums[j] - (nums[k] - (k - j)));
}
acc[k] = temp;
if (k == 0) {
res[i] = temp;
} else {
res[i] = Math.min(res[i], temp);
}
}
res[i] = res[i] % 1000000007;
}
return res;
}| acc | a | b | c | d |
|---|---|---|---|---|
| acc[0] | 0 | |b-a-1| | |c-a-2| | |d-a-3\ |
| acc[1] | |a-b+1| | 0 | |c-b-1| | |d-b-2\ |
| acc[2] | |a-c+2| | |b-c+1| | 0 | |d-c-1\ |
| acc[3] | |a-d+3| | |b-d+2| | |c-d+1| | 0 |
如上表所示,如果序列是[a,b,c,d],基点k等于c的时候,前2次从acc累加,最后一次需要重新累加。时间复杂度为O(n^2)。这和我们常见的外层循环N次,内层循环N次不同。循环的计算次数序列为1、3、5、7...,根据等差数列求和公式:Sn = n × a1 + (n × (n-1)/2) × d,当 d=2,a1=1 时,Sn = n^2。
性能
由于题目给出的数组最大长度是10^5,暴力求解是不可行的。也尝试了增加条件判断跳过一些计算但还是无法降低问题的规模。于是就开始怀疑是否前面的计算结果是否与后面的计算有关联,可以简化后面的计算?更优的算法复杂度应为O(nlogn)、O(logn) 和 O(n)。我思考了很久,应该是存在知识盲区了。我去看了答案,涉及到求中位数。其实一开始有想过中位数,方差均值这些,但是没想到和这个最优解有什么关系。今天没时间了,抽空再看看吧。
106.从中序与后序遍历序列构造二叉树
目标
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
思路
有了前面 从前序与中序遍历序列构造二叉树 的经验这个问题就很好处理了。二叉树的后序遍历指先访问左子树、再访问右子树,最后访问根节点。
只需从后序序列的最后一个元素向前遍历即可,最后一个是根节点,接着是右子树、左子树的根节点 (注意这里是先右后左)。
还是在中序遍历中找到该根节点,然后其左侧的为左子树,右侧为右子树。依次递归遍历右子树与左子树,在递归方法中根节点取后序序列的前一个节点即可。
代码
/**
* @date 2024-02-21 14:12
*/
public class BuildBinaryTreeFromMidPost {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
// static int[] inorder = new int[]{9, 3, 15, 20, 7};
static int[] inorder = new int[]{2,3,1};
// static int[] inorder = new int[]{-1};
// static int[] postorder = new int[]{9, 15, 7, 20, 3};
static int[] postorder = new int[]{3,2,1};
// static int[] postorder = new int[]{-1};
static int postCursor = postorder.length - 1;
public static void main(String[] args) {
int rootIndex = 0;
TreeNode root = new TreeNode(postorder[postCursor]);
for (int i = 0; i < inorder.length; i++) {
if (inorder[i] == postorder[postCursor]) {
rootIndex = i;
// 一定能够找到
postCursor--;
break;
}
}
int leftEndIndex = rootIndex - 1;
int rightStartIndex = rootIndex + 1;
// 注意这个postCursor应该是共享变量,原先是想以参数传递的,但是发现递归的时候还要将它传回来,改成了共享变量
// 这里是先遍历右子树再左子树
if (rightStartIndex < inorder.length) {
root.right = traverseSubTree(inorder, rightStartIndex, inorder.length);
}
if (leftEndIndex >= 0) {
root.left = traverseSubTree(inorder, 0, leftEndIndex);
}
System.out.println(root);
}
public static TreeNode traverseSubTree(int[] inorder, int start, int end) {
TreeNode subRoot = new TreeNode(postorder[postCursor]);
int rootIndex = start;
for (int i = start; i <= end; i++) {
if (inorder[i] == postorder[postCursor]) {
rootIndex = i;
postCursor--;
break;
}
}
int leftEndIndex = rootIndex - 1;
int rightStartIndex = rootIndex + 1;
// 临界条件判断,这里应该是<=,并且排除掉inorder.length
// 这里是先遍历右子树再左子树
if (rightStartIndex <= end && rightStartIndex != inorder.length) {
// 这里的结束条件传end
subRoot.right = traverseSubTree(inorder, rightStartIndex, end);
}
if (leftEndIndex >= start) {
subRoot.left = traverseSubTree(inorder, start, leftEndIndex);
}
return subRoot;
}
}
性能
105.从前序与中序遍历序列构造二叉树
目标
给定两个整数数组 preorder 和 inorder,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
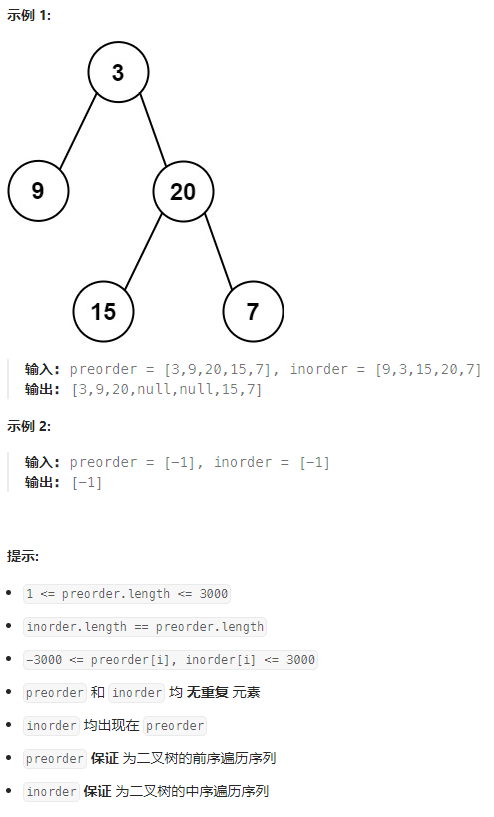
思路
首先要明白先序遍历与中序遍历的概念。所谓二叉树的 先序遍历 指的是 先访问根节点,然后遍历左子树,再遍历右子树。中序遍历 则是 先遍历左子树,再根节点,然后右子树。
很容易想到使用递归,关键点是数组左右边界的维护,临界条件的判断。
注意到 先序遍历数组的第一个节点一定是根节点,其后面的节点则是其左子树或右子树的根节点。
于是先根据根节点在中序遍历中找到该根节点,然后其左侧的为左子树,右侧为右子树。依次递归遍历左子树与右子树(注意判断边界条件),在递归方法中根节点取刚才根节点的后一个节点(需要一个共享变量来记录位置)。
代码
/**
* @date 2024-02-20 11:43
*/
public class BuildBinaryTree {
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
@Override
public String toString() {
return "TreeNode{" +
"val=" + val +
", left=" + left +
", right=" + right +
'}';
}
}
static int[] preorder = new int[]{3, 9, 20, 15, 7};
// static int[] preorder = new int[]{1,2,3};
// static int[] preorder = new int[]{-1};
static int[] inorder = new int[]{9, 3, 15, 20, 7};
// static int[] inorder = new int[]{2,3,1};
// static int[] inorder = new int[]{-1};
static int preCursor = 0;
public static void main(String[] args) {
int rootIndex = 0;
TreeNode root = new TreeNode(preorder[preCursor]);
for (int i = 0; i < inorder.length; i++) {
if (inorder[i] == preorder[preCursor]) {
rootIndex = i;
// 一定能够找到
preCursor++;
break;
}
}
int leftEndIndex = rootIndex - 1;
int rightStartIndex = rootIndex + 1;
if (leftEndIndex >= 0) {
root.left = traverseSubTree(inorder, 0, leftEndIndex);
}
// 注意这个preCursor应该是共享变量
if (rightStartIndex < inorder.length) {
root.right = traverseSubTree(inorder, rightStartIndex, inorder.length);
}
System.out.println(root);
}
public static TreeNode traverseSubTree(int[] inorder, int start, int end) {
TreeNode subRoot = new TreeNode(preorder[preCursor]);
int rootIndex = start;
for (int i = start; i <= end; i++) {
if (inorder[i] == preorder[preCursor]) {
rootIndex = i;
preCursor++;
break;
}
}
int leftEndIndex = rootIndex - 1;
int rightStartIndex = rootIndex + 1;
if (leftEndIndex >= start) {
subRoot.left = traverseSubTree(inorder, start, leftEndIndex);
}
// 临界条件判断,这里应该是<=,并且排除掉inorder.length
if (rightStartIndex <= end && rightStartIndex != inorder.length) {
// 这里的结束条件传end
subRoot.right = traverseSubTree(inorder, rightStartIndex, end);
}
return subRoot;
}
}
性能
我的目标是能解决问题就好,看了下性能分布还有优化的空间,官网还给出了迭代的解法,没时间看。递归应该是更容易理解的方法了。希望能够坚持下去吧。